Web scraping tools are used to extract data for various purposes, such as market research, data analysis, and content aggregation. Choosing the right web scraping tools or services is crucial for your project’s success, as it can affect efficiency, compliance, and cost.
This article reviews the top web scraping tools and services. We will explore their features, capabilities, limitations and pricing to help you decide which tool or service suits your web scraping project best. So, let’s dive in!

Factors to Consider When Choosing Web Scraping Tools or Services
Now you might be wondering, amidst all the web scraping tools and techniques
that exist in the market, which one is the best fit for you? Well, we can help
you make that decision by highlighting the most important factors you should
consider while choosing a web scraping tool.
Ease of Use
Ease of use is a crucial factor to consider. You don’t want to spend hours
fumbling around with web scraper tools that are difficult to navigate, right?

First, check if the tool has an intuitive user interface that’s easy to
understand. Clear labeling and organization can make all the difference. Second,
the setup process should be straightforward, with clear instructions and
tutorials. Automation options can also reduce the need for manual intervention.
Scalability
If you’re dealing with a large volume of data, you need a tool to handle the
load. You don’t want to sit idle and stare at your buffer to scrape the needed
data. To avoid such problems following are the aspects to consider:
- The tool’s ability to scale horizontally or vertically
- The speed at which it can process data
- The efficiency of its memory usage.
Additionally, check whether the tool or service has features that optimize
performance, such as load balancing or caching. Load balancing means
distributing all the incoming network traffic across a group of backend servers
to ensure efficiency. Cache allows you to store your scraped data, meaning you
can call multiple APIs to scrape a website without hitting the main website.
It’s also worth checking whether the tool has any limitations on the number of
concurrent connections or requests it can handle.
Data Quality and Accuracy
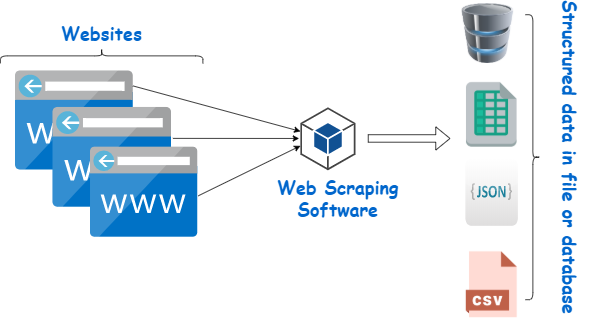
The purpose of web scraping is to extract data. The whole process is pointless
if the data is inaccurate or of poor quality. To ensure high-quality data, the
tool must handle many data structures, like HTML, XML, JSON, nested data, etc.
You must also consider things like:
- Data Cleaning: While web scraping, you may encounter
errors, inconsistencies, or duplicates in your data. Data cleaning is
spotting and fixing these issues so your data looks as good as new. - Validation: In simple terms, consider data validation as
your friendly bouncer, ensuring only the right data enters your database. It
checks if the data collected meets specific criteria or rules you’ve set. - Normalization: Data normalization is like organizing data,
and ensuring your data plays nicely together. It’s a process of converting
data from various sources into a standard format, making it easier to
analyze and compare.
Also, the tool should provide features to verify the accuracy of the extracted
data, such as data comparison and validation against other sources.
Speed and Performance
You need a tool that can extract data quickly and doesn’t lag, especially for
larger projects and those that support real time API. You can determine a tool’s
performance based on many factors, such as its ability to handle multi-threading
and asynchronous requests. These features help
speed up the scraping process. The tool’s ability to handle
proxies can also help improve performance. It allows you to scrape many websites
simultaneously without getting blocked. You must also test the tool’s ability to
handle CAPTCHAs and other anti-scraping measures, as these can impact
performance. In addition, you can check whether your web scraping tool or
service has features allowing you to monitor and optimize performance, such as
logging and error handling.
Cost and Pricing Models

Some web scraping tools may require upfront costs or subscription fees, while
others may charge based on usage or offer a pay-as-you-go model. Another factor
you must consider is whether the tool sneakily charges you for additional
features or support services that should have been free otherwise, as these can
quickly add up. Always look out for a free trial or demo version of a tool
before committing to a paid plan, so you can test drive its features and
functionality. Lastly, don’t forget to check if they offer any sweet deals like
discounts or promotions, such as annual subscriptions or volume-based pricing.
As you venture into advanced web scraping, handling intricate details like managing headless browsers, rotating proxies, and bypassing CAPTCHAs can become quite the undertaking. This is where WebScrapingAPI steps in as a compelling alternative. Tailored for developers, WebScrapingAPI takes care of these complexities, delivering the HTML from any web page via a user-friendly API. This way, you can obtain the data you need without getting bogged down by the technical intricacies of web scraping.
Support and Documentation
The quality of support and documentation can significantly impact the success of
your scraping project. It’s worth checking whether the tool or service offers
email, chat, dedicated, or phone support. Next, check the documentation quality,
such as user guides, tutorials, and FAQs. It’s always a good option to have an
active community forum or knowledge base where you can interact with other users
and developers. Most importantly, check whether the software gets regular
updates and improvements. These factors will help you choose a web scraping tool
or service that provides reliability, ease, and high performance.
Review of Top Web Scraping Tools
Many options are available for those looking to get started with web scraping.
Each tool mentioned below has its strengths and can be an excellent choice
depending on your needs and experience level.
Beautiful Soup
BeautifulSoup is a Python web scraping library specifically designed for parsing
and navigating HTML and XML documents.
Features
- Designed for parsing and navigating HTML and XML documents
- Offers a wide range of parsing options
- Incredibly flexible and can be used with many other web scraping frameworks
and tools
Pros
- User-friendly interface and excellent documentation
- Lightweight and doesn’t require any additional dependencies
- Versatile with many use cases
Cons
- Not very powerful
- Limited usefulness for more complex scraping tasks
- It doesn’t offer the same level of automation as some of the other tools
Scrapy
Scrapy is a powerful and flexible web crawling framework for Python.
Features
- Designed for complex and large-scale web scraping tasks
- Built-in support for handling cookies, sessions, HTTP proxies, and user
agents - Offers advanced features and a high level of customization
Pros
- Highly efficient and fast
- Excellent support for handling complex scraping tasks
- Highly configurable
Cons
- Steep learning curve
- Challenging to set up and configure initially
Selenium
Selenium is a popular open-source web scraping tool widely used for web testing
and automation. It’s built around a web browser automation framework to simulate
user behavior on a website.
Features
- Automate web-based tasks
- Offers support for a range of programming languages
- Capable of handling dynamic websites that use JavaScript and AJAX
Pros
- Excellent choice for automating web-based tasks
- Flexible and supports multiple programming languages
- Free to use and has a vibrant user community
Cons
- Slow and resource-intensive, making it less efficient than other web
scraping tools. - Requires a good understanding of programming concepts
Puppeteer
Puppeteer is a Node.js library that provides a high-level API for controlling
headless Chrome or Chromium browsers.
Features
- Powerful and flexible web scraping tool
- Can interact with web pages using a real browser
- Provides a simple and intuitive API
Pros
- Excellent choice for handling dynamic websites and executing JavaScript
- Simple and intuitive API that’s easy to use and customize
- Free to use and has an active user community
Cons
- Resource-intensive, slower than some other web scraping tools
- It may not be the best choice for all scraping tasks
Other Web Scraping Tools
Apify
It is a web scraping and automation platform that allows you to extract data
from websites, automate workflows, and build web crawlers. It offers many tools
and features like automation, data integration, and data transformation to help
you quickly create and run web scraping projects. Best of all, it requires no
coding experience!
ScrapingBee
ScrapingBee is a web scraping API service that allows you to extract data from
websites using HTTP API calls. It provides a simple interface for web scraping
without writing code. You can specify the URLs, and the API will return the
extracted data from web pages in JSON format. The service also handles common
web scraping issues, such as IP blocking, CAPTCHAs, and JavaScript render.
Playwright
It is a web scraping and automation tool developed by Microsoft that allows you
to automate browser tasks, such as web scraping and testing, across multiple web
browsers, including Chrome, Firefox, and Safari. It provides robust features and
capabilities for web scraping, including support for headless mode, network
interception, and page automation. Playwright is developer-friendly, providing
APIs and libraries in multiple programming languages such as JavaScript, Python,
and C#.
Review of Top Web Scraping Services
Many web scraping services have emerged to overcome the time-consuming and
challenging task of web scraping. They offer various features and capabilities
to help you extract data from websites without writing code. The following
paragraphs will overview some of the top web scraping services available today.
GoLogin
GoLogin is a web scraping service that offers a unique feature –
browser profile management that allows you to manage multiple
web sessions and identities in a single place.
Features

- You can create, customize and manage multiple browser profiles with unique
identities, including IP addresses, fingerprints, and browser settings. - Generates unique browser fingerprints for each profile,
making it harder for websites to detect and block web scraping attempts. - Easy to navigate, with a simple drag-and-drop feature for importing and
exporting data. - Offers integration with popular web scraping tools like Scrapy, Puppeteer,
and Selenium.
Pros
- You can easily create and manage multiple web sessions, increasing the
efficiency and scalability of web scraping projects. - The
browser fingerprinting and IP address</a >
proxy rotation features provide enhanced privacy and anonymity, protecting
users from being detected and blocked by websites. - Offers a free trial and affordable pricing plans, making it accessible to
individuals and small businesses.
Cons
- You may need to learn how to use the platform effectively, especially if
they are unfamiliar with web scraping and browser profiles. - It offers only a limited number of proxy options, which may not be suitable
if you require more variety and flexibility.
Import.io
Import.io is a web scraping service allowing users to extract data from websites
without coding or technical knowledge.
Features
- It uses machine learning algorithms to automatically detect and extract
relevant data from web pages, saving you time and effort. - It integrates with popular data visualization and analysis tools like Google
Sheets, Tableau, and Excel. - You can customize the data extraction process by selecting specific fields
or setting up filters.
Pros
- It is easy to use and navigate, even if you don’t have technical knowledge.
- Import.io offers a variety of data export options, including CSV, Excel,
JSON, and API.
Cons
- It may not be as flexible or customizable as other web scraping services.
- Import.io’s free plan has limitations on data extraction volume and export
options. - Its machine learning algorithms may not always accurately extract data,
requiring manual adjustment.
Octoparse
Octoparse is a powerful web scraping service that extracts data from websites
using advanced features such as conditional extraction, form filling, and
pagination handling.
Features
- Octoparse’s cloud-based solution allows you to extract data from websites
without installing any software or infrastructure. - You can export data in various formats, including CSV, Excel, HTML, JSON,
and MySQL. - Easy to use and navigate, with a visual workflow designer and a
drag-and-drop interface.
Pros
- It is a powerful tool for more flexibility in your web scraping projects.
- It’s a convenient option if you want mobility or scalability.
- Offers a free plan with basic features, making it accessible to individuals
and small businesses.
Cons
- Octoparse’s customer support may be limited, with no phone or live chat
options. You may have to rely on email support or the help center for
assistance. - Advanced features may require learning and familiarity with web scraping and
data extraction. - It offers fewer integration options than other web scraping services.
ParseHub
ParseHub is a web scraping service that helps users to extract data from
websites using advanced features such as support for JavaScript rendering,
conditional extraction, and data transformation.
Features
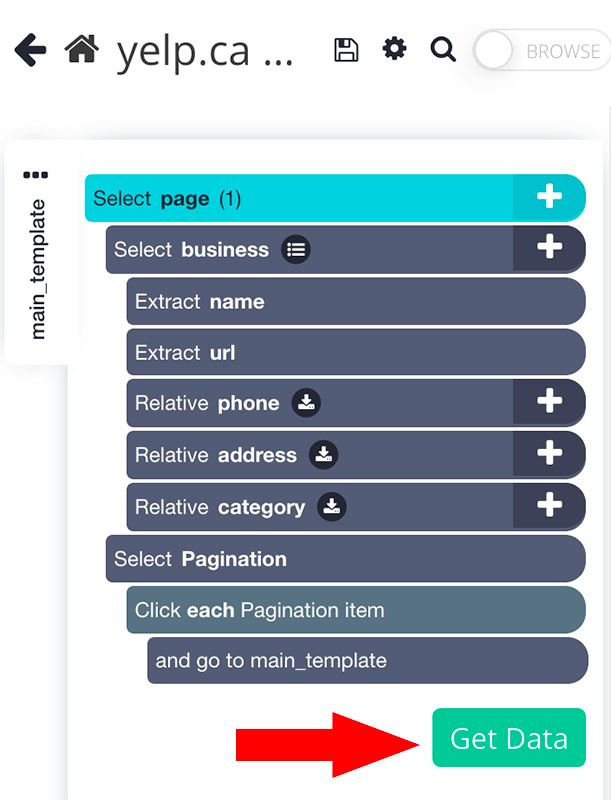
- ParseHub’s cloud-based solution allows you to extract data from websites
without installing software or infrastructure. - You can export data in various formats, including CSV, Excel, JSON, and API.
- ParseHub’s automation features allow you to schedule data extraction and
receive data directly in your preferred format or destination.
Pros
- It’s a powerful tool with flexibility and customization for your web
scraping projects. - ParseHub is a convenient option if you are needing mobility or scalability.
- Easy to get assistance when needed. If you are facing an issue, you can
interact with their team via phone, email, and chat support.
Cons
- Advanced features may require learning and familiarity with web scraping and
data extraction. - It offers a limited free plan with basic features and limitations on the
number of projects and pages you can scrape. - Pricing may be higher than other web scraping services on the market, making
it less accessible to individuals and small businesses.
WebHarvy
WebHarvy is an easy-to-use visual web scraping software used to scrape data from
any website.
Features
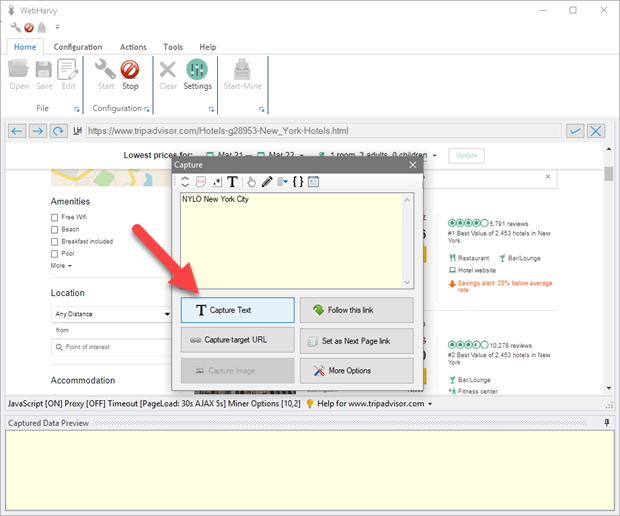
- It makes it easy to extract data without writing code or scripts.
- Automatically detects data patterns on a website and extracts the required
data accordingly. - Allows you to export data in various formats, including CSV, Excel, XML, and
SQL. - WebHarvy supports regular expressions for advanced data extraction.
Pros
- WebHarvy’s automatic data detection and regular expression support enable
fast data extraction. - Pricing plans start at very affordable figures, making it accessible to
individuals and small businesses.
Cons
- Features may be limited compared to other web scraping services on the
market, making them less suitable for complex projects. - Customer support is as comprehensive as some other web scraping services on
the market.
Other Web Scraping Services
Scraper API
It is a web scraping service that offers a proxy API solution for web scraping
at scale. With Scraper API, you can easily bypass website restrictions, IP
blocking, and CAPTCHAs by routing their requests through Scraper API’s proxy
network, which provides access to over 20 million residential IP addresses.
ScraperAPI also offers an automatic rotation of IP addresses and automatic retry
for failed requests, ensuring that users can scrape websites for data reliably
and efficiently. It supports various programming languages, including Python,
Ruby, and JavaScript, and offers multiple data export options, such as JSON,
CSV, and Excel.
Diffbot
It is an AI-powered web scraping service that offers advanced data extraction
capabilities. Diffbot uses machine learning algorithms to automatically identify
and extract structured data from websites, enabling users to extract product
data, article content, and other types of data without having to write complex
code. Diffbot offers customizable data export options, including JSON, CSV, and
Excel, making it easy to integrate extracted data into your workflows. Diffbot’s
web scraping service also offers enterprise-level security features, such as
encryption and access controls, ensuring your data is kept secure.
Zyte
It is a web scraping service that offers a range of tools and services to help
businesses extract and analyze data from the web. Formerly known as Scrapinghub,
Zyte’s web scraping solution is built on Scrapy, an open source web scraping
framework. Zyte offers two primary services: Scrapy Cloud, a cloud based web
scraping platform that allows users to deploy and run their web scraping spiders
at scale, and AutoExtract, an AI-powered data extraction API that can extract
data from websites without requiring any coding or configuration. Zyte’s web
scraping services support various programming languages, including Python, Ruby,
and JavaScript, and provide customizable data export options, including JSON,
CSV, and Excel.
Tips for Choosing the Right Web Scraping Tools or Services
Web scraping is a powerful tool for gathering data from the internet, but
choosing the right tool or service can be daunting. Here are some tips to help
you make the right choice:
Assess the specific requirements of the project
Identifying the project’s requirements is essential to choose a data scraping
tool or service. What type of data do you need to scrape? How frequently does it
update? What format do you want to export it in?
Consider scalability and growth needs
It’s important to consider scalability and growth needs when choosing a web
scraping tool or service. Will the project require scraping large amounts of
data in the future? If so, selecting a tool or service that can handle large
volumes of data and scale as needed is essential.
Evaluate budget and available resources
Budget and available resources are also important considerations when choosing a
data scraping tool or service. Some tools and services can be expensive, while
others are free or low-cost. Selecting a tool or service that fits your budget
and available resources is recommended.
Test multiple web scraping tools or services before making a decision
It’s always a good idea to test various web scraping tools or services before
making a final decision. This allows you to compare features, functionality, and
ease of use. You can try multiple options to choose the tool or service that
best meets your needs and preferences.
Conclusion
We have discussed how important it is to consider many factors before picking
the perfect web scraping tool or service for your project. Choosing the best one
can save you time, resources, and money, making things more accurate and
efficient. The internet is teeming with data, so it’s no surprise that the
demand for top-notch web scraping tools and services is skyrocketing. Whether
you’re an organization or just an individual, you’ve got to weigh the pros and
cons of your options based on your unique needs and requirements. With web
scraping becoming such a big deal in today’s digital landscape, it’s more
crucial than ever to invest in tools and services that get the job done. Stay
tuned for more and
Download GoLogin to
scrape even the most advanced web pages without being noticed!
FAQ
Which tools are used for web scraping?
BeautifulSoup, Scrapy, Selenium, and Requests. These tools provide
functionalities for fetching web pages, parsing HTML, interacting with
JavaScript, and extracting data efficiently. The choice of tool depends
on the specific requirements and preferences of the user.
What is the most popular web scraping tool?
Python ecosystem. It is known for its simplicity and flexibility in
parsing HTML and XML documents. BeautifulSoup provides a user-friendly
API that allows developers to navigate and search through the parsed
data easily. It is widely used for extracting data from websites and is
often a go-to choice for many web scraping projects.
What is web scraping best used for?
market research, price monitoring, content aggregation, sentiment
analysis, lead generation, and competitive analysis. It allows you to
gather large amounts of data from websites quickly and efficiently,
enabling you to gain insights, automate repetitive tasks, and make
informed decisions based on the extracted information.
Can you get banned for web scraping?
websites. Websites may have terms of service or usage policies that
prohibit scraping or unauthorized access to their data. To avoid getting
banned, it’s important to respect website policies, be mindful of the
scraping frequency, use proper user agent headers, and consider
utilizing web scraping proxies or rotating IP addresses.
What are web scraping services?
scraping as a service. These services typically involve professional web
scraping experts who use their knowledge and tools to extract specific
data from websites based on the client’s requirements. Web scraping
services can be useful for businesses or individuals who lack the
technical expertise or time to perform web scraping themselves and need
accurate and reliable data for their projects or analysis.
References to sources:
- Glez-Peña D. et al.
Web scraping technologies in an API world</a >
//Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797. - Sirisuriya D. S. et al. A comparative study on web scraping. – 2015.
- Diouf R. et al.
Web scraping: state-of-the-art and areas of application</a >
//2019 IEEE International Conference on Big Data (Big Data). – IEEE, 2019. –
С. 6040-6042. - Zhao B.
Web scraping</a >
//Encyclopedia of big data. – 2017. – Т. 1. - Rahm E. et al.
Data cleaning</a >: Problems and current approaches //IEEE Data Eng. Bull. – 2000. – Т. 23. –
№. 4. – С. 3-13. - Khder M. A.
Web Scraping or Web Crawling</a >: State of Art, Techniques, Approaches and Application //International
Journal of Advances in Soft Computing & Its Applications. – 2021. – Т.
13. – №. 3. - Richardson L.
Beautiful soup documentation</a >. – 2007. - Kouzis-Loukas D.
Learning scrapy</a >. – Livery Place : Packt Publishing, 2016. - Abiantoro D., Kusumo D. S.
Analysis of Web Content Quality Information</a >
on the Koseeker Website Using the Web Content Audit Method and ParseHub
Tools //2020 8th International Conference on Information and Communication
Technology (ICoICT). – IEEE, 2020. – С. 1-6. - Han S., Anderson C. K.
Web scraping for hospitality research</a >: Overview, opportunities, and implications //Cornell Hospitality
Quarterly. – 2021. – Т. 62. – №. 1. – С. 89-104.
Read more:


