Web scraping projects are going to grow exponentially, and they’re here to stay. The web scraping software market will grow from $0.54B in 2021 to $1.15B in 2027 (a 113% increase).
Data is the new oil. Businesses of all sizes process data in incredible amounts. The Covid-19 pandemic fueled data-driven lead generation even more.
The future of this industry looks bright, and we want to give you a glimpse of it in this article.

The Growing Importance of Data-Driven Decision-Making
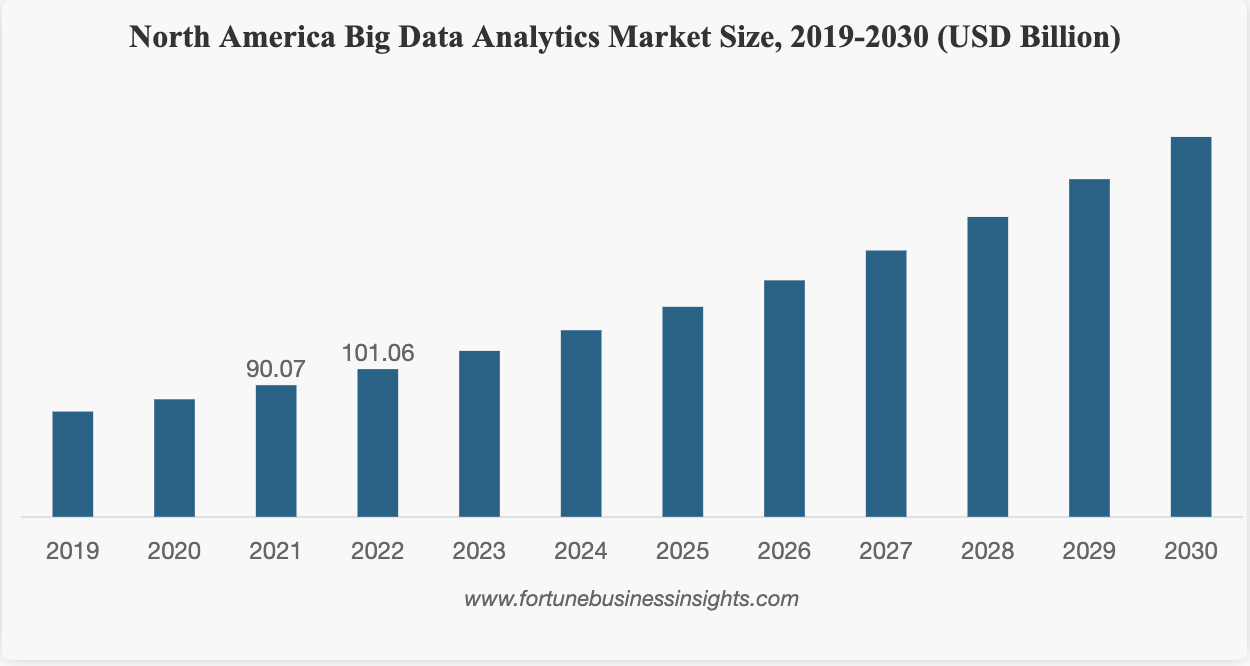
Big data is a huge market. It’s currently valued at over $271.83B and will grow significantly from here.
The world is estimated to create, consume, and store about 150 trillion gigabytes of data. Let’s try putting that into a visual perspective. A line made of hard drives required to store that much data will reach the Moon and back about 56 times.
The average company analyzes around 40% of its web data. You guessed it right: a lot of that data comes from data scrapers.
As more and more organizations adopt data-driven decision-making, the importance of learning web scraping as a process will grow. Implementing new web scraping project ideas and performing them with machine learning and AI automations is likely to become a critical skill for data scientists.
For example, at GoLogin we have recently seen a 25% user retention increase and a 15% conversion rate boost. That happened after we analyzes user behavior data pipeline and improved our platform based on data-driven decision-making.
Emerging Trends in Web Scraping Projects
Integration of AI/ML
We’re living through an AI boom right now. Everything that AI touches seemingly turns to gold, which also seems true.
ML can reduce manual labor of data scientists by improving the accuracy of scraping systems for complex websites.
As Victoria Mendoza (CEO @ MediaPeanut) points out:
For example, in my previous company, we used AI/ML to build a model that extracted product data from e-commerce websites, making the process much faster and more accurate.
This technology will be a game-changer in web scraping job market, as it will help turn the process to automated fashion and make it more efficient.
AI promises to reduce scraping time, improve accuracy with a good fault tolerance, and make the process easier. It would be interesting to see how much of this actually becomes a reality.
Dmitrii Ivashchenko, a software engineer at my.games, puts forward a good opposing view:
Their (AI/ML) effectiveness is limited by the quality and quantity of training data, making it challenging to generalize models for all cases.
While these technologies can help identify patterns, understand website structures, and adapt to changes in web page layouts with minimal human intervention, automation may lead to an increase in the extraction of irrelevant or low-quality data.
This could negatively impact business decision-making processes.
While AI can change how we scrape data, it can also significantly upgrade anti-bot detection systems.
It’s crucial, considering that 52.3% of all traffic in 2021 was bot traffic. Moreover, Cloudflare reported a 60% YoY increase in ransom DDoS attacks in Q1 2023.
AI can improve bot-detection systems by analyzing many malicious visitor patterns, especially using browser fingerprints. Jordan Hansen from Cobalt Intelligence also echoes this sentiment:
AI will help anti-bot solutions better stop and protect against bad actors. But AI will also help web scraping be less likely to be detected. It’s already a cat-and-mouse game. This is going to accelerate it immensely.
GoLogin is an excellent web scraping tool for overcoming such restrictions. It allows you to create a custom browser fingerprint to surf anonymously based on over 50 characteristics. Even a VPN or incognito mode won’t provide this security.

CAPTCHAs are already a pain, and it won’t get any easier.
Real-Time Web Scraping and Data Streaming
Currently, scraping data in real time is realistic only via an API, which many websites don’t provide. You simply cannot send a request that extracts data every few milliseconds (yet). In the future, though, we might be able to do so without overloading the website or getting blocked.
Using live up-to-date data from search engines for forex/stock monitoring, investment decisions, customer review research could be a data science game changer.
Matthew Ramirez (a Forbes 30 under 30 alum) @ Rephrasely says that
For my business, we relied heavily on Google Analytics to see how well our website performed. Historically, I would have to go into the website to get this data manually.
Now with the ability to do real-time scraping, I can have that information sent to me in real-time, so I can see how the website performs at any given time. This is a huge benefit for me, as it means I can react much quicker if there is a problem with the website.
This is just one of the many uses of real-time scraping at scale.
It comes with its challenges as well, though. Real-time scraping from data sources requires a lot of computing resources. This could be a barrier for small businesses and organizations with limited budgets.
The Rise of No-Code and Low-Code Web Scraping Solutions
Not everyone at a company is an expert web scraper; no-code and low-code solutions help bridge the programming language gap. They also help reduce app development time by 90%.
This is why 70% of new business apps will use low-code/no-code technologies by 2025. No-code and low-code apps are great for simple scrapers, but don’t expect them to support complex use cases.
One of the best examples of such an app is Octoparse, which is a no-code tool. It allows you to get a volume of data into a spreadsheet with just a few clicks.
It comes with things like IP Rotation, IP proxies, CAPTCHA solving, and more. It makes the process effortless, proven by real user reviews.

But it’s also somewhat hard to scrape websites with these tools. Many users complain that tools like Octoparse cannot scrape a simple webpage.

We will see many more no-code tools like this, and AI could potentially revolutionize this space.
Imagine a future where you can just tell GPT what website you want to scrape, and it does the job for you.
Legal and Ethical Considerations
Performing web scraping using Python projects is not illegal, but can be – if done wrong. Legal and ethical considerations in web scraping are growing with its increasing popularity.
Many experts believe that respecting website ToS and avoiding unauthorized access, obtaining consent, being transparent about data collection policies, and respecting the rights of website owners and users will grow in importance.
90% of Americans believe privacy is very important to them, and the number will grow from here.
Personal data scraping is also getting more regulated. In the LinkedIn vs. hiQ legal proceeding, LinkedIn claimed that hiQ labs was knowingly scraping personal data sets from the platform, even though the User Agreement prohibited it.
According to Sarah Wright (VP of Legal @ LinkedIn), LinkedIn won the case, and hiQ had agreed to a permanent injunction requiring them to stop scraping and destroying all source code, data, and algorithms created when hiQ scraped member profile data violating LinkedIn’s User Agreement.

