This article has been edited and updated in January 2025.
X (Twitter) is a popular social media platform with valuable data that can be extracted for various purposes. However, web scraping Twitter for data can be challenging due to its anti-scraping measures.
In this guide, we will discuss how to scrape Twitter data using Python and GoLogin multi accounting browser, which can bypass Twitter’s anti-scraping measures. Also read, how you can run Multiple Twitter Accounts with GoLogin.

Understanding Twitter’s Anti-Scraping Measures
Twitter’s anti-scraping safeguards are essential for preserving the platform’s integrity and safeguarding users’ privacy. These controls are meant to stop automated software programmes, or “bots,” from gathering a lot of information from Twitter profiles without the users’ permission.
As part of its anti-scraping strategy, Twitter has implemented a number of measures, including rate-limiting API requests, identifying and blocking suspicious activity, and using CAPTCHAs to confirm users’ identities. While some users who are curious about web scraping Twitter to collect data may find these precautions inconvenient, they are important to protect the platform’s safety and security.

Introduction to GoLogin
Have you ever attempted to scrape data from a website but been unable due to anti-scraping protections? When you try to acquire information but the website won’t let you, it might be annoying. GoLogin privacy browser can help in this situation.
By creating unique browser fingerprints, this application makes it almost impossible for websites to identify your web scraper. With the help of this effective tool, you can easily gather the data you require while getting beyond anti-scraping safeguards. In this post, we’ll examine GoLogin’s capabilities in detail, try web scraping Twitter with it and discuss how GoLogin can assist you in overcoming web scraping’s difficulties.
Installing and Setting up GoLogin
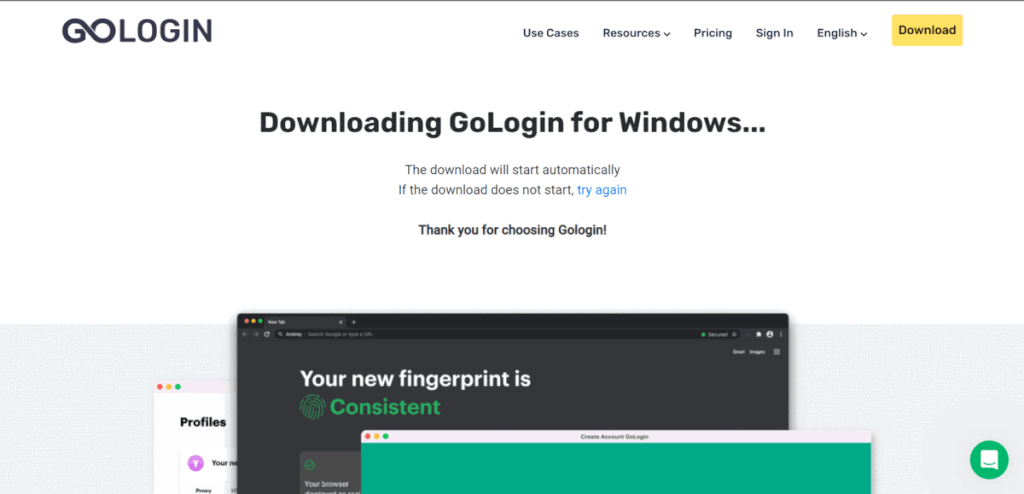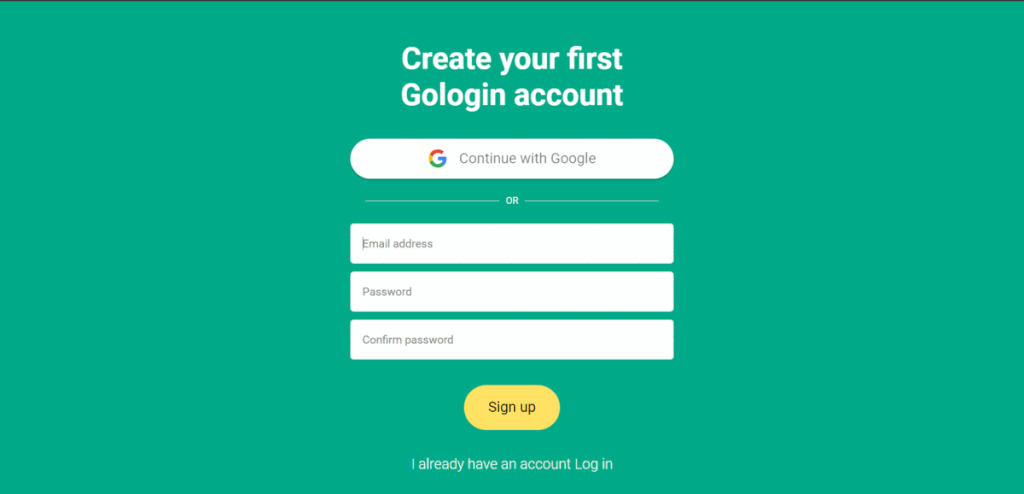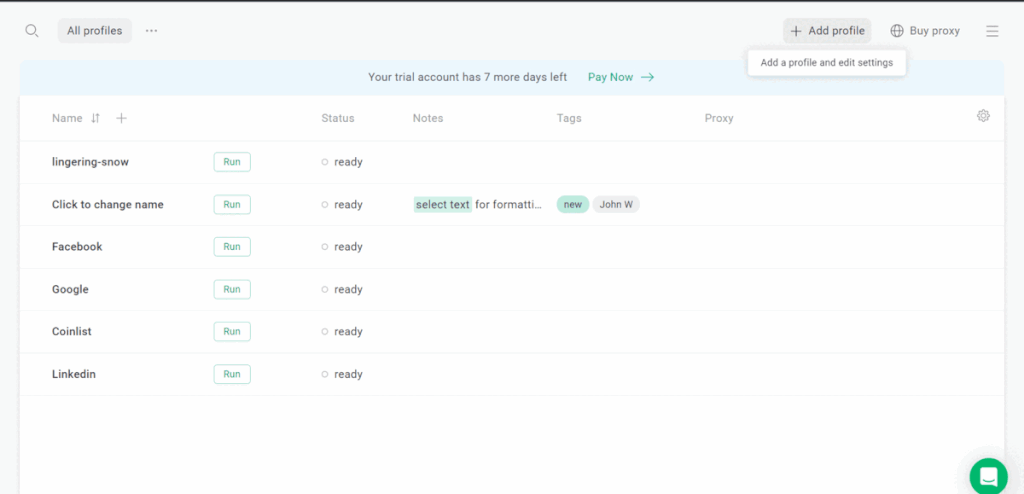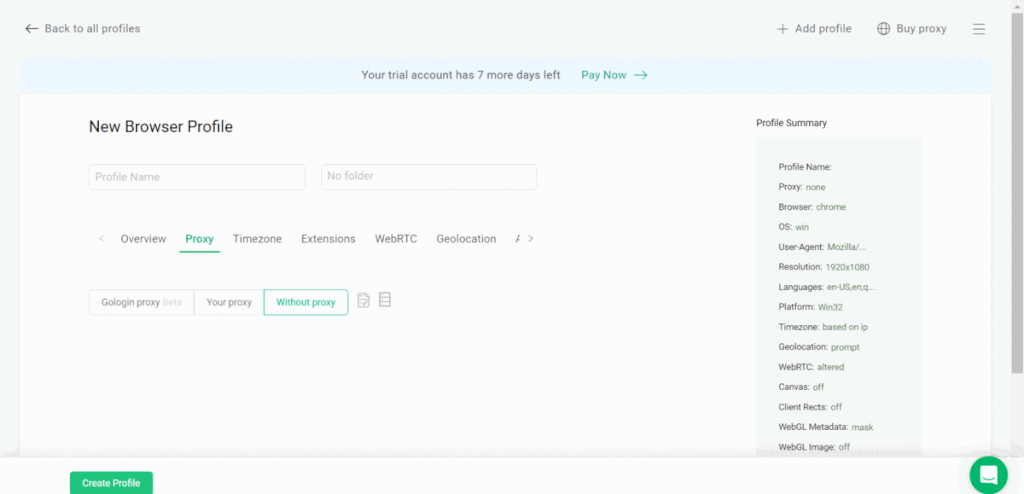 Here are the steps to install and set up GoLogin:
Here are the steps to install and set up GoLogin:
- Go to the GoLogin official website and click download to start downloading the GoLogin software for your OS. Install the app.
- Launch GoLogin and create a new account by clicking on the “Sign Up” button. You can sigh in via Google or fill in your details and click on the “Create Account” button.
- On the main dashboard, click on the “Create Profile” button to create a new profile. A profile is a set of browser settings and configurations that you can use for different tasks. You can also use a + icon on your top left for a quick profile with automatic settings.
- Fill in the settings for the new profile: OS, browser type, proxy, screen size, and location. You can also choose to add extensions and plugins. Keep to GoLogin’s recommended settings: parameters changed at will may affect performance.
- To use GoLogin with other applications, you will need to set up a proxy connection. Click on the “Proxy” tab and follow the prompts to configure your proxy settings.
- Once your proxy settings are configured, you can use GoLogin with other applications by entering the proxy address and port number.
- You can now Run your profile to perform tasks such as web scraping, social media management, and automation. New browser windows will open: that’s where you operate like in a regular browser.
That’s it! You are now ready to use GoLogin for your web automation tasks.
Setting up the Python Environment
Setting up a Python environment can be broken down into a few simple steps:
- Download and install python on your device from the official website of python. Make sure to download the correct version of python according to your operating system.
- Install code editor like Visual Studio Code, Pycharm, and Sublime text to write python programs.
- Install the required package and libraries required for your project. To install any package
you can run the command pip install <package-name> on the command prompt. - Set up a virtual environment. However, you can code in python even without a virtual environment. However, setting up a virtual environment is considered a good practice because this ensures that each project has its own dependencies and packages, which helps avoid conflicts between projects.
Authenticating with Twitter’s API using GoLogin
To authenticate with Twitter’s API using GoLogin Browser, follow these steps:
- First, create an account with GoLogin if you haven’t already. You can sign up for a free 7-day trial of a paid plan. Forever-free version will allow for 3 profiles.
- Open the browser and create a new browser profile. This will allow you to simulate a different device and browser each time you use Twitter’s API access, which can help you avoid detection.
- Navigate to https://developer.twitter.com/en/apps and log in to your Twitter account.
- Click the “Create an app” button and fill out the required information, such as the app name, description, and website. Make sure to select the appropriate app permissions based on your use case.
- Once you have created your app, navigate to the “Keys and Tokens” tab and click the “Generate” button under “Consumer Keys” to generate your API key and API secret key. Keep a secure record of these: save them into a text document or use a trusted password manager.
- Next, click the “Generate” button under “Access Token & Secret” to generate your access token and access token secret. Save these in a secure place together with the API keys.
- Now, you will use the API keys and access tokens retrieved from the text document or password manager in your Python script along with the tweepy library. The tweepy library will handle the API requests and authentication process, while GoLogin will help you avoid detection by simulating different browsers and devices.
Here’s an example of how you can use tweepy in Python along with GoLogin browser:
import tweepy # Function to read API keys and access tokens from a text file def read_twitter_keys(filename): with open(filename, 'r') as file: lines = file.readlines() consumer_key = lines[0].strip() consumer_secret = lines[1].strip() access_token = lines[2].strip() access_token_secret = lines[3].strip() return consumer_key, consumer_secret, access_token, access_token_secret # Read API keys and access tokens from the text file twitter_keys_file = 'twitter_keys.txt' consumer_key, consumer_secret, access_token, access_token_secret = read_twitter_keys(twitter_keys_file) # Authenticate with Twitter using tweepy auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) # Create an API object api = tweepy.API(auth) # Now you can use the 'api' object to make requests to Twitter's API and perform various tasks # For example, you can search for tweets, post tweets, etc.
Scraping Twitter Data using Python and GoLogin
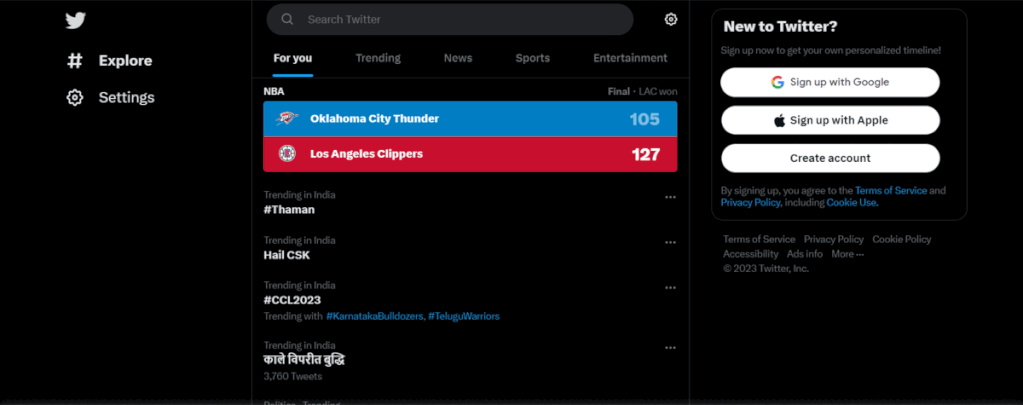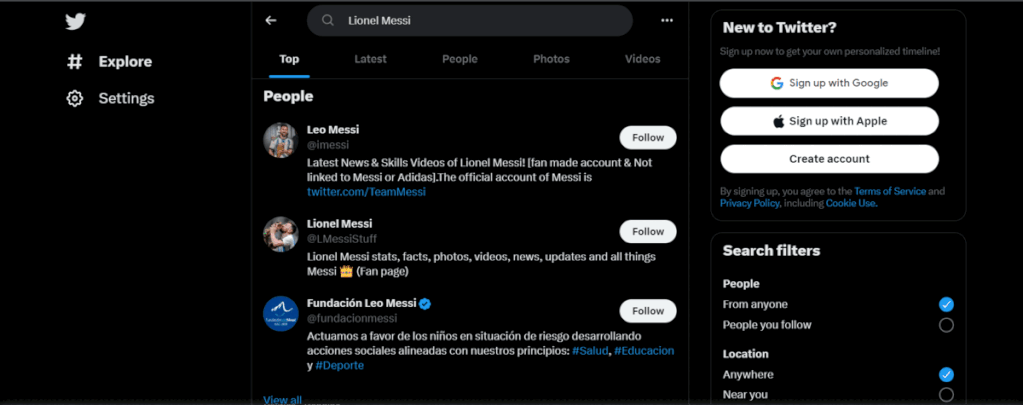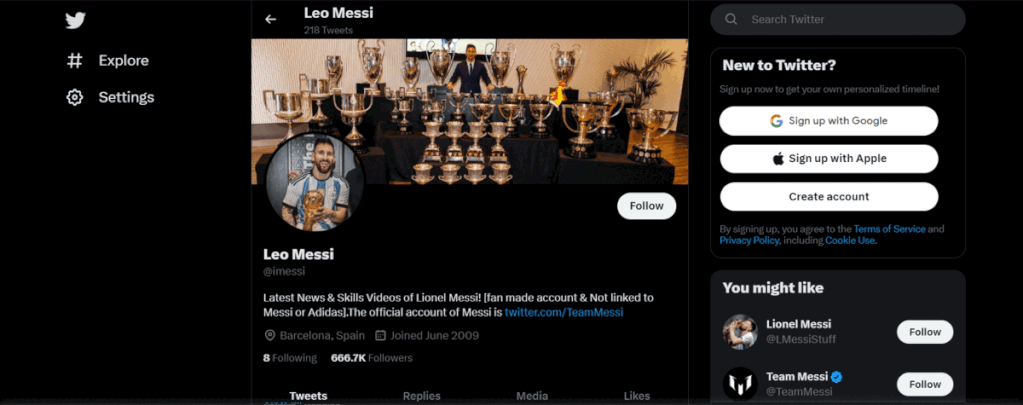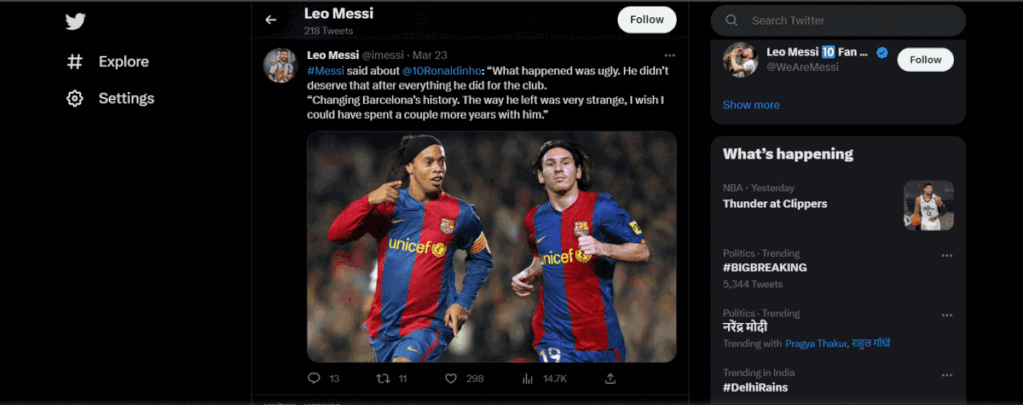
Python’s Selenium package and GoLogin’s secure browser are used to automate logging into a Twitter account, searching for tweets on a specific topic, and extracting data points from those tweets. You can extract the user tag, timestamp, text content, number of responses, retweets, and favourites.
