So, what’s this web scraping thing everyone is talking about?
Let’s imagine the internet as the world’s largest data center. Have you ever wondered how you could extract useful insights from it? Finding and copy-pasting individual data would take too much time for large-scale work.
The answer lies in the art of web scraping, which involves automated data extraction from websites and databases.

Web scraping is one of the most popular and powerful internet research tools for numerous purposes, such as competitor analysis, data mining, content aggregation, and market research. You can extract necessary web resources such as photos, text, links, or any other data based on your requirements.
It’s an exciting field, and this article will provide a detailed overview of web scraping, its essential tools, techniques, and best practices to bring you up to speed! So, let’s buckle up and explore the interesting field of data scraping.
What is Web Scraping?

Web scraping is an automated process for extracting data such as codes, links, images, or any other structured data from websites.
If you still don’t understand it, think about it like this. Imagine that you’re catching fish (looking for valuable data) in the ocean (on the web). You would use a big net or a fishing rod to catch them.
Web scraping is that net or fishing rod. It’s a tool to extract what you need and store it somewhere for analysis or your use case.
In the real world, it’s used for monitoring product prices, lead generation, sentiment analysis, content aggregation, academic research, etc. Some Artificial Intelligence programs also use web scraping techniques to analyze and provide results.
Some exciting examples of web scraping include
- Extracting price information from different e-commerce websites, comparing prices from the dataset, and selecting the best deal.
- Monitoring your brand or product on social media and responding to your possible customers.
- Scraping stock market data from various websites, analyzing this data, and making decisions based on real-time data. It can be an excellent tool for stock market traders and investors.
- Collecting data from different weather forecast websites, analyzing the data, and providing up-to-date weather forecasts for specific locations.
- Collecting up-to-date news from various news portals and creating a single platform that shows the latest news
Now, you might be thinking, “Damn! That’s so cool! But how do I do that?”
Good question! There are many tools and technologies available for web scraping. Most programming languages like Python or R have specific libraries or extensions that allow you to extract data efficiently.
Beautiful Soup, Scrapy, Selenium, and Octoparse are the most widespread web scrapers. In the next section, we’ll explore these popular web scraping tools. Let’s dive right in!
Overview Of Popular Web Scraping Tools
Web scraping tools are software applications that allow you to extract data from websites.
Below, we’ve listed some of the most popular web scraping tools and their pros and cons. Let’s choose the best one for your project.
1) Beautiful Soup

BeautifulSoup is a Python parsing library that extracts data from HTML and XML files. It is easy to use and can navigate through HTML and XML documents. This tool extracts data from web pages such as images, texts, links, etc.
BeautifulSoup mainly works by parsing HTML or XML files and generating a parse tree that it can traverse to locate specific elements. It also includes various functions for searching and filtering the parse tree.

Code snippet:
>>> from bs4 import BeautifulSoup
>>> sample = BeautifulSoup("<p>Some<b>example of<i>HTML")
>>> print(sample.prettify())
<html>
<body>
<p>
Some
<b>
example of
<i>
HTML
</i>
</b>
</p>
</body>
</html>
>>> sample.find(text="example")
'example'
>>> sample.i
<i>HTML</i>
2) Scrapy

Scrapy is a Python-based framework aimed at extracting data from internet resources. It contains a rich set of web crawling, data extraction, and processing functionality, making it a powerful and flexible tool for web scrapers.
One of the major advantages of Scrapy is its performance. It is fast, efficient, and able to extract a large amount of data in a short amount of time. It can also format the results in several formats, including CSV, JSON, XML, and others.

