Web scraping Facebook can bring fortunes as this platform contains a massive amount of public domain information. It’s often used for commercial reasons by Meta itself. But how can one extract what’s needed, and use this data for profit? It’s possible if you master web scraping Facebook.
In this short guide you will see the basics of web scraping Facebook using Python environment and GoLogin browser as your scraper protection tool.
Read some more useful content on this topic:
Scraping LinkedIn: Pro Scraper’s Guide + Code
Scraping Reddit: Pro Scraper’s Guide + Code
Scraping Twitter: Pro Scraper’s Guide + Code
Scraping Youtube: Pro Scraper’s Guide + Code

How to make use of web scraping Facebook?
Scraping Facebook data can be useful for both businesses and researchers for various reasons:
- Market research: Due to its massive user base, Facebook is a useful tool for firms looking to conduct market research. Businesses can learn more about client behavior, interests, and preferences by scraping Facebook data. Businesses might use this data to identify new markets, develop new products or services, or launch focused marketing campaigns.
- Competitor analysis: Businesses can utilize Facebook data scraping tools to research their competition. Businesses can learn what works and what doesn’t in their industry by examining the social media strategies of their rivals. Additionally, they can spot weaknesses in the product lines of their rivals and create plans to take advantage of these weaknesses.
- Social media analytics: Facebook data scraping can be used to monitor social media engagement and to analyze trends in user behavior. This can help businesses understand how users are interacting with their brand on social media and identify areas for improvement. It can also help researchers understand how social media is used and its impact on society.
- Academic research: Collecting data from Facebook, researchers can study various aspects of human behavior, such as political opinions, social networks, and the spread of misinformation. This data can be used to better understand how the social media platform affects society, and to develop strategies to counter the negative effects of social media.
- Public opinion monitoring: By scraping Facebook data, businesses and researchers can monitor public opinion on various topics, such as politics, social issues, and consumer preferences. This information can be used to develop more effective marketing campaigns or to identify potential areas of concern for the public.
Legal and ethical considerations of web scraping Facebook data
Facebook data scraping can pose a number of ethical and legal questions. First of all, it’s crucial to remember that Facebook’s terms of service forbid using automated techniques (even public data), such as web scraping, without Facebook’s express consent. These terms of service violations may lead to account suspension or termination, legal action, and potential reputational harm to a business.
Scraping Facebook post data without user permission can also cause privacy issues. Facebook users’ privacy rights may be violated if they are unaware that their data is being gathered and exploited. It’s crucial to collect data and use it in compliance with privacy laws and regulations, such as GDPR or CCPA, and that the data is anonymized or pseudonymized to protect user privacy.
Nuances of Scraping for Commercial Reasons
Businesses and researchers must also make sure that the data that has been scraped is used ethically and responsibly. For instance, it is immoral and maybe against the law to use data that has been scraped for discriminatory purposes, such as excluding or targeting particular groups based on their ethnicity or gender.
Businesses and researchers should also take steps to assure the accuracy and integrity of the data because scraping errors and inconsistencies might result in findings that are misleading or wrong.
In conclusion, companies and researchers must make sure that online scraping Facebook data is done in accordance with legal and ethical norms. This includes gaining consent where appropriate, respecting user privacy, and using the data responsibly and ethically.
Using GoLogin for Web Scraping Facebook
Have you ever attempted to scrape data from a website protected by anti-bot measures? The truth is, most modern websites won’t let you do that. It might be seriously annoying. Fortunately, there are tools to deal with that, and one of them is GoLogin.
By simulating a genuine user’s surfing habits, this application makes it far more difficult for websites to identify you as a bot. With the help of this effective tool, you can easily gather the data you require while avoiding detection by anti-scraping trackers. In this post, we’ll examine GoLogin’s capabilities in more detail and discuss step by step how it can assist you in overcoming web scraping’s difficulties.
Installing and Setting up GoLogin
Here are the steps to install and set up GoLogin:
- Download GoLogin from the website: the OS will be chosen automatically.
- Open the downloaded file and follow the given steps to install the software on your device.
- After installation, launch GoLogin and create a new account by clicking on the “Sign Up” button. Fill in your details and click on the “Create Account” button. Use Google Auth if it fits.
- Once you have created your account, log in to GoLogin using your credentials.
- On the main dashboard, click on the “Create Profile” button to create a new profile. A profile is a set of browser settings and configurations that you can use for different tasks.
- Fill in the details for the profile, such as the browser type, user agent, screen size, and location. You can also choose to add extensions and plugins. Keep to automatic settings if you’re an unexperienced user.
- Click on the “Proxy” tab and follow the prompts to configure your proxy settings.
- Once your proxy settings are configured, you can use GoLogin with other applications by entering the proxy address and port number.
That’s it! You are now ready to use GoLogin for your web automation tasks.
Setting up the Python Environment
Setting up a Python environment can be broken down into a few simple steps:
- Download and install python on your device from the official website of python. Make sure to download the correct version of python according to your operating system.
- Install code editor like Visual Studio Code, Pycharm, and Sublime text to write python programs.
- Install the required package and libraries required for your project. To install any package
you can run the command pip install <package-name> on the command prompt. - Set up a virtual environment. However, you can code in python even without a virtual environment. However, setting up a virtual environment is considered a good practice because this ensures that each project has its own dependencies and packages, which helps avoid conflicts between projects.
Python libraries for web scraping Facebook
- selenium: a library for automating web browsers. It can be used to simulate user actions like clicking, typing, and scrolling.
- webdriver: a module within Selenium that provides a way to interact with a specific browser (e.g., Chrome, Firefox, etc.) through code.
- By: a module within Selenium that provides ways to locate elements on a webpage (e.g., by ID, class, name, etc.).
- Keys: a module within Selenium that provides special keys that can be used in combination with other actions (e.g., sending a “return” key after typing in a search box).
- time: a module in Python for working with time-related functions. Here, we use **sleep** from this module to introduce a delay in the code to give the webpage enough time to load.
- getpass: a module in Python for getting user input without displaying the input on the screen. It can be used for getting passwords or other sensitive information.
pandas: a library for data manipulation and analysis in Python. It can be used to read and write data to various file formats (e.g., CSV, Excel, SQL), perform calculations, and create visualizations.
python import selenium from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from time import sleep import getpass import pandas as pd
Creating a Facebook scraper using Python
Opening Facebook in Chrome Browser
This code sets the path to the ChromeDriver executable, creates a new Chrome WebDriver instance, navigates to the Facebook homepage, and maximizes the browser window.
python
PATH = "C:\Program Files\drivers\chromedriver_103.exe"
driver = webdriver.Chrome(PATH)
driver.get("https://www.facebook.com/")
driver.maximize_window()
Entering login credentials
This code prompts the user to enter their email ID, retrieves their password in a secure manner using the getpass module, finds the username field on the webpage using an XPath expression, and enters the user’s email ID into the field.
python loginId = "put ur email id"#write email id my_password = getpass.getpass() user_name = driver.find_element(By.XPATH,"//input[@type='text']") user_name.send_keys(loginId)
Entering password and clicking login button
This code finds the password field on the webpage using an XPath expression, enters the user’s password using the send_key method, finds the login button on the page using an XPath expression, and clicks the button using the click method. This completes the login process.
python password = driver.find_element(By.XPATH,"//input[@placeholder='Password']") password.send_keys(my_password) log_in_button = driver.find_element(By.XPATH,"//button[@type='submit']") log_in_button.click()
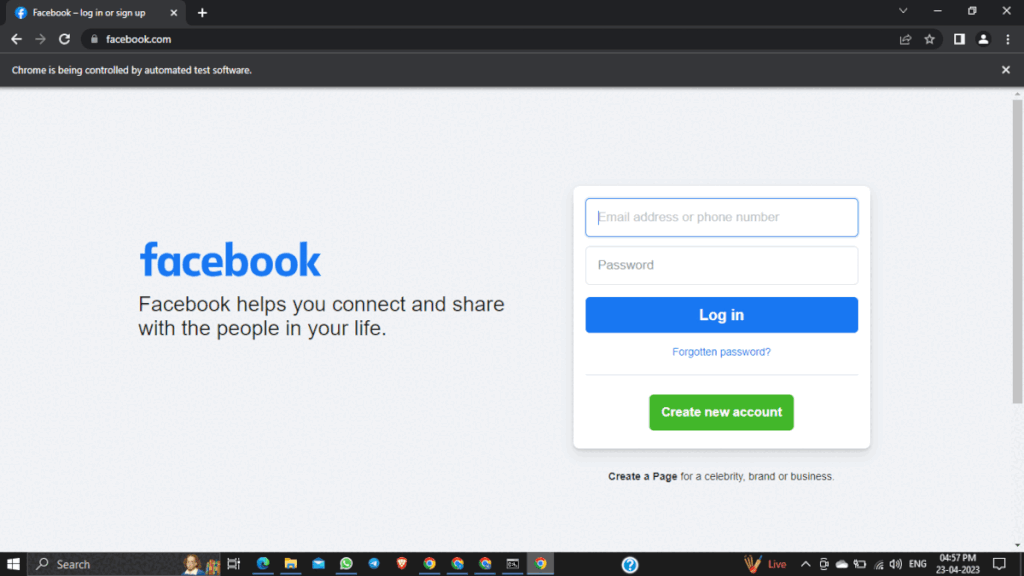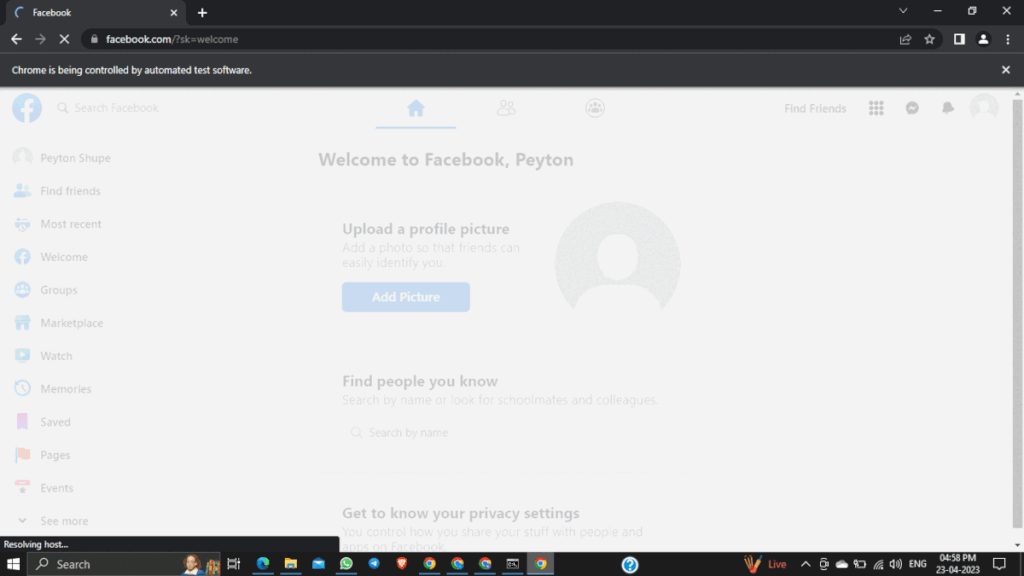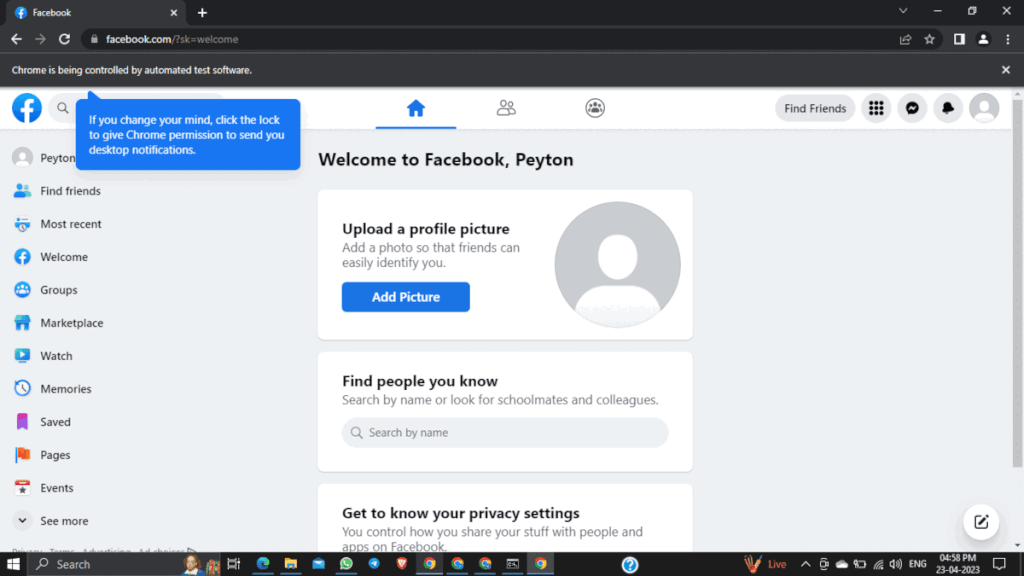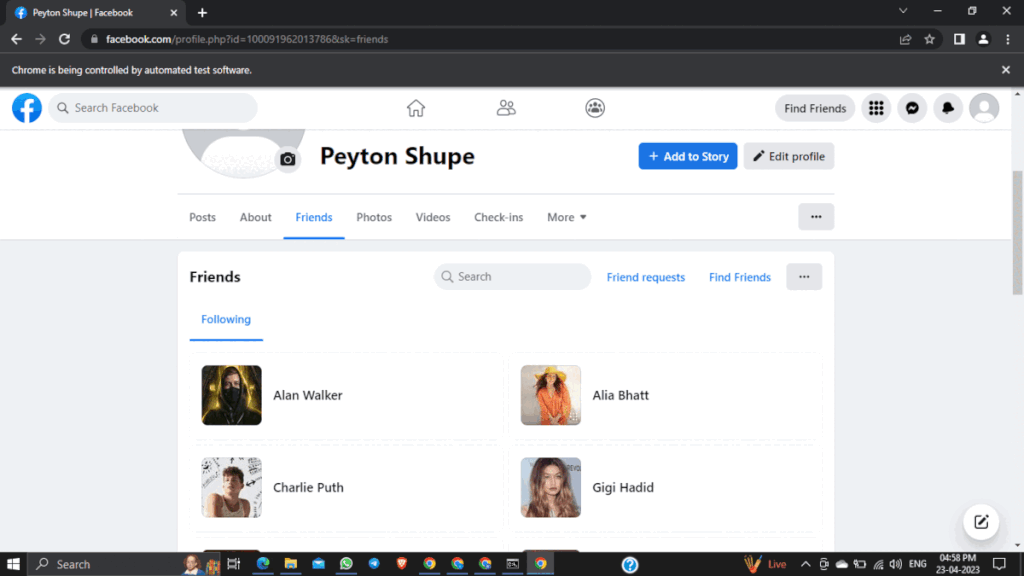
Navigating to the Friends tab
This code finds the “account name” element on the webpage using an XPath expression and clicks it to access the user’s profile. It then waits for 3 seconds using the sleep method before finding the “Friends” tab on the page using an XPath expression and clicking it to navigate to the Friends page.
python my_profile = driver.find_element(By.XPATH,"//span[text()='Write Your account name']")#write ur account name my_profile.click() sleep(3) friendsTab = driver.find_element(By.XPATH,"//span[text()='Friends']") friendsTab.click() sleep(3)
Retrieving the user’s friend list
This code initializes an empty set to store the user’s friends, finds all the elements on the page that match the XPath expression //div[@class=’x1iyjqo2 x1pi30zi’], iterates over each element, extracts the text content of the element using the text attribute, and adds it to the friendsList set. Finally, the code outputs the friendsList set containing the user’s friend names.