It’ll be interesting to see where things go from here!
The Future of Web Scraping: Opportunities and Challenges
AI/ML is a big opportunity in web scraping. Apart from that, here’s what GoLogin’s CEO thinks:
Apart from AI/ML, potential developments in the web scraping space may include more sophisticated anti-detection techniques, increased collaboration between scraper tools and web platforms for more responsible data gathering, and a growing focus on data privacy and compliance with regulations like GDPR and CCPA.
Many other experts also echo this sentiment, especially regarding the importance of regulatory compliance. Combating anti-bot techniques and tightening regulations will be the biggest obstacles for web scrapers to overcome.
We’ve talked about how anti-detection techniques will be supercharged by AI, making it a double-edged sword. Experts expect the bot mitigation market to grow at a CAGR of 24.3% from 2023 to 2033, which is incredible.

A good middle ground may be to create public APIs for all publicly available data to facilitate easy and legal scraping. But the sad truth is that there’s too much data and insufficient resources to make APIs for all of it. Even the biggest web servers and fastest web browsers have their limits.
For businesses, data management might be a nightmare. More data can lead to information overload, stopping practical interpretation and utilization. We see an opportunity for agencies and freelancers to provide legal and compliant web scraping projects in the future.
Anti-bot platforms and apps to bypass anti-bot measures like GoLogin will also become popular.
Conclusion
That’s the future of the web scraping industry in a nutshell. Tracking it is crucial since it plays a massive role in data-driven business decision-making.
- Web scraping’s market size is expected to increase, but many obstacles will also arise.
- AI, the hot new kid on the block, can revolutionize web scraping project ideas in favor of and against web scrapers. It can already analyze data easy and fast, but it will also supercharge anti-bot measures.
- Real-time scraping looks promising too. And the democratization of web scraping is expected, with more no-code and low-code tools popping up.
- Finally, legal considerations and regulations can slow down the industry.
The industry’s future seems very exciting, and we’ll help you stay up to date with it! Happy scraping!
Read more from our Web Scraping Series:
- The fundamental tools, techniques, and best practices for web scraping
- Introduction to Python as a powerful language for web scraping
- Web Scraping Tools and Services: A Comprehensive Review
- Common Challenges and Use Cases in Web Scraping
- Real World Examples of Web Scraping in 2023
Stay tuned for more and download GoLogin to scrape even the most advanced web pages without being noticed!
Frequently Asked Questions
What are good web scraping projects?
- Price comparison and monitoring for e-commerce websites
- Collecting real estate listings for analysis
- Gathering job portal postings for job market research
- Extracting data from social media for sentiment analysis
- Building a news aggregator for specific topics
- Compiling data for academic or research purposes
How do I create a web scraping project?
- Define the project’s goal and the data you want to scrape.
- Choose the appropriate tools and programming languages like Python for web scraping.
- Identify the target websites and inspect their HTML structure.
- Write the web scraping code to fetch and parse the data from the web pages.
- Store the scraped data in a structured format like CSV, JSON, or a database.
- Test your web scraper and ensure it works correctly.
- Respect website policies and avoid overloading servers with excessive requests.
How to do a web scraping project in Python?
- Install Python and the required libraries (e.g., BeautifulSoup, Scrapy).
- Identify the website structure and the data you want to scrape.
- Write Python code to make HTTP requests and fetch the web pages.
- Use BeautifulSoup or Scrapy to parse the HTML and extract the desired data.
- Process and store the data in the desired format (e.g., CSV, JSON).
How do I run a Python project source code?
- Ensure Python is installed on your system.
- Open a terminal or command prompt and navigate to the project’s directory.
- Run the Python script using the command:
python your_script.py. - Observe the output or any errors displayed in the terminal.
References:
- Bostock M., Ogievetsky V., Heer J. D³ data-driven documents //IEEE transactions on visualization and computer graphics. – 2011. – Т. 17. – №. 12. – С. 2301-2309.
- Pentland A. S. The data-driven society //Scientific American. – 2013. – Т. 309. – №. 4. – С. 78-83.
- Solomatine D., See L. M., Abrahart R. J. Data-driven modelling: concepts, approaches and experiences //Practical hydroinformatics: Computational intelligence and technological developments in water applications. – 2008. – С. 17-30.
- Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
- Sirisuriya D. S. et al. A comparative study on web scraping. – 2015.