Code snippet:
from pathlib import Path
import scrapy
class mySpider(scrapy.Spider):
name = "example"
start_urls = [
'https://example.toscrape.com/page/1/',
'https://example.toscrape.com/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'example-{page}.html'
Path(filename).write_bytes(response.body)
3) Selenium
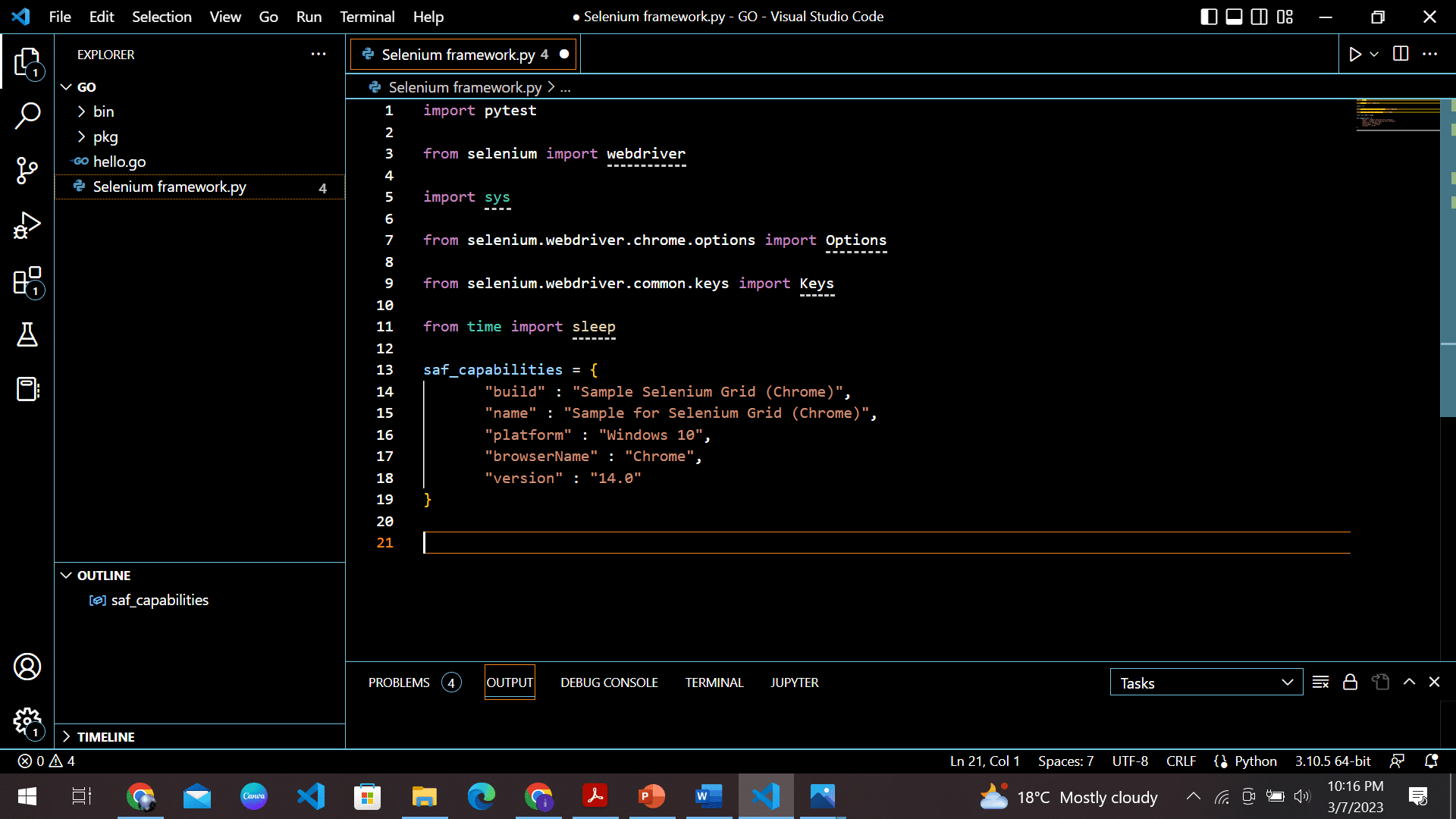
Selenium focuses on browsers, which means it can be slower and requires a browser, unlike other web scraping tools. However, Selenium’s flexibility and versatility make it an effective and powerful tool for scraping dynamic pages.