python friendsList = set() my_friend = driver.find_elements(By.XPATH,"//div[@class='x1iyjqo2 x1pi30zi']") for friend in my_friend: friendsList.add(friend.text) len(friendsList) friendsList

Storing and analyzing scraped Facebook data
It is crucial to select an appropriate storage option, such as a database or cloud-based storage, in order to store and analyse scraped data properly. While employing visualisation tools and conducting sentiment analysis can assist find patterns and trends in the data, defining a data structure helps assure consistency and make analysis simpler.
Techniques for machine learning can also be used to forecast user behaviour or spot trends. When engaging in web scraping operations, it’s crucial to follow Facebook’s terms of service and preserve user privacy. These recommendations will help you get the most out of your scraped Facebook data.
python df = pd.DataFrame(friendsList,columns=['names'])
Handling Facebook’s login and authentication using GoLogin
- Create a GoLogin account and set up a browser profile. Use residential or mobile proxies.
- Use the GoLogin API to access the Facebook site in a GoLogin browser window.
- Enter login credentials for the Facebook account.
- Once logged in, the user can access the Facebook site and perform any desired actions.
python
from gologin import GoLogin
# Create a new GoLogin instance
gl = GoLogin(api_url='https://api.gologin.com', api_key='YOUR_API_KEY')
# Set up a browser profile for Facebook
gl.create_profile('facebook', browser='chrome')
# Log in to Facebook using GoLogin
session = gl.login('facebook', 'https://www.facebook.com/', username='YOUR_USERNAME', password='YOUR_PASSWORD')
# Navigate to the Friends page
friends_url = 'https://www.facebook.com/YOUR_USERNAME/friends'
session.driver.get(friends_url)
# Extract the user's friend list
friends = session.driver.find_elements_by_xpath("//div[@class='fsl fwb fcb']")
for friend in friends:
print(friend.text)
# Close the session
session.close()
In this code, we first create a new GoLogin instance and set up a browser profile for Facebook using the create_profile method. We then use the login method to log in to Facebook, specifying the login credentials for the user’s account.
