This post has been edited and updated on January 10, 2025.

Scraping data from LinkedIn profiles – is it along with the law or not?
Web scraping LinkedIn is not a new curious trend anymore. This networking platform has grown to be an absolutely vital resource for connecting and developing professional networks. Given the enormous amount of data available on LinkedIn, some people or businesses are interested in scraping information from the site for their own uses.
So, naturally as a business Linkedin applies certain rules to safeguard its users’ data – both public domain and hidden personal data. Their rules forbid using any automated methods to gather data from its platform, including scraping, crawling, data mining, and so on.
LinkedIn employs a number of technical safeguards, including rate restrictions, CAPTCHAs, and IP blocking to limit illegal access to its platform and automated data scraping. These measures are meant to guarantee that only authorized users have access to the platform and its data.
Public Domain
Here’s the deal, though: LinkedIn’s corporate policies do not make scraping LinkedIn unethical, illegal or dangerous – as long as you’re scraping for data in public domain. The EU and USA laws do not forbid scraping for public domain data in any way, even if the local company policy is against that – no matter if it’s from Bangladesh or San Francisco.
While the U.S. circuit court of appeals recently struck down laws that made it illegal to search online databases for information, it didn’t address the issue of scraping. That means it remains perfectly legal to go onto any LinkedIn group or LinkedIn Sales Navigator search and pull up every single piece of information you can find about somebody. We recommend to always work within the boundaries of the law.
So, remember: what you scrape should always be on open access for everyone.

Using Selenium for Scraping Data From LinkedIn
There are many technologies that may be used to perform web scraping, which is a potent method for gathering data from websites. Web scraping can be done with Selenium, a well-liked automation tool. The capability to interact with web pages, model user behaviour, and automate operations are just a few of the characteristics that make it an effective web scraping tool.
Set Up Selenium On Your Computer
To use Selenium with Python , you’ll need to have Python installed on your computer. You can download Python from the official Python website. Once you have Python installed, you’ll need to install the Selenium package by running the command *pip install selenium* in a command prompt or terminal window.


Importing Driver
Selenium requires a web driver to interact with web pages. You can download the web driver for your preferred web browser from the official Selenium website. Once you’ve downloaded the web driver, you’ll need to specify its location in your code by adding a few lines of code at the beginning of your script.
from selenium import webdriver driver = webdriver.Chrome('/path/to/chromedriver')
With your web driver set up, you’re ready to start writing your web scraper. When you’re finished, be sure to close the web driver by adding a line of code at the end of your script to free up system resources.
driver.quit()
Example
Here’s an example of using Selenium for web scraping, to scrape data from a table on a web page. Here is a Python example of how to accomplish this:
from selenium import webdriver driver = webdriver.Chrome() driver.get('https://example.com/table') # Find the table element table = driver.find_element_by_css_selector('table') # Get the column headers headers = [header.text for header in table.find_elements_by_css_selector('theader')] # Get the data rows rows = [] for row in table.find_elements_by_css_selector('trow'): rows.append([cell.text for cell in row.find_elements_by_css_selector('tdata')]) driver.quit() print(headers) print(rows)
In this example, we begin by finding the web page with the table we want to scrape. Then, we locate the table element and retrieve the data rows and column headings using Selenium. The table’s “theader” items are all located, and their text is extracted to yield the column headers.
By locating every “trow” element in the table and retrieving the text from each of their “tdata” child elements, the data rows are obtained. The web driver is then shut down, and the data rows and column headings are printed.

Scraping Data From LinkedIn with Python
To begin, we first import the necessary libraries such as pandas and Selenium. We then use the Selenium library to scrape data from LinkedIn. The following modules from the Selenium Library are used in this code: Webdriver, expected conditions, options, Keys, and sleep from time.
It is important to note that web scraping requires a web driver. In this example, we will use the Chrome browser, and the Chrome driver is downloaded from the internet.
import pandas as pd import time import random import requests from time import sleep from bs4 import BeautifulSoup from parsel import Selector from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys opts = Options() import csv
driver = webdriver.Chrome(options=opts, executable_path= "chromedriver")
The code starts with a function called def validate_field. Here, we validate the field to check whether the field exists on the page. If the field is present, we fill the data in the field.
# function to ensure all key data fields have a value def validate_field(field): # if field is present pass if field: if field: pass # if field is not present print text else: else: field = 'No results' return field
We then use the driver.get method to navigate to the LinkedIn official site, followed by the driver.find_element method to locate the email and password fields. To extract the tag and class of a specific unit, we use the ID of the container, which is known as “session key.” This helps us correctly identify and extract the desired data, allowing us to add the required information to the paragraph.
To retrieve the necessary data, we use driver.find_element_by_id and specify the ID for both containers. The ID for the first container is “session key,” and for the second container, it is “session password.” By doing this, we correctly identify and retrieve the relevant information from both containers, allowing us to perform the required action on the data for each container.
# driver.get method() will navigate to a page given by the URL address driver.get('https://www.linkedin.com') #locate email form by_class_name username = driver.find_element(By.ID, "session_key") # send keys(0) to simulate keystrokes username.send_keys ("*****@gmail.com") # sleep for 0.5 seconds sleep(0.5) # locate password form by_class_name password = driver.find_element(By.ID,'session_password') # send keys() to simulate key strokes password.send_keys('*******') sleep(0.5) # locate submit button by xpath sign_in_button = driver.find_element(By.XPATH,'//* [@type="submit"]') # . click() to mimic button click sign_in_button.click() sleep(10)
After successfully logging in to LinkedIn, we then need to find the links for the particular users from a specific field. For example, suppose we want to find Python developers. In that case, we can search on Google, and we will get some results from LinkedIn. However, we want only the users’ links, so we need to extract them.
# Task 2: Search for the profile we want to crawl # Task 2.1: Locate the search bar element search_field = driver.find_element(By.XPATH, '//*[@id="global-nav-typeahead"]/input') # Task 2.2: Input the search query to the search bar # search_query = input('What profile do you want to scrape? ') search_field.send_keys('Python Developers') # Task 2.3: Search search_field.send_keys(Keys.RETURN) # locate Peoples button by xpath people = driver.find_element(By.XPATH,'//*[@id="search-reusables__filters-bar"]/ul/li[1]/button') # . click() to mimic button click people.click() sleep(2)
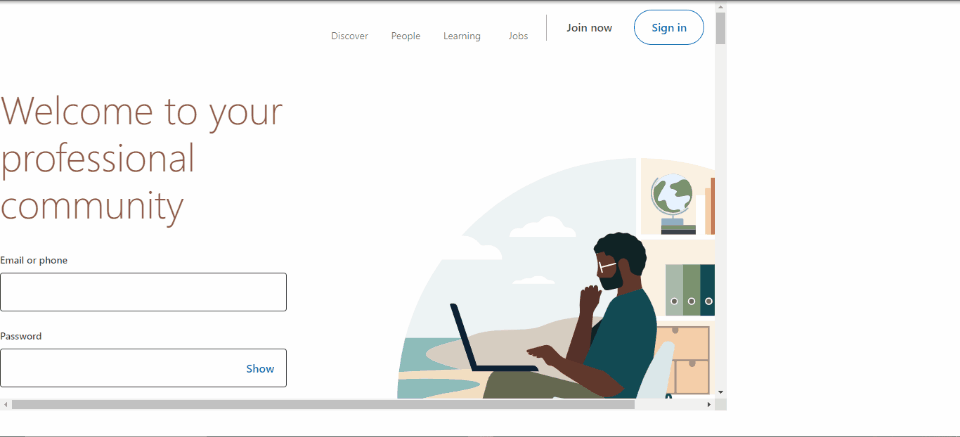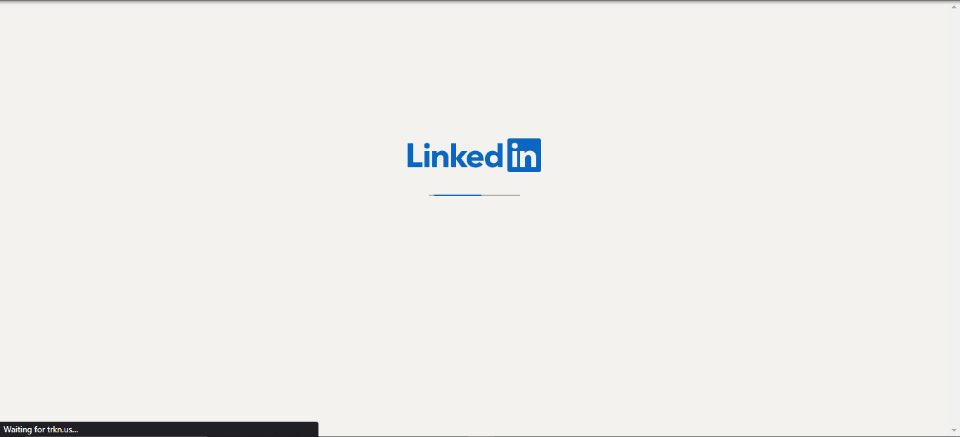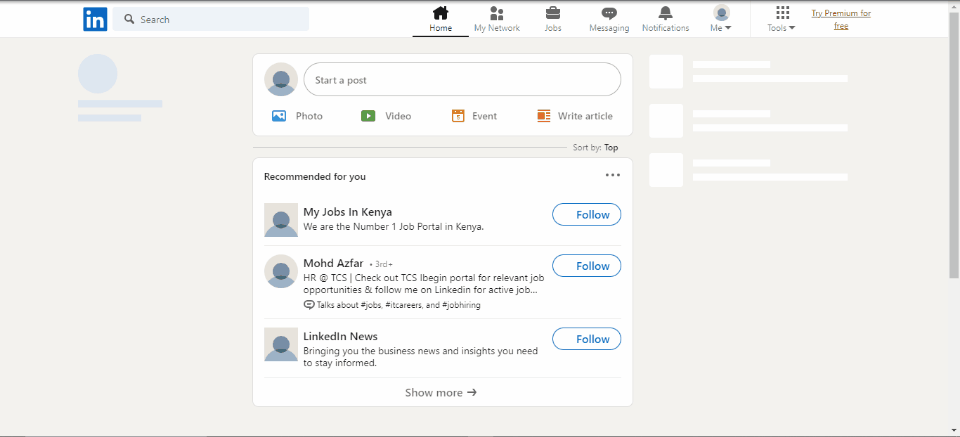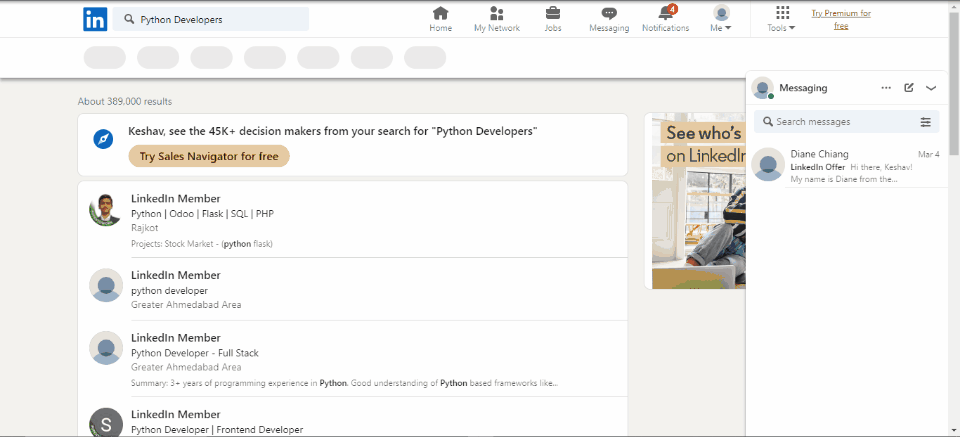
For this, we use a particular link that will give us only the Python developers that are from a specific place. Once we navigate to this link, we use driver.get to go to each page with a certain amount of time, and we retrieve the links for each page.
# Task 3: Scrape the URLs of the profiles profiles = driver.find_elements(By.CLASS_NAME, 'app-aware-link') all_profile_URL = [] for profile in profiles: profile_ID = profile.get_attribute('href') profile_URL = "https://www.linkedin.com" + profile_ID if profile_URL not in all_profile_URL: all_profile_URL.append(profile_URL) print('- Finish Task 3: Scrape the URLs')
Output
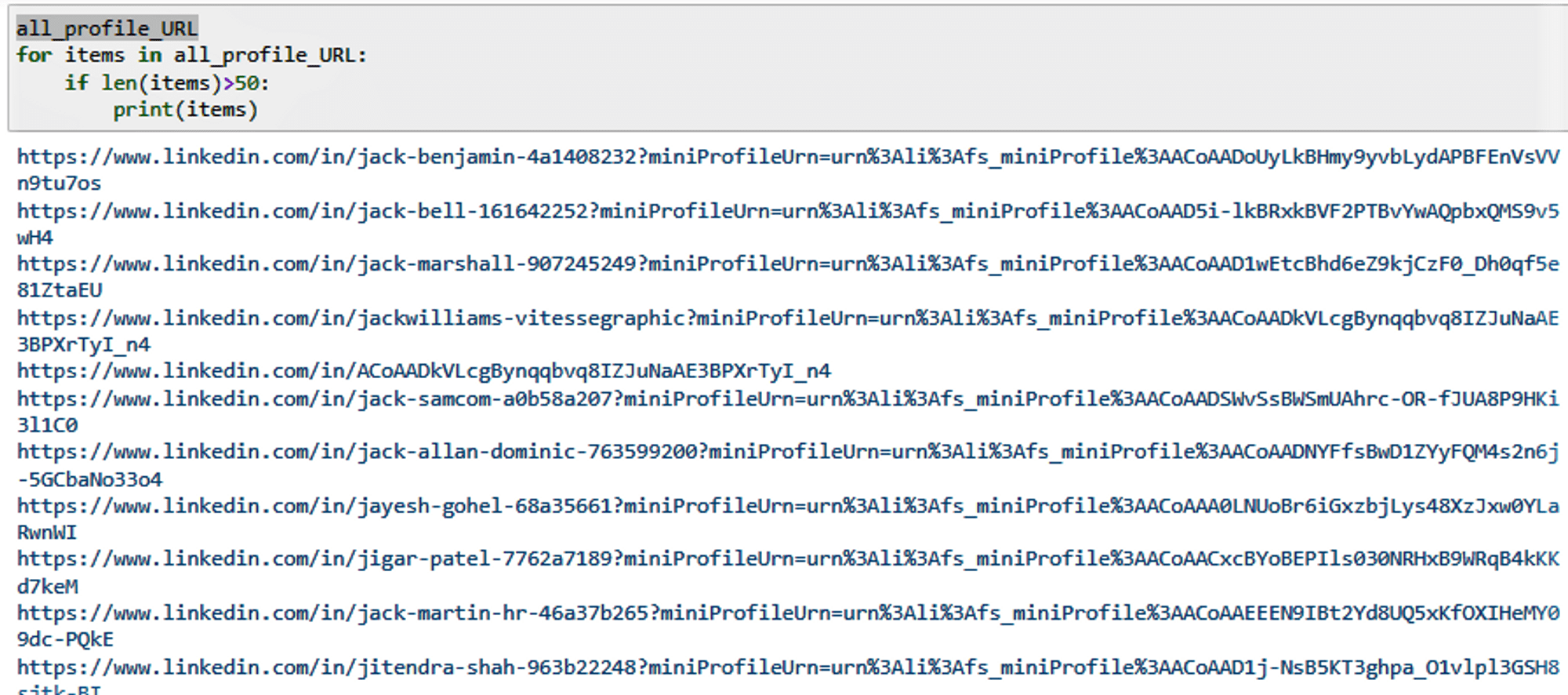
Now extract the required data from the scraped profile links
To extract the links, we use the element.get_attribute(“href”) method to get the attribute, href. Once we have the link, we can navigate to each user or company page, scrape the necessary data and save it to a csv file.
In conclusion, web scraping can be an effective way to collect data from LinkedIn. Selenium and Python provide a powerful combination of tools for web scraping, enabling users to retrieve valuable data from the platform.
Using GoLogin for Safe Work
A online automation platform called GoLogin gives site developers a technique to elude detection by imitating actual user activity. It is challenging for websites to identify automated access because to GoLogin’s ability to generate and manage several browser profiles with distinct identities like user agents, fingerprints, and local IP addresses.
This platform has an intuitive user interface, works with a large variety of browsers and devices, and contains cutting-edge fingerprinting technology that can assist developers in avoiding IP bans and CAPTCHA difficulties.
With GoLogin’s cutting-edge fingerprinting technology, developers can simulate a real user’s digital fingerprint. This technology ensures that automated web chores do not trigger any alarms by making it practically hard for websites to notice automated access. The platform also offers proxy integration, session management, and API support, all of which can speed up and automate development process.
How to set up and use GoLogin for web scraping?
Step 1: Create an account
Making an account on GoLogin’s website is the initial step in using the service. You can accomplish this by going to the GoLogin website and creating an account using your email address. You can log in to the platform and begin configuring your browser profiles after creating an account.
Step 2: Set up a browser profile
GoLogin employs a browser profile as a distinct identity to simulate actual user behavior. Choose the browser you want to use, such as Google Chrome or Mozilla Firefox, before you can create a profile for it. The profile can then be altered by include user agents, fingerprints, and IP addresses. These features will assist in making the profile appear more authentic, lowering the chance of getting discovered.
Step 3: Configure the proxy settings
You can modify the proxy settings for your browser profile to further lower the chance of detection. By doing this, you can give every website you visit a distinct IP address, which makes it more challenging for them to monitor your online behaviour.
Step 4: Start web scraping
You can begin web scraping after setting up your proxy settings and browser profile. You will need write a web scraping script in a language like Python. The script should access the website and extract the necessary data using the GoLogin-created browser profile.
- Importing the required libraries:
The first modification was the import of the required libraries, including sys, selenium, chrome_options, time, and gologin. This was done by adding the following lines of code to the top of the file:
from sys import platform from selenium import webdriver from selenium.webdriver.chrome.options import Options from gologin import GoLogin
- Setting up GoLogin and Selenium WebDriver:
The second modification was the setup of GoLogin and Selenium WebDriver. This was done by adding the following lines of code to the top of the file:
gl = GoLogin({
'token': 'yU0token',
'profile_id': 'yU0Pr0f1leiD',
})
if platform == "linux" or platform == "linux2":
chrome_driver_path = './chromedriver'
elif platform == "darwin":
chrome_driver_path = './mac/chromedriver'
elif platform == "win32":
chrome_driver_path = 'chromedriver.exe'
debugger_address = gl.start()
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", debugger_address)
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
This code sets up GoLogin with the correct token and profile_id, as well as the correct WebDriver path for the platform. It then starts GoLogin and sets up the WebDriver with the correct debugger address.
- Updating the code to use the WebDriver:
The final modification was updating the code to use the WebDriver for navigation and scraping. This was done by updating the code to use the driver object instead of the requests library for navigation and to use driver.page_source instead of response.content for scraping.
Step 5: Monitor your activity
To make sure that websites are not alerted to your web scraping activities, it is crucial to keep an eye on it. GoLogin offers a variety of features to make it easier for you to keep tabs on your activities, including session management, API compatibility, and a dashboard that displays your IP address and current browser profile.

For LinkedIn
One must first create a profile on the GoLogin platform in order to scrape data from LinkedIn utilising that service. You can accomplish this by establishing a new user, choosing a particular browser setting, and adding any required plugins or extensions.
The user can visit the LinkedIn website and log in using their credentials after creating their LinkedIn profile. Next, they may mimic human actions like page scrolling, link clicking, and data entry by using the GoLogin automation tools.
For example, a user might use GoLogin to search for users who have the job title “software engineer” and who are located in a specific city. They could then use automation tools to extract data such as the user’s name, job title, company, and location. A useful tool for that might be LinkedIn Sales Navigator.
Final Output after you export scraped data will look like:

Using numerous profiles to access LinkedIn can help users escape detection and lower their risk of being barred, which is one potential benefit of using GoLogin for LinkedIn scraping. The platform’s terms of service may be broken and scraping data from LinkedIn sales navigator without authorization may result in legal problems, so it’s vital to keep that in mind. As a result, it’s crucial to exercise caution and make sure that any scraping actions are carried out in a morally and legally responsible way.
Tips for Safe Scraping Data From LinkedIn
LinkedIn data collection can provide valuable insights for businesses and researchers, but it’s important to do so ethically and without violating LinkedIn’s terms of service. To avoid getting your LinkedIn scraper banned, web developers should follow some pro tips.
- Limit the frequency of requests to LinkedIn’s servers and set appropriate time intervals between each request.
- Excessive traffic to LinkedIn’s servers can trigger their security systems and result in a ban. Secondly, developers should not use bots or automated tools for scraping LinkedIn data as this violates the platform’s terms of service.
- Mimic human behavior when scraping LinkedIn data. This can be achieved by using a web browser that is commonly used by humans and by making requests at a realistic pace.
- Avoid accessing private profiles or data that is not available to the public.
- Respect the privacy of LinkedIn users and not to use their data for unethical purposes. By following these best practices, web developers can successfully scrape LinkedIn data without getting banned and in an ethical manner.
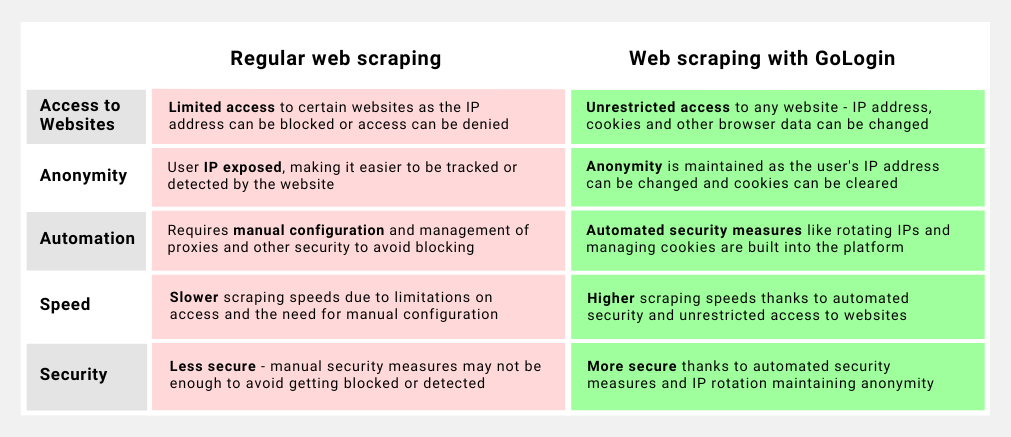
GoLogin provides a way to create and manage multiple browser profiles, which can be useful for avoiding detection by LinkedIn. By rotating through different browser profiles, it becomes more difficult for LinkedIn to detect patterns of scraping activity, which can help prevent risks.
Furthermore, GoLogin allows for IP rotation and remote running the profiles on a cloud based server, which can further protect your work while scraping LinkedIn data. Overall, using GoLogin can be a valuable tool for web developers looking to scrape LinkedIn data safely with no risks.
Download GoLogin here and enjoy safe scraping with our free plan!
Top 7 LinkedIn scrapers to try out in 2025
1. Cognism
Cognism is a robust sales intelligence solution ideal for mid-market and enterprise users. Parent company of Kaspr, it distinguishes itself with high data accuracy through combined human and automated verification processes. Includes Bombora intent data and maintains strict GDPR and CCPA compliance.
Price: Custom pricing based on specific customer needs.
2. GoLogin
Not technically a LinkedIn scraper, GoLogin is a great tool to both manage multiple LinkedIn accounts and protect your scrapers from being banned by LinkedIn. With GoLogin you can forget being restricted on LinkedIn for suspicious logins, or trying to scrape data from multiple devices/locations.
Price: Free plan with 3 profiles; Free 7-day trial of paid features; Paid plans from $24/month.
3. Apollo.io
Description: A comprehensive prospecting platform with a versatile Chrome Extension that works across LinkedIn, Gmail, Google Calendar, and company websites. Features AI recommendations and advanced outreach capabilities.
Price: Free plan with 60 mobile credits annually; Basic plan at $49/user/month includes 900 mobile credits and unlimited email credits.
4. Lusha
Description: A multi-functional sales intelligence platform offering pipeline management, prospecting, and marketing features. Includes contact intent data and CRM synchronization capabilities.
Price: Free plan with 5 phone and 50 email credits annually; Pro plan starts at $36/user/month with 1,920 email and 480 phone credits annually.
5. UpLead
Description: Specializes in real-time email verification and bulk prospecting. The Chrome Extension works across both LinkedIn and company websites, with advanced in-database search filtering capabilities.
Price: Essential plan at $99/month includes 170 credits monthly plus verified emails, phone numbers, and CRM integration.
6. Waalaxy
Description: Focuses on automated LinkedIn prospecting and email finding, with strong GDPR compliance. Includes AI prospect finding capabilities and CRM synchronization, though less emphasis on phone number acquisition.
Price: Freemium plan available; Advanced Plan at $63/month includes 25 email finder credits and 800 invitations monthly.
7. Evaboot
Specializes in LinkedIn Sales Navigator scraping with efficient bulk export capabilities. Offers email verification testing and focuses on accurate contact information discovery in real-time.
Price: Starting at $9/month for 100 credits, scaling to $499/month for 50,000 credits.
FAQ
How do I scrape LinkedIn data for free?
You can scrape public LinkedIn data for free using LinkedIn scraping tools like Octoparse, ParseHub, or Python libraries like Selenium and Beautiful Soup. However, if you scrape LinkedIn profiles that are private or scrape too many of them in a single run, that may violate LinkedIn’s terms of service.
Can I use GoLogin for LinkedIn lead generation?
Sure, but it will require hard work, creativity and some skill to run multiple LinkedIn accounts. GoLogin allows to safely create and run hundreds of accounts, but you will need a well-thought and organized system to generate leads and make money out of your new accounts.
Can I use VPN, proxies or Chrome extensions to safely scrape LinkedIn?
Unfortunately, no. LinkedIn and almost all popular media platforms use high or even extreme levels of protection against suspicious behavior, bots and automatic use. That includes browser fingerprinting, which is quite difficult to override even with special software. VPNs and other “safety measures” will be able to do nothing against it. Be sure to use a trusted privacy browser that’s able to deal with browser fingerprinting.
What is the best tool for scraping LinkedIn?
Some popular tools for scraping LinkedIn data include Octoparse, ParseHub, ScrapeHero, and Phantombuster. These provide user-friendly GUIs to extract data without coding. For more advanced scraping, Python with Selenium and Beautiful Soup is very powerful. We also recommend using a privacy browser like GoLogin to protect your scrapers from anti-bot engines.
Can you scrape LinkedIn with Python?
Yes, you can absolutely scrape LinkedIn with Python! Using Selenium, you can set up LinkedIn automation and repeat actions like login and scrolling to dynamically load pages. Beautiful Soup can then parse the HTML to extract the data you want. The Python LinkedIn library also offers some useful scraping functions. Overall, Python provides a very flexible way to scrape LinkedIn.
Read this article in Portuguese:
Scraping de Dados do LinkedIn: Guia Profissional de Scraping + Código
References:
- Gibson B. et al. Vulnerability in massive api scraping: 2021 linkedin data breach //2021 International Conference on Computational Science and Computational Intelligence (CSCI). – IEEE, 2021. – С. 777-782.
- Lange D. Recognizing the public domain //Law and Contemporary problems. – 1981. – Т. 44. – №. 4. – С. 147-178.
- Sumbaly R., Kreps J., Shah S. The big data ecosystem at linkedin //Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. – 2013. – С. 1125-1134.
- Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
- Bradbury D. Data mining with LinkedIn //Computer Fraud & Security. – 2011. – Т. 2011. – №. 10. – С. 5-8.