Selenium is compatible with popular programming languages like Python, Java, and C#. It can access the HTML of the web page and extract data. It also contains built-in methods for accessing specific elements from the web page using element IDs and classes.

Code snippet:
import pytest
from selenium import webdriver
import sys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from time import sleep
saf_capabilities = {
"build": "Sample Selenium Grid (Chrome)",
"name" : "Sample for Selenium Grid (Chrome)",
"platform" : "Windows 10",
"browserName" : "Chrome",
"version" : "14.0"
}
4) Octoparse

Octoparse is a web scraping tool perfect for anyone who needs to extract data from websites but wants to save time learning to code. With Octoparse, you can scrape data using a simple, visual point-and-click interface, which means you don’t need any programming knowledge to get started.
Octoparse can organize the result in various formats, such as Excel, CSV, JSON, and more. It also provides a cloud-based scraping solution that enables users to run it on their server. Octoparse has a built-in data extraction engine that can automatically identify and extract the data you need from web pages, so you don’t have to waste time manually selecting data fields.

Overview of Popular Web Scraping Techniques
Have you ever found yourself in a situation where you need to extract data from a website, but copying and pasting each piece of information is too tedious and time-consuming?
Well, data scraping techniques are here to save the day!
With web scraping techniques, like DOM parsing, regular expressions, and XPath, you can extract the exact data you need from a website’s HTML code.
Let’s discuss a few of the most popular data scraping techniques and their pros and cons.
1) DOM Parsing

DOM parsing is a web scraping technique that involves analyzing the HTML structure of a web page to extract specific data elements like headings, paragraphs, images, links, etc.
The Document Object Model (DOM) is a tree-like structure that represents the HTML structure of a web page. Think of it as a treasure hunt for data from numerous sources.
DOM parsing requires a good understanding of HTML structure and can be done using libraries like Beautiful Soup. For example, if you’re scraping an e-commerce website with multiple pages of products, you can use DOM parsing to extract data from each product page by analyzing the HTML structure.

Code snippet:
<html>
<body>
<p id="example"></p>
<script>
var Sampletext, parser, xml;
Sampletext = "<bookstore><book>" + "<title>Dune</title>" + "<author>Frank Herbert</author>" + "<year>1965</year>";
parser = new DOMParser();
xml = parser.parseFromString(Sampletext, "Sampletext/xml");
document.getElementById("example").innerHTML =
xml.getElementsByTagName("title")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
2) Regular Expression
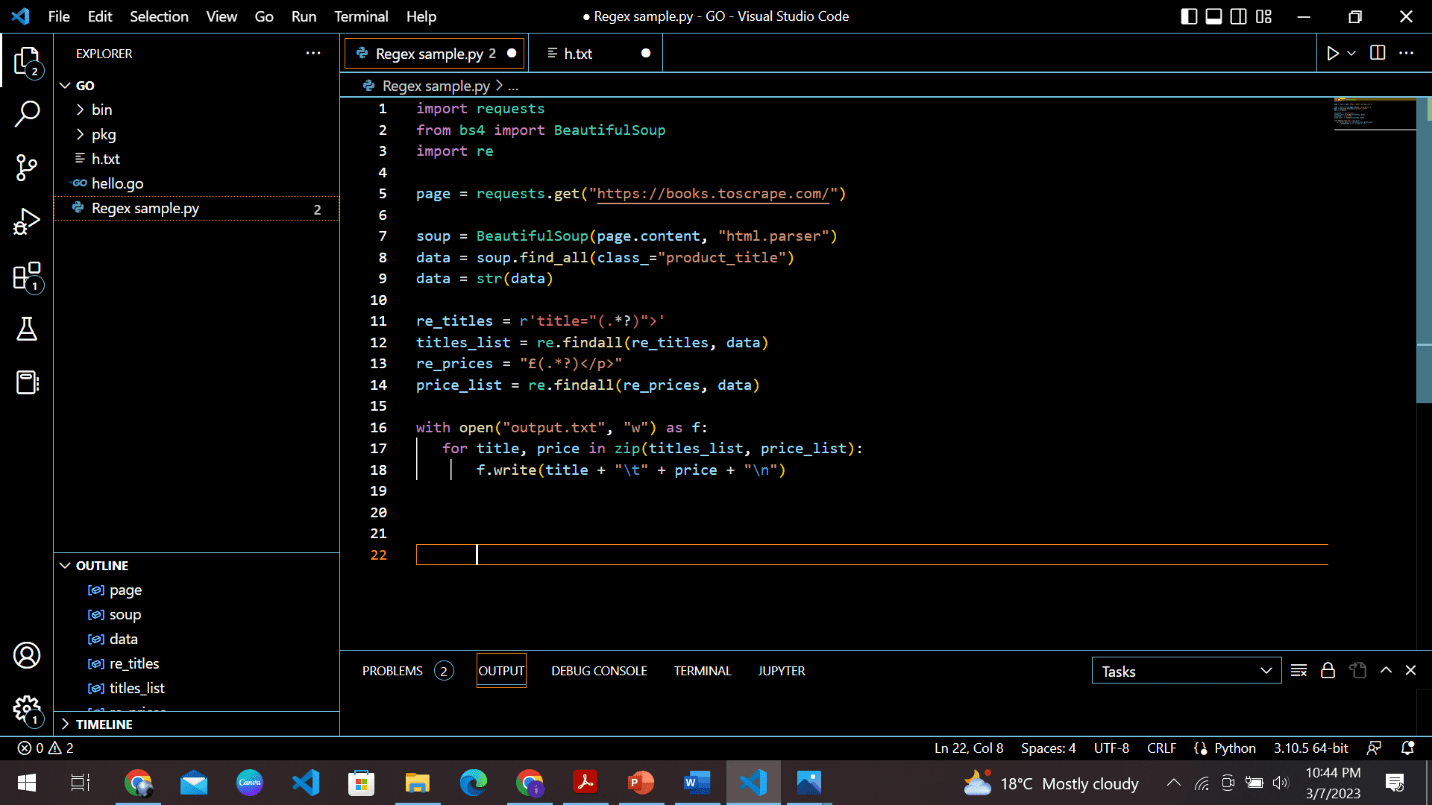
Regular expressions (or regex for short) are a powerful technique used in web scraping to identify and extract specific patterns in the text of a web page. It’s like having a superpower that allows you to find and extract information based on a specific set of rules.
For example, you need to extract all the phone numbers from a website. With regex, you can create a pattern that matches phone numbers in a specific format (such as “555-5555”) and then use that pattern to extract all phone numbers from the web page.
Regex is also useful for extracting structured data like email addresses, URLs, and postal codes.

Code snippet:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get("https://books.toscrape.com/")
soup = BeautifulSoup(page.content, "html.parser")
data = soup.find_all(class_="product_title")
data = str(data)
re_titles = r'title="(.*?)">'
titles_list = re.findall(re_titles, data)
re_prices = "£(.*?)</p>"
price_list = re.findall(re_prices, data)
with open("output.txt", "w") as f:
for title, price in zip(titles_list, price_list):
f.write(title + "\t" + price + "\n")
3) XPath
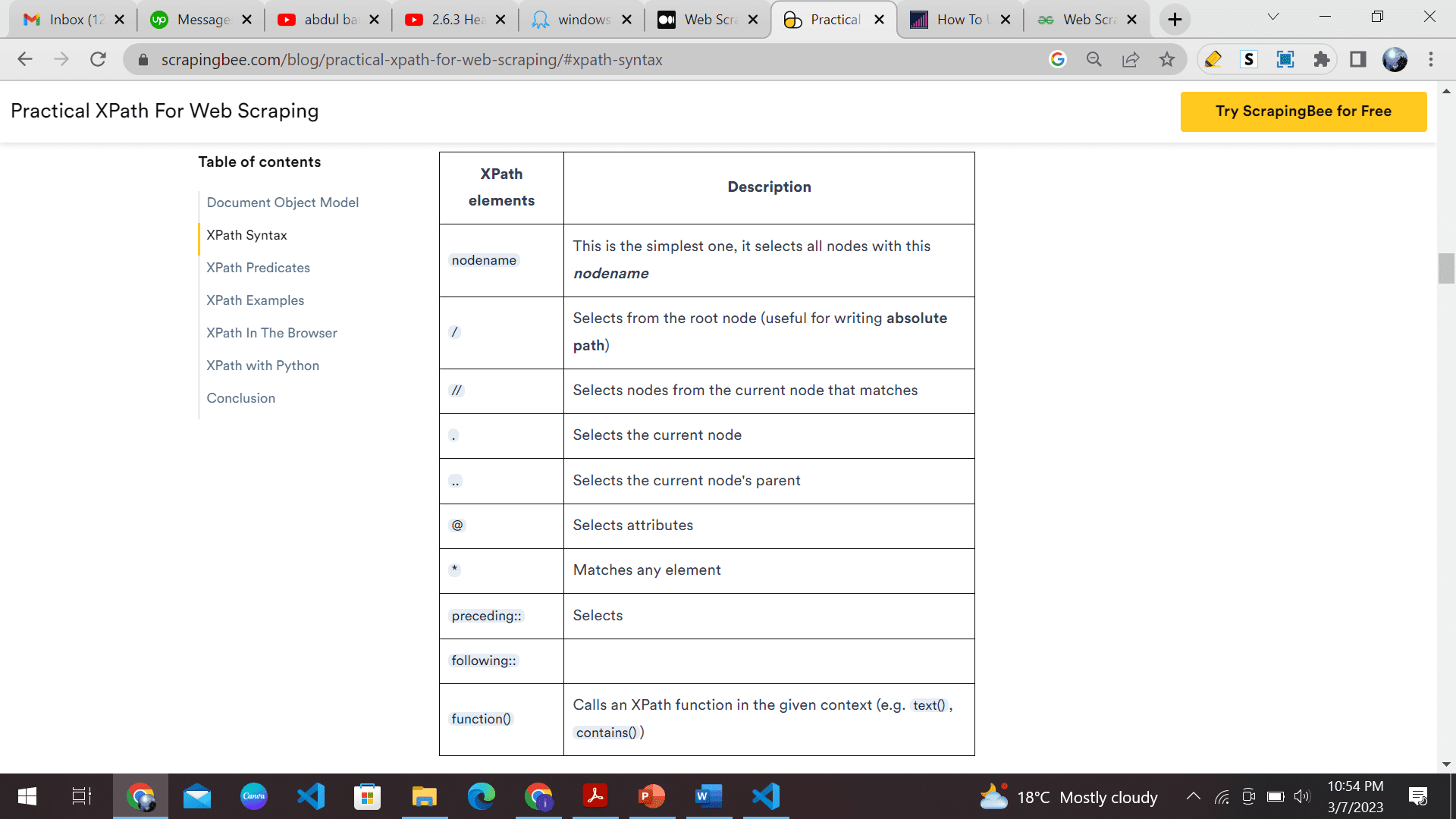
XPath is a language that lets you navigate through the elements of an HTML document and select specific elements or attributes. You can use it with libraries like lxml or Scrapy to scrape data from websites.
So why is XPath so great? It can easily handle even the most complicated web pages.
And even if the structure of a web page changes, you can still use XPath to extract the desired elements.

Now that we’re armed with the capabilities of these powerful tools, it’s time for us to keep certain best practices in mind.
Comparison of Different Web Scraping Tools and Technologies
Which web scraping library is the best?
It depends on your specific use case and proficiency with code. Here’s a quick guide:
- Beautiful Soup: It’s great for scraping data from static websites or web pages with a simple structure—a good choice for beginners.
- Selenium: Selenium is ideal for automating web browser interactions, such as clicking buttons, filling out forms, and navigating between pages. Selenium is more complex than Beautiful Soup.
- Octoparse: Octoparse is a user-friendly web scraping tool for scraping data from multiple pages with similar content. It doesn’t require any coding knowledge, making it accessible to beginners.
- Scrapy: Scrapy is ideal for scraping large amounts of data from complex websites. Scrapy requires coding knowledge and is more complex than Beautiful Soup or Octoparse; it’s a powerful tool for scraping data from advanced websites.
As for web scraping techniques, we’d recommend learning all of them, but some are more useful in specific cases, like:
- XPath is best suited for extracting specific elements or attributes from websites that use XML or HTML with complex structures. XPath may not be the best option for web scraping beginners.
- On the other hand, regular expressions are ideal for extracting structured data and are highly versatile, as they can be applied to any text data. With a basic understanding of RegEx syntax, you can use them with many programming languages.
- DOM parsing is a popular technique for extracting data from websites with complex HTML structures. Beginners can use DOM parsing techniques with the help of libraries like Beautiful Soup, lxml, or jsoup. While understanding HTML and CSS is helpful when working with DOM parsing techniques, it is not strictly necessary.
So, let’s face it: there is no “best” technique for web scraping.
By understanding the strengths of each technique, you can choose the most appropriate technique for your specific use case.
Best Practices for Web Scraping
Web scraping can be a powerful tool for extracting valuable data from websites.
However, it is essential to follow best practices to ensure the scraping process is legal, ethical, and efficient.
Here are some best practices for web scraping:
Techniques for Maintaining Data Quality in Web Scraping
Data quality is super important when it comes to web scraping, especially if you’re using the data for important business decisions or analyses.
Here are some useful techniques for maintaining data quality in web scraping:
- Choose your sources wisely: Before you start scraping, ensure you’re pulling data from reputable sources. If you’re scraping from a site known for inaccurate or unreliable data, you’re likely to end up with inaccurate or unreliable data yourself.
- Check for duplicates: One common issue with web scraping is that you can end up with duplicates of the same data. To avoid this, check for copies before you analyze or use the data.
- Use regular expressions: Regular expressions are a powerful data-cleaning tool that can help you quickly identify and fix any issues with your scraped data. They can also help you extract specific information from your scraped data.
- Handle missing values: It’s common to encounter missing values when scraping data from the web. Make sure to handle these missing values appropriately by filling them in with an appropriate value or removing the incomplete data altogether.
- Clean and standardize your data: One of the biggest challenges with web scraping is that the data you pull can often be messy and inconsistent. To combat this, cleaning and standardizing your data before analyzing it is important. This might involve removing special characters, converting data types, or reformatting text.
Common Mistakes to Avoid in Web Scraping
Let’s be careful and understand the restrictions and things to look out for during our web scraping journey.
Be Respectful with the Robots.txt File
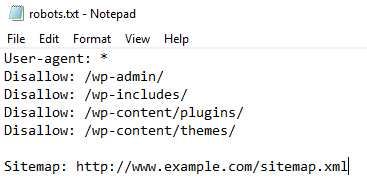
In case you’re wondering what a robots.txt file is, here’s the answer:
It is a text file that tells search engines how to crawl and index pages, restricted pages, and files and provides other instructions for web crawlers to crawl the website. Check it before extracting data from a website.
You may ask, ‘Why should I care about this?’
This file contains a list of rules and instructions for web crawlers to interact with the website. For example, a link containing confidential data might not be available for crawlers.
Another important thing is that this file defines some intervals to hit the website, making it a top-priority best practice.
Off-Peak Hour Scraping
You might think, ‘What are off-peak hours?’
Off-peak hours are when website traffic is considerably less than at any other time.
It helps to improve the crawling rate and avoid extra loads from spider requests. So, running your crawler during off-peak hours can be good practice.
Taking Responsibility for the Data
It is your responsibility to ensure the correct use of the data. It’s pretty straightforward. Just go through the Terms of Services page before starting scraping.