Once logged in, we navigate to the Friends page and start extracting data from the user’s friend list using the find_elements_by_xpath method. Finally, we print out the friend names and close the session using the close method. You can scrape a post url, media url and basically any Facebook page content.
Note that the api_key parameter in the GoLogin constructor should be replaced with your actual API key, which can be obtained from GoLogin settings. Additionally, the username and password parameters in the login method should be replaced with the actual login credentials for the user’s Facebook account.

Tips for optimizing web scraping Facebook performance and avoiding detection
- Use effective web scraping methods. Use asynchronous programming techniques like asyncio or multi-threading to speed up the scraping process and avoid downloading unneeded resources like photos and stylesheets.
- Limit the frequency and volume of requests. To lessen the stress on the website’s servers and prevent being discovered, use a delay between requests and set a limit on the number of requests per minute.
- Watch for signals of discovery, such as rate limitation, captchas, or IP address banning, while keeping an eye on the scraping process. To prevent being discovered, alter the scraping behaviour accordingly.
- Use GoLogin to protect your scrapers from anti-bot measures. It is a web automation solution that provides features like rotating proxies, genuine user agents and headers, headless surfing, and automatic CAPTCHA solving. It’s quite hard to scrape publicly. GoLogin makes it simple to create and maintain several browser profiles, automate time-consuming chores, and stay clear of legal problems associated with web scraping. Compared to most modern dedicated scraping APIs, GoLogin comes out cheaper and more effective.
Overall, using Python and GoLogin for web scraping Facebook pages can help extract valuable insights and information from the web more efficiently and securely, while adhering to ethical and legal standards.
FAQ
Is it possible to web scrape Facebook?
Facebook scraping is technically easy and legal as a concept. As a private company, Facebook applies its own Terms of Service against scraping their website without their explicit permission.
Facebook also applies high-level anti-bot measures to prevent scraping and data extraction. Violating these terms can result in account suspension.
Is scraping Facebook Marketplace legal?
Scraping Facebook Marketplace is legal according to US and international laws, but it is a violation of Facebook’s Terms of Service – remember it is a private company able to set any terms for their platform.
Can I scrape Facebook with Python?
Yes. It is recommended to respect the terms and conditions of the platform to avoid legal consequences and account suspension. We also advise you to never go for the data that’s not public domain.
How do I scrape Facebook with Scrapy?
- Install Scrapy via pip and create a new Scrapy project with command-line tool.
- Define the Spider: Inside your project directory, create a new Python file and define a Spider class. This class will contain the scraping logic.
- Configure the settings: Customize the settings for your Scrapy project, such as user-agent, pipelines, and middlewares. Use GoLogin for your scraper protection.
- Run the Spider: Use the Scrapy command-line tool to run your spider.
How do you make a Facebook scraper?
This depends on your needs, resources and goals. You can build, find open source Python scrapers and even buy ready made solutions for enthusiast or minor entrepreneur use. For bigger business needs, more sophisticated and expensive anti-bot solutions will be needed.
It is important to respect the terms and conditions of the platforms you interact with and obtain data through authorized means.
Download GoLogin and enjoy safe web scraping Facebook with our free plan!
References to sources:
- Mancosu M., Vegetti F. What you can scrape and what is right to scrape: A proposal for a tool to collect public Facebook data //Social Media+ Society. – 2020. – Т. 6. – №. 3. – С. 2056305120940703.
- Dewi L. C. et al. Social media web scraping using social media developers API and regex //Procedia Computer Science. – 2019. – Т. 157. – С. 444-449.
- Alzahrani A., Sadaoui S. Scraping and preprocessing commercial auction data for fraud classification //arXiv preprint arXiv:1806.00656. – 2018.
- Huerta-Cepas J., Dopazo J., Gabaldón T. ETE: a python Environment for Tree Exploration //BMC bioinformatics. – 2010. – Т. 11. – С. 1-7.
- Millman K. J., Aivazis M. Python for scientists and engineers //Computing in science & engineering. – 2011. – Т. 13. – №. 2. – С. 9-12.
- Markovikj D. et al. Mining facebook data for predictive personality modeling //Proceedings of the International AAAI Conference on Web and Social Media. – 2013. – Т. 7. – №. 2. – С. 23-26.


