
There’s no doubt in stating that cloud computing enabled a wide range of new opportunities in the tech space, and this is true also for data scraping.
Cheap virtual machines and storage enabled to scale the of activities to a new level, allowing companies to crawl a larger number of websites at a fraction of the traditional cost.
This doesn’t mean that large-scale web scraping projects are cheap, but also because things are getting harder, as I wrote in my previous post here.
In this post I’ll benchmark the costs of the services of the top 3 cloud providers by market share (according to Statista), simulating different web scraping scenarios and architectures and choosing the cheapest availability zone for each provider.
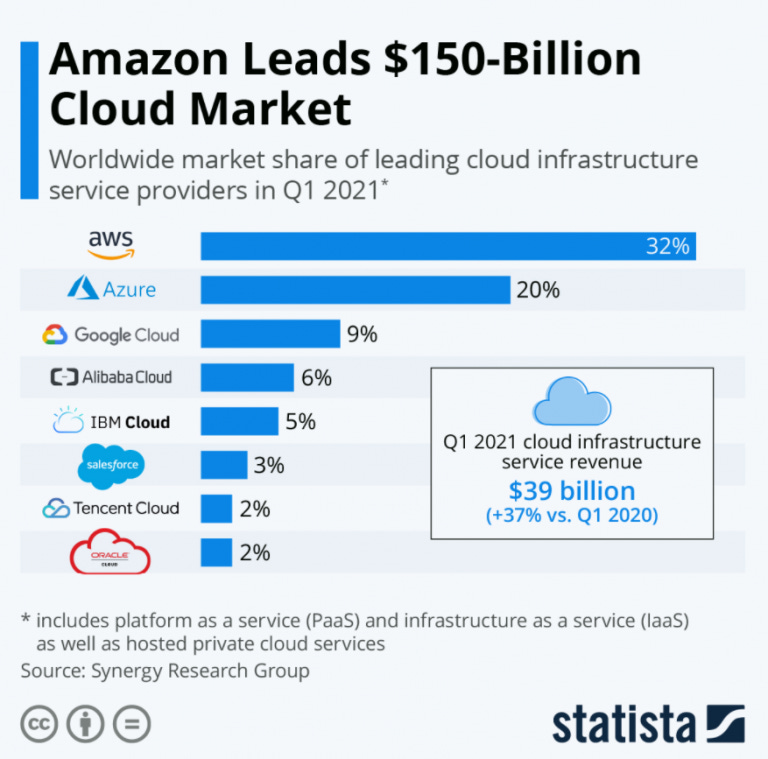
To keep things simple and comparable between the providers, we’ll compare the following architectures:
- Micro-sized virtual machines, for scrapers using Scrapy or other headless programs.
- Medium-sized virtual machines, for full headful browser support.
- Storage pricing
- Proxy providers’ pricing comparison
Data Scraping Tech: Micro-Sized Virtual Machines
This is the use case where we need a virtual machine just to run a simple scrapy spider.
To get a meaningful benchmark between the players I’ll choose a configuration that is as similar as possible between them and the smallest machine possible to use with Scrapy.
Then I’ll calculate the costs of 10.000 hours of the utilization of this setup across the 3 providers, a thing that is not always so obvious. Please let me know in the comment section if I missed something.
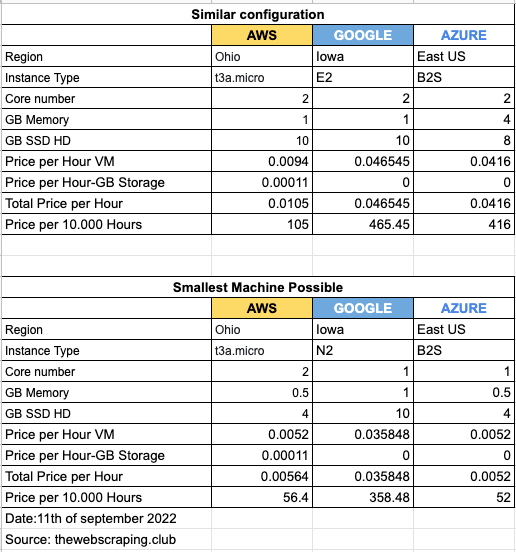
I may have missed something about the pricing of storage for Azure, but we clearly have 2 winners for the base configuration.
Google configurations are way too expensive to be taken into consideration for a large number of basic scrapers running.
Medium-Sized Virtual Machines
If we consider a medium-sized virtual machine, with more Ram to handle a fully headed browser and a well written scraper, the price gap between the providers tightens, but always in favor of AWS and AZURE.
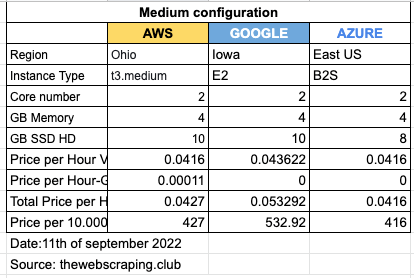
Considering that at Databoutique.com we use approx 500k hours of different sizes every month, it’s easy to understand why is crucial to choose the right provider.
Storage Pricing
Every cloud provider we’re considering has its own storage service but with different plans depending on access time to the data stored and replication across the regions.
Trying to simplify the plans and make some comparisons, I’ve selected the 4 offers of Azure and Google and matched them with 4 of the various options that AWS gives.
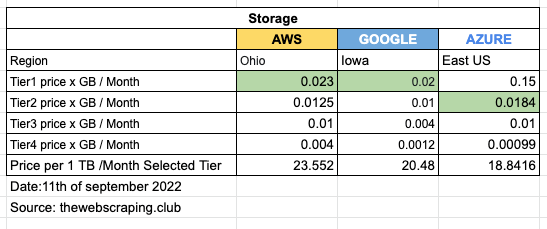
All the prices are without any redundancy options and, on top of the Google prices, we must add the price per operation that GPC charges (about 5 to 50 cents per 10k operations).
Storage is kinda cheap but for a large-scale web scraping project, its expense voice can grow quite fast.
Depending on the purpose of the project, it may be necessary to store the HTML code of the scraped pages to fix some scraping issues in past executions. This can make storage prices grow incredibly fast: let’s suppose we have a large website, with 500k pages each of 200KB, read every day.
It makes 95GB of stored HTML, which become approx 25GB after the Gzip operation. If we need to store every execution for 30 days, each day we’ll have 30 executions stored, which makes 750 GB a month, about 18 USD for storing only one website code.
Proxy Services
The cost of the proxies depends on many factors, first of all, our target websites.
- Do their data have some sort of geo-blocking or geo-targeting that require the request to be made from a certain IP range?
- Are the websites allowing a few requests coming from the same IP in a small timeframe?
- Are the websites using strong anti-bot countermeasures to avoid being scraped?
In any case, a large-scale web scraping project very rarely can avoid using proxy services, and pricing plans vary from provider to provider.
Just to bring two examples:
Bright Data, as you can see from their pricing page, offer prices per GB of traffic that vary on the usage and the type of proxy needed.
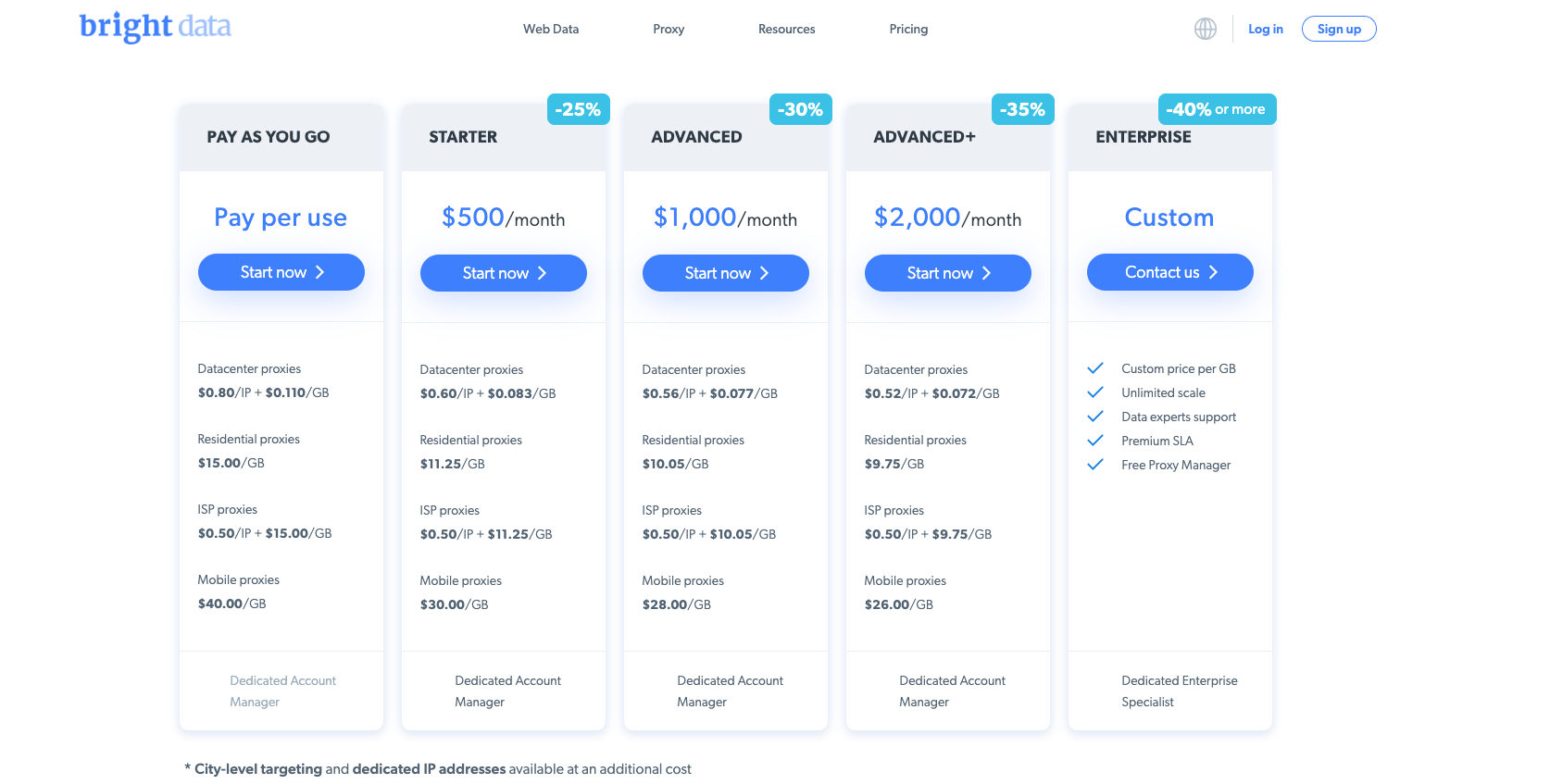
Same with Oxylabs, another big player in this market, bills per GB with prices varying from the type of proxy. Here you can see the prices for the data center proxies, the less expensive ones.

Ca va sans dire, the less we rely on proxies and the more efficient our scraping architecture.
Takeaways On Data Scraping
Web scraping, when made on large scale, costs. And we didn’t even mention the costs of other pieces of the data pipeline ( databases, monitoring software, data quality, ETLs) and of the people needed to make everything work.
And the worst is that is very rare that scraped data can be seen as interesting to potential customers straight from day 1.
Usually, it takes months, if not years, to have a valuable dataset, so costs build up during this timeframe.
Building an efficient data scraping system is key then to slowing down the burn rate and beating the competition in the long run.
A Few Scattered Notations
I’d like to thank everyone for the great following you’ve shown up to my first article of the series “The Lab”, about scraping data from a mobile app. It broke every record of views.
This article was kindly provided by Pierluigi Vinciguerra, web scraping expert and founder of Web Scraping Club. Follow this link to see the original post.
Download GoLogin here and explore the scraping world with our free plan!