If the website owner doesn’t allow republishing or copying of their data, just avoid it because breaking copyright laws may lead to legal issues.
Data Warehousing
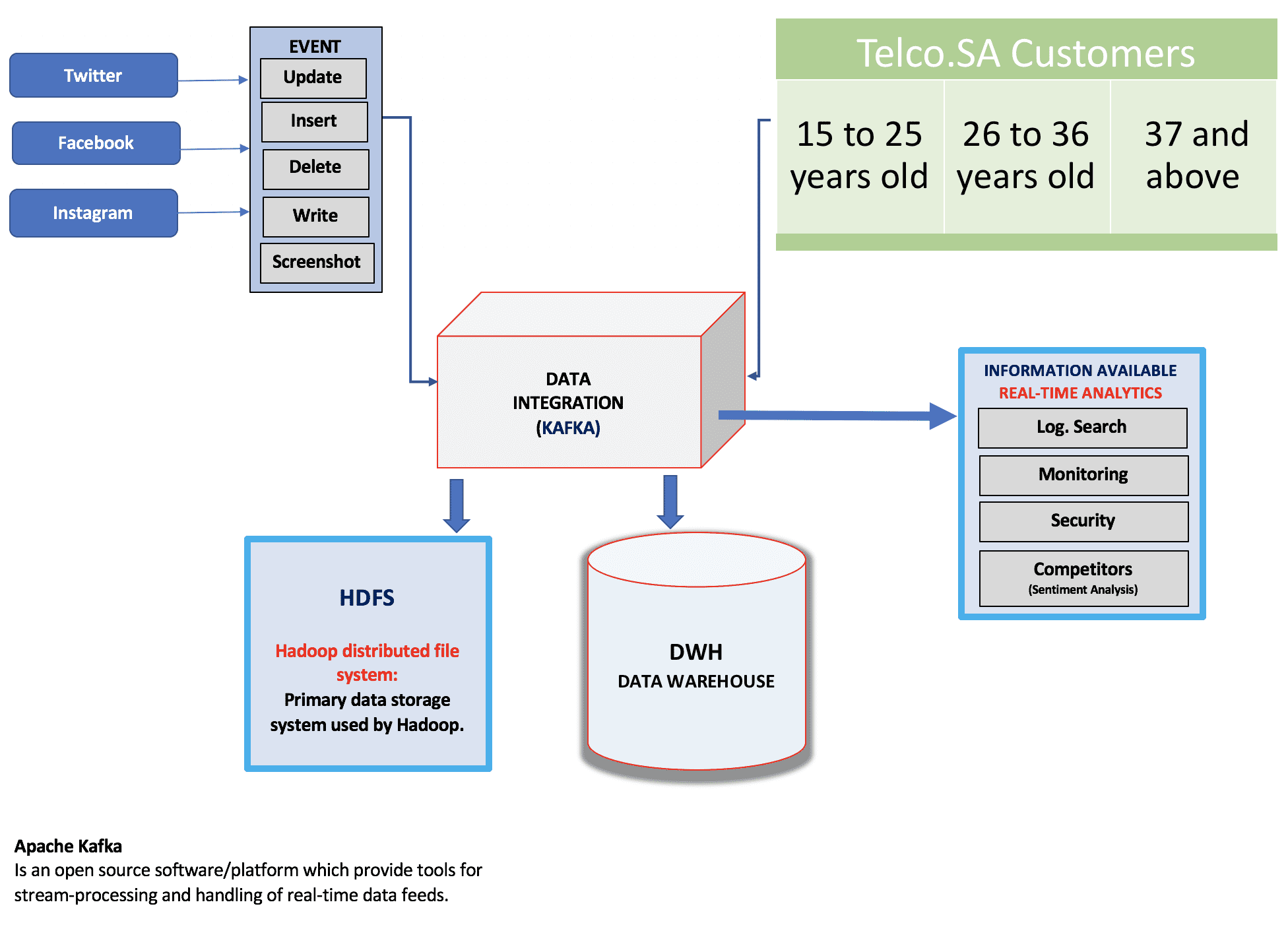
When you start web scraping, you’ll have to deal with a ton of data, which can be a nightmare to manage.
That’s where data warehousing comes in. It’s a technique for managing and organizing large amounts of data from multiple sources in one centralized place.
One of the great things about data warehousing is that it stores data optimally for analysis and reporting, making extracting valuable insights from all that information much easier. Once the data is stored in the warehouse, you can analyze it using various techniques such as data mining and business analysis.
It can help you achieve scalability, fault tolerance, and high availability, making it easier to work with all that data and get the insights you need to make informed decisions.
Rotating IPs and Proxy Services
Sometimes, your spider might be locked when trying to crawl a website frequently.
How can you fix this? The easiest way would be by rotating IPs and Proxy Services during crawling. Rotating means changing the IPs and Proxy Services, so the server doesn’t block the spider.
Another easy way to bypass certain website restrictions/detections is to use GoLogin, as it provides advanced features, giving you control over cookies, browser agents, online fingerprints, and more.
In our next section, we’ll discuss managing a web scraping project. Let’s go through it.
How to Manage Your Web Scraping Project?
Managing web scraping projects can be challenging; hence, it is essential to approach web scraping with a strategic plan and carefully manage your project from start to finish.
By taking a thoughtful approach to web scraping and following best practices for project management, you can ensure that your project runs smoothly and that you can get the high-quality data you need.
So if you’re ready to dive into your web scraping project, look at the following tips and tricks to manage it better:
- Identify your data requirements, such as what kind of data you are willing to deal with and how you will use it.
- Select the best web scraping tool for your project. You can reference the list of popular web scraping tools above.
- Prepare your scraping code and test it. Testing is crucial as it will help you fix bugs and issues affecting data quality.
- If any errors or exceptions occur, handle them strategically, such as retrying failed requests or using proxies to avoid blocking by the server.
- Once you have obtained your data successfully, organize it. You can find practical techniques for organizing data in the Best Practices section.
- Lastly, visualize and analyze your data.
Use Cases and Examples of Web Scraping

-
Price Monitoring for E-commerce
Retailers can track the prices of competitors’ products in real time by scraping their websites, allowing them to adjust their prices accordingly and stay competitive.
-
Social Media Monitoring for Market Research
Social media platforms can be scraped for marketing purposes to gather data on consumer behavior, including sentiment analysis of brand mentions and tracking of hashtags related to their industry.
-
Recruitment
Staffing firms and recruiters can utilize web scraping to collect data on potential candidates from LinkedIn profiles, job portals, and other sources, allowing them to build a robust talent pool and streamline their recruitment process.
-
Real Estate
Web scraping can help gather property listings, including pricing, location, and amenities, allowing them to make more informed decisions when buying and selling properties.
-
Weather Forecasting
Different weather forecast companies can use web scraping to combine information from various sources, such as weather websites, sensors, and satellites, and analyze it to generate more accurate and reliable weather predictions.
These are just a few examples of successful web scraping projects. By leveraging the power of web scraping, businesses across industries can gather valuable data and insights to inform their decision-making and improve their operations.
Conclusion
Web scraping is a powerful technique for extracting data from the internet and using it for various purposes, from business analysis and research to marketing and more.
Throughout this article, we’ve introduced you to some tools and techniques used for data scraping and how to scrape data ethically. We’ve also discussed the importance of testing and monitoring your scraping process and managing your web scraping project.
If you still find things difficult to understand, feel free to try out GoLogin, a powerful and professional privacy tool designed to make your web scraping experience easier and more efficient. Check out this expert article on how GoLogin is used with Playwright to scrape websites with advanced protection like Cloudflare.
Hopefully, this article has equipped you with the basic knowledge of web scraping. With the right approach, web scraping can help you unlock valuable insights and information that can help you make better decisions and achieve your goals.
Or maybe web scraping is your next career?