The search box, filter buttons, and tweet articles must be located on the Twitter website using XPATH, and the path to the chromedriver executable must be specified. After the data has been extracted, it can either be exported to a file or saved in lists for later examination.
Scraping Twitter data in this way can be useful for gathering information on user sentiment, trending topics, or to conduct research on social media usage. However, it is important to adhere to Twitter’s terms of service and not use this method to violate user privacy or engage in any unethical practices. We advice to go for publicly available Twitter data only.
Import necessary libraries
# Import Dependencies import selenium from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from time import sleep
This code is importing necessary modules from the Selenium web automation library and the time module. It sets up the environment to control a web browser using Selenium. Specifically, it imports the Selenium library, the webdriver module to control the browser, the By class to specify how to locate HTML elements, and the Keys class to send special keys to the browser.
The sleep function from the time module is also imported. Overall, this code is preparing the necessary tools to automate web browsing tasks using Selenium in Python.
Create Webdriver and Login to Twitter
# Specify the path to the chromedriver executable
PATH = "path_to_chromdriver_file"
# Create a new instance of the Chrome web driver
driver = webdriver.Chrome(PATH)
# Open the Twitter login page
driver.get("https://twitter.com/login")
# Wait for the page to load before continuing
sleep(3)
# Find the username input field using its XPATH and enter a username
username = driver.find_element(By.XPATH,"//input[@name='text']")
username.send_keys("your_username_or_email")
# Find the 'Next' button using its XPATH and click it to move to the password field
next_button = driver.find_element(By.XPATH,"//span[contains(text(),'Next')]")
next_button.click()
# Wait for the next page to load before continuing
sleep(3)
# Find the password input field using its XPATH and enter a password
password = driver.find_element(By.XPATH,"//input[@name='password']")
password.send_keys('your_password')
# Find the 'Log in' button using its XPATH and click it to log in
log_in = driver.find_element(By.XPATH,"//span[contains(text(),'Log in')]")
log_in.click()
This code is using Selenium to automate logging into Twitter using a Chrome web driver. Here’s a summary of what the code does:
- Imports necessary modules from Selenium and time.
- Specifies the path to the chromedriver executable.
- Creates an instance of the Chrome web driver.
- Navigates to the Twitter login page.
- Waits for the page to load.
- Finds the username input field using its XPATH and enters a username.
- Finds the ‘Next’ button using its XPATH and clicks it to move to the password field.
- Waits for the next page to load.
- Finds the password input field using its XPATH and enters a password.
- Finds the ‘Log in’ button using its XPATH and clicks it to log in.
In summary, this code automates the process of logging into Twitter using Selenium and a Chrome web driver.
Search For a User
subject="Lionel Messi" # Wait for the page to load before continuing sleep(3) # Find the search box input field using its XPATH and enter the subject to search for search_box = driver.find_element(By.XPATH,"//input[@data-testid='SearchBox_Search_Input']") search_box.send_keys(subject) # Simulate pressing the ENTER key to submit the search search_box.send_keys(Keys.ENTER)
Here’s a summary of what the code does:
– Waits for the page to load for 3 seconds.
– Finds the search box input field using its XPATH and enters the subject to search for, which is specified by the subject variable.
– Simulates pressing the ENTER key to submit the search.
In summary, this code automates the process of searching for a subject on Twitter using Selenium and a Chrome web driver.
Go to the People Tab
# Wait for the page to load before continuing sleep(3) # Find the 'People' filter button using its XPATH and click it to filter search results people = driver.find_element(By.XPATH,"//span[contains(text(),'People')]") people.click()
This code is continuing the previous code and is using Selenium to automate filtering Twitter search results to show only people. Here’s a summary of what the code does:
- Waits for the page to load for 3 seconds.
- Finds the ‘People’ filter button using its XPATH.
- Clicks the ‘People’ filter button to filter the search results.
In summary, this code automates the process of filtering Twitter search results to show only people using Selenium and a Chrome web driver.
Click on the Profile of the User
# Wait for the page to load before continuing sleep(3) # Find the first profile on the search results page using its XPATH and click it to visit the profile page profile = driver.find_element(By.XPATH,'//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div/div/div[3]/div/section/div/div/div[1]/div/div/div/div/div[2]/div/div[1]/div/div[1]/a/div/div[1]/span/span[1]') profile.click()
This code is continuing the previous code and is using Selenium to automate visiting the profile page of the first search result on Twitter. Here’s a summary of what the code does:
- Waits for the page to load for 3 seconds.
- Finds the first profile on the search results page using its XPATH.
- Clicks on the first profile to visit its profile page.
In summary, this code automates the process of visiting the profile page of the first search result on Twitter using Selenium and a Chrome web driver.
Scrape Tweets of the User
# initialize empty lists to store scraped data
UserTags=[]
TimeStamps=[]
Tweets=[]
Replys=[]
reTweets=[]
Likes=[]
# find all tweet articles on the page
articles = driver.find_elements(By.XPATH,"//article[@data-testid='tweet']")
# loop over the articles to extract data from each tweet
while True:
for article in articles:
# extract user handle
UserTag = driver.find_element(By.XPATH,".//div[@data-testid='User-Name']").text
UserTags.append(UserTag)
# extract timestamp
TimeStamp = driver.find_element(By.XPATH,".//time").get_attribute('datetime')
TimeStamps.append(TimeStamp)
# extract tweet text
Tweet = driver.find_element(By.XPATH,".//div[@data-testid='tweetText']").text
Tweets.append(Tweet)
# extract number of replies
Reply = driver.find_element(By.XPATH,".//div[@data-testid='reply']").text
Replys.append(Reply)
# extract number of retweets
reTweet = driver.find_element(By.XPATH,".//div[@data-testid='retweet']").text
reTweets.append(reTweet)
# extract number of likes
Like = driver.find_element(By.XPATH,".//div[@data-testid='like']").text
Likes.append(Like)
# scroll down to load more tweets
driver.execute_script('window.scrollTo(0,document.body.scrollHeight);')
sleep(3)
# find all tweet articles again to check if there are more tweets to scrape
articles = driver.find_elements(By.XPATH,"//article[@data-testid='tweet']")
# remove duplicate tweets and check if enough unique tweets have been scraped
Tweets2 = list(set(Tweets))
if len(Tweets2) > 5:
break # exit loop if enough unique tweets have been scraped
This code is using Selenium to scrape data from the Twitter search result page that was visited previously. Here’s a summary of what the code does:
- Initializes empty lists to store scraped data.
- Finds all tweet articles on the page using their XPATH.
- Iterates through each article and extracts the desired information (user tag, timestamp, tweet text, number of replies, number of retweets, and number of likes).
- Appends the extracted information to their respective lists.
In summary, this code automates the process of scraping data from the Twitter search result page using Selenium and a Chrome web driver, and stores the scraped data in lists for further analysis.
Result
print("UserTags : "+UserTags[0])
print("TimeStamp : "+TimeStamps[0])
print("Tweet : "+Tweets[0])
print("Replys : "+Replys[0])
print("reTweets : "+reTweets[0])
print("Likes : "+Likes[0])

Using Gologin For Scraping
After configuring your proxy settings and browser profile, you may start web scraping. You will need a language like python to create web scraping script. Using the GoLogin-generated browser profile, the script should access the website and extract the relevant information.
- Importing the necessary libraries, such as sys, selenium, chrome options, time, and gologin, was the initial modification. The following lines of code were added to the top of the file to do this:
python from sys import platform from selenium import webdriver from selenium.webdriver.chrome.options import Options from gologin import GoLogin
- Setting up GoLogin and Selenium WebDriver: The installation of Selenium WebDriver and GoLogin was the second modification. The following lines of code were added to the top of the file to do this:
gl = GoLogin({ 'token': 'yU0token', 'profile_id': 'yU0Pr0f1leiD', }) if platform == "linux" or platform == "linux2": chrome_driver_path = './chromedriver' elif platform == "darwin": chrome_driver_path = './mac/chromedriver' elif platform == "win32": chrome_driver_path = 'chromedriver.exe' debugger_address = gl.start() chrome_options = Options() chrome_options.add_experimental_option("debuggerAddress", debugger_address) driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)This code configures GoLogin with the proper platform-specific WebDriver path, token, and profile id. After that, it launches GoLogin and configures WebDriver with the proper debugger URL.
- Updating the code to use the WebDriver: The code was updated to use WebDriver for navigation and scraping as the last change. This was accomplished by modifying the code to utilise driver.page source instead of response.content for scraping and driver.object instead of the requests library for navigating.
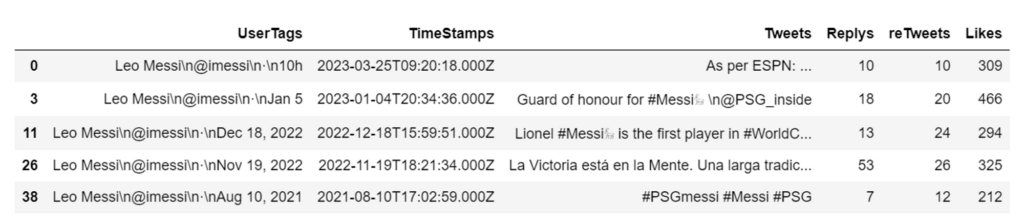
- Make dataframe from the list
import pandas as pd df = pd.DataFrame(zip(UserTags,TimeStamps,Tweets,Replys,reTweets,Likes) ,columns=['UserTags','TimeStamps','Tweets','Replys','reTweets','Likes']) # drop duplicate rows df = df.drop_duplicates() df.head()
- Result
Advanced Twitter Scraping Techniques with GoLogin and Python
Here are some advanced Twitter scraping techniques using GoLogin and Python:
- Use proxies: By using proxies, you can make it more difficult for Twitter to detect your scraping activities. GoLogin allows you to easily set up and use proxies for your web scraping needs.
- Rotate User-Agents: Twitter may also detect scraping activities by monitoring the User-Agent header of incoming requests. By rotating User Agents, you can make it harder for the platform to identify your Twitter scraper as a bot. GoLogin makes it easy to set up User Agent rotation.
- Use Headless Browsers: By using a headless browser like Chrome or Firefox, you can scrape data without opening an actual browser window. This can help improve performance and reduce the likelihood of being detected by Twitter. GoLogin supports headless browsing with popular browsers.
- Use XPaths to target specific elements: When scraping Twitter, you can use XPath to target specific elements on a page such as tweets or user profiles. This can help you extract only the data that you need, and avoid scraping irrelevant information.
- Use Selenium to automate interactions: Selenium is a powerful tool for automating interactions with web pages. With GoLogin, you can use Selenium to automate actions such as logging in to Twitter or navigating to specific pages.
- Monitor Twitter using streaming APIs: Twitter also provides a streaming API that allows you to monitor and track tweets in real-time. This can be useful for tracking mentions of your brand or monitoring specific keywords or hashtags.
Overall, these advanced techniques can help you improve the efficiency and effectiveness of your Twitter scraping efforts. With GoLogin and Python, you have the needed scraping tools to scrape Twitter data at scale while minimizing the risk of detection.
Best Practices for Twitter Scraping with Multi Accounting Browsers
Web Scraping Twitter with multi accounting browsers can be a complex task, as Twitter actively blocks scraping and can detect and block bot-like behavior. However, there are several best practices you can follow to increase your chances of successful scraping while using multi accounting browsers:
- Mimic human behavior: Make sure your scraping bot behaves like a human Twitter user. This means mimicking mouse movements, typing speed, and scrolling patterns. Use random delays between actions, and avoid making too many requests in a short period of time.
- Rotate IP addresses: Twitter can easily detect scraping activity coming from a single IP address. By rotating IP addresses, you can avoid being detected and blocked. Use a pool of proxy servers or a rotating residential IP service to switch IP addresses between requests.
- Use a user agent: Twitter can detect scraping activity based on the user agent string. Use a user agent that mimics a popular web browser such as Chrome or Firefox, and rotate the user agent string between requests.
- Use headless browsers: Headless browsers are browsers that run in the background without a graphical user interface. They can be used to simulate user behavior while scraping, while reducing the overhead of rendering a graphical interface.
- Scrape selectively: Rather than scraping the entire Twitter website, focus on specific pages or sections that are relevant to your needs. This reduces the amount of data you need to scrape, and reduces the likelihood of being detected and blocked.
- Avoid excessive scraping: Scraping too much data in a short period of time is a sure way to get detected and blocked. Spread your scraping out over time, and avoid making too many requests in a short period of time. Scrape public data only.
- Monitor your bot: Monitor your scraping bot for errors and blockages, and make adjustments as needed. Use tools like log files, monitoring services, and alerting systems to stay informed of your bot’s behavior and status.
Overall, web scraping Twitter with multi accounting tools requires careful planning, attention to detail, and a commitment to following best practices. By implementing these best practices, you can increase your chances of successful scraping, while reducing the likelihood of detection and blocking by Twitter.
Some Updates & Trends To Follow In 2025
One major trend that will certainly stay in 2025 is the use of AI-powered scraping tools tailored for platforms like X. These tools use machine learning to mimic human behavior, bypassing detection systems more effectively.
For example, they can:
- simulate natural scrolling
- randomize interaction patterns
- adapt dynamically to changes in website structure.
Additionally, real-time data extraction has become a priority for developers scraping X, as the platform’s content is time-sensitive. Tools like Apify or Octoparse now offer features for live data collection, ensuring up-to-the-minute accuracy.
Another important development is the increasing reliance on antidetect browsers with an API for X scraping. Tools like GoLogin allow developers to manage browser fingerprints and avoid detection by X’s security systems. These highlight the need for scrapers to stay ahead of evolving anti-bot technologies while adhering to ethical guidelines and respecting platform policies.
Some X Updates To Check Out In 2025
- X has seen major API and access changes implemented after Elon Musk’s acquisition. X has significantly tightened its access controls and changed its rate limiting policies, making traditional scraping approaches more challenging. Modern scraping solutions now need to incorporate more sophisticated session management and request patterns to work effectively with X’s enhanced security measures. Additionally, X’s switch to a paid API model has pushed developers to explore alternative approaches for data collection.
- A key development point is specialized X/Twitter scraping frameworks that are specifically designed to handle the platform’s unique challenges. These tools often incorporate advanced browser fingerprinting techniques with antidetect browsers, intelligent rate limiting, and automated CAPTCHA handling. Look for solutions that offer features like: session persistence, automatic retry mechanisms, and built-in compliance with X’s current terms of service.
- Ethical and legal landscape around X/Twitter scraping has evolved. X often change their terms of service, data privacy regulations, and best practices for responsible data collection. This includes proper handling of user privacy, respecting rate limits, and ensuring that scraping activities don’t disrupt X’s services or violate user rights. Many modern scraping tools now include built-in features to help ensure compliance with these requirements.
Conclusion
In this guide, we have guided you through web scraping Twitter data using Python and GoLogin multi accounting browser. We hope that this guide has given you a good starting point for scraping Twitter data, and that you can use the knowledge gained to build more advanced web scraping projects.
FAQ
1. Is web scraping allowed on Twitter?
Twitter does not allow anyone to gather data from their services without permission, as stated in their Terms of Service. However, web scraping and data extraction itself is not illegal according to the US and EU laws. As long as you don’t cause serious damage to private companies, you can scrape publicly available data as much as needed.
2. Does Twitter ban scraping?
Yes, Twitter does ban scraping. Twitter clearly states that it does not allow the collection or scraping of data from their platform without permission. Violation of these terms may result in the suspension of the offending account and even a lawsuit if the damage caused to the business is serious.
According to Elon Musk, Twitter has applied temporary reading restrictions to curb “extreme levels” of data scrubbing and system manipulation. In the tweet, he indicated that verified accounts can read no more than 6,000 posts per day, while unverified accounts can read 600 posts per day.
3. What is the best tool for scraping Twitter?
Many tools exist for scraping Twitter, and there is no “best” one – it depends on your needs, goals, skills and budget. Most people go for open source tools like BeautifulSoup or Scrapy as they prove their effectiveness.
Remember to adhere to Twitter’s rules when using them. A popular way is to use Twitter’s official API to collect data in a controlled and allowed manner, and connect any well-known scraping tool to the API. Other tools include Tweepy, Twint, Snscrape, etc.
4. How to scrape Twitter without API?
Twitter does not recommend scraping without using the API, and it goes against Twitter’s rules. However, for academic or research reasons, you can use tools like Beautiful Soup or Scrapy in Python to scrape web pages. Remember to respect people’s privacy and follow the law when scraping data.
Download GoLogin here and enjoy safe scraping Twitter with our free plan!
Reference source:
- Zhao, Bo. “Web scraping.” Encyclopedia of big data 1 (2017).
- Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
- Sirisuriya D. S. et al. A comparative study on web scraping. – 2015.
- Szymański P., Kajdanowicz T. A scikit-based Python environment for performing multi-label classification //arXiv preprint arXiv:1702.01460. – 2017.
- Huerta-Cepas J., Dopazo J., Gabaldón T. ETE: a python Environment for Tree Exploration //BMC bioinformatics. – 2010. – Т. 11. – С. 1-7.
Read more from us on this topic:
Web Scraping with Python: A Complete Step-by-Step Guide + Code
Scraping LinkedIn: Pro Scraper’s Guide + Code
Scraping Reddit: Pro Scraper’s Guide + Code