
This post has been edited and updated on Jan 17, 2025.
There is a new way to jump over Cloudflare anti-bot detection with a new web scraping service: antidetect browsers.
If you google “Cloudflare bypass”, you will find hundreds of articles and Github resources explaining how to bypass Cloudflare (or sell a solution for doing it). The reason is pretty straightforward: Cloudflare Bot Management solution is one of the strongest and most used anti-bot protection used on the internet.

Are Common Web Scraping Tools Still Effective In 2025?
Yes, but with some nuances.
In 2025, the relevance of the common web scraping methods remains significant, but the world has certainly evolved due to advancements in technology and increased security measures. Methods like using headless browsers, smart/sneaker proxies, and CAPTCHA bypassing are still employed.
However, their effectiveness has been challenged by enhanced bot detection systems such as ever evolving Cloudflare’s machine learning algorithms and behavioral analysis techniques.
These systems are now way better equipped to identify and block scraping attempts that exhibit patterns typical of bots, necessitating a more sophisticated approach from scrapers.
What is Cloudflare Bot Management?
Cloudflare Bot Management is a suite of security tools designed to protect websites from malicious bots and automated attacks. It provides advanced protection against a wide range of bot threats, including credential stuffing, web bypasses, and account takeover.
Cloudflare Bot Management includes the Web Application Firewall (WAF). This helps to stop malicious traffic from reaching a website’s origin server. The WAF Cloudflare security measures use advanced machine learning algorithms to analyze traffic patterns and identify potential threats.
Another important feature of Cloudflare Bot Management is the ability of DNS bypass resolution for known good bots. This allows legitimate bots to access a website without being blocked by security measures.
Furthermore, Cloudflare Bot Management provides a range of security measures through its DNS records. With Cloudflare DNS IP addresses, users can enjoy a faster and more secure browsing experience. Cloudflare DNS is designed to protect users from phishing, malware, and other online threats.
Overall, Cloudflare Bot Management provides robust and comprehensive security solutions to protect websites from bot traffic. The safety measures described above are extremely hard to bypass. Website owners can ensure that their sites are protected against all types of bots and automated attacks.
Is Bypassing Cloudflare Really That Difficult?
– Yes.
Traditional security measures rely on IP blocking or CAPTCHAs. Cloudflare’s Bot Management solution uses advanced machine learning algorithms to analyze requests coming to the website. So, it’s able to naturally identify bots by interpreting their typical behavior patterns.
Here are some examples of what bots are very likely to do:
- make a large number of requests in a short period of time
- use a specific type of user agent or IP address
- have inconsistent/suspicious fingerprints.
Cloudflare’s Bot Management solution is also hard to bypass because it’s constantly taught to detect new types of web scraping bots. The company uses machine learning algorithms. This helps them to update their detection methods. This allows them to quickly identify and block new types of bots as soon as they appear.

Another stumbling point with Cloudflare is it being a highly customized solution. Methods that work for one website are likely to be useless for another one.
I previously posted about Cloudflare, providing three solutions for three different websites. However, only two of these solutions remain functional. During the past weeks, I’ve struggled to use Playwright with the Antonioli website to bypass Cloudflare. After a few pages I was blocked again, especially when the execution was running inside a VM on AWS.
So, the truth is – there’s no silver bullet against Cloudflare Bot Management. However, there are solutions that work well.
How does Cloudflare detect bots?
Cloudflare is a top-tier content delivery network (CDN) and cloud security company. They provide services to protect websites from online threats. These threats include bot attacks. Cloudflare uses several techniques to detect bots and prevent them from accessing websites.
Let’s touch on some of the methods that Cloudflare employs to identify bots.
- User-Agent Strings. These are pieces of text included in HTTP requests sent by web browsers or other clients to the web server. These strings generally contain information about the client’s operating system, browser type, version, and other relevant details.Cloudflare can identify the source of a request. It does this by examining the user-agent strings. These strings indicate whether the request comes from a browser or a bot. Bots often use generic or outdated user-agent strings, which can help Cloudflare identify them.
- IP Address Reputation (Trust). Cloudflare network maintains a database of IP addresses known for malicious activity, such as spamming, phishing, and distributing malware.Cloudflare can block or challenge requests from IP addresses with bad reputations (also known as IP trust). This makes it difficult for bad bots to extract data. CAPTCHA is used to challenge the requester.
- JavaScript Challenge. Cloudflare can use JavaScript challenges to verify whether a client is human or bot. Whenever a request is sent to a website protected by Cloudflare, the server responds by sending a piece of JavaScript code. This code must then be executed by the client. The client then returns the output of this code to the server.The server allows access to the site if the client correctly executes the JavaScript code. This signifies that the user is legitimate. The client must execute the JavaScript code correctly. If they fail to do so, or do not execute it at all, the server will assume they are a bot. Access to the site will then be denied.
- Rate Limiting. Another way that Cloudflare detects bots is by using rate limiting. This technique identifies patterns of behavior that are typical of bots.A typical example is sending a large number of requests within a short period. Cloudflare can then block or challenge these requests, forcing the requester to slow down.
- Browser Fingerprinting is a technique that identifies a device uniquely. It does this by analyzing different attributes of the device, such as screen size, browser type, and installed plugins. Cloudflare can use this technique to create a fingerprint of each device that connects to a protected website.If the same fingerprint appears repeatedly, Cloudflare may assume that it is a bot. Cloudflare can also use browser fingerprinting to detect bots that change their user-agent strings frequently. Since the other attributes of the device remain the same, Cloudflare can use them to identify the requester as a bot.
- Machine Learning (ML) Algorithms: Cloudflare employs machine learning algorithms to analyze patterns in web traffic and identify bots accurately. These algorithms can learn how to recognize bots based on features such as the number and frequency of requests, the types of resources requested, and the IP addresses of the requesters. Cloudflare’s ML algorithms can also adapt to new threats quickly. A new type of bot attack can emerge. Algorithms can learn from examples of previous attacks. They can then adjust their criteria for detecting bots.
Cloudflare combines various techniques to accurately identify bots that try to access protected websites. They block or challenge these bots before they can cause any harm.
Cloudflare active bot detection techniques
Here are some of the active bot detection techniques used by Cloudflare to provide top-notch bot protection. Spoiler: they have evolved significantly.
Cloudflare has invested heavily in machine learning and AI in recent years. This has enabled the creation of more sophisticated algorithms for detecting bots.
Cloudflare’s anti-bot measures have likely adapted as the threat landscape evolves. New types of bot attacks are emerging, and Cloudflare is staying ahead of these threats.
They have made significant improvements to their rate limiting and event tracking systems. Additionally,
CAPTCHAs
These are an effective way to prevent automated requests from bots while allowing real human users to access the website. Cloudflare uses several types of CAPTCHAs, such as image-based CAPTCHAs and reCAPTCHA. These help verify that the requester is a real human user.
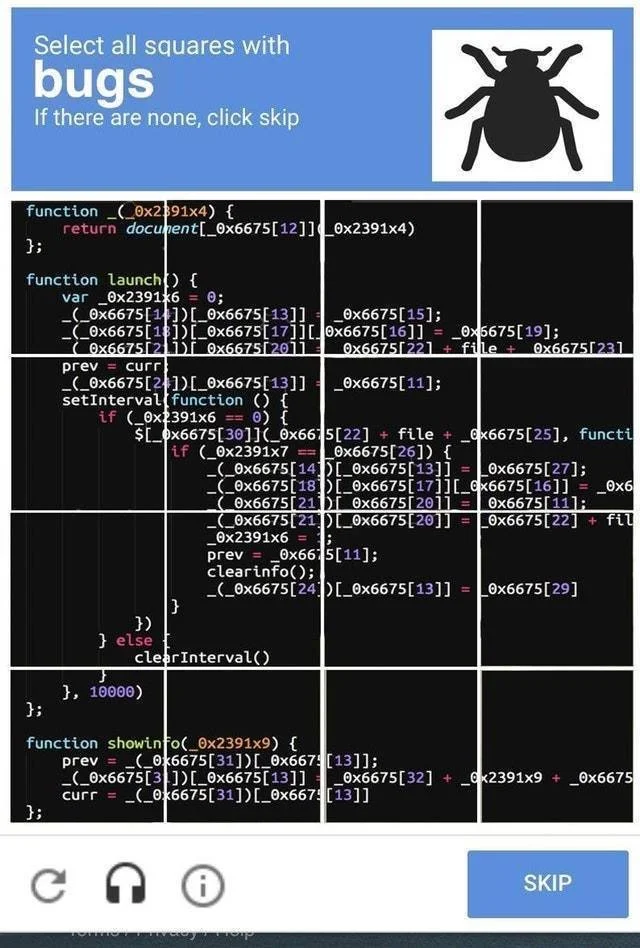
Source: Reddit
These challenges require users to perform actions that bots cannot easily replicate. Some of these are identifying objects in images or solving simple math problems. If the requester passes the challenge, they can access the website. Otherwise, they are blocked from accessing the site.
Canvas Fingerprinting
This technique captures unique attributes of a user’s browser. Examples include the type of graphics card and rendering engine. These attributes create a unique “fingerprint” that can be used to identify users across different websites.
Cloudflare uses canvas fingerprinting to detect bots that use fake user-agent strings to hide their identity. By analyzing the canvas fingerprint of each request, Cloudflare can determine whether it comes from a legitimate user or a bot.
Event Tracking
It’s used to monitor user interactions with a website, such as clicks, page views, and form submissions. Cloudflare anti bot protection uses event tracking to analyze patterns of user behavior and detect anomalies that may indicate bot activity.
For example, if a large number of requests come from the same IP address within a short period, Cloudflare may assume that it is a bot and block the requests. By using event tracking, Cloudflare can accurately distinguish between legitimate user requests and bot requests.
Environment API Querying
API querying is used to collect information about the client’s environment, such as the operating system, browser type, and screen resolution. Cloudflare uses this technique to identify bots that use fake user-agent strings or other methods to mask their identity.
By analyzing the environment variables of each request, Cloudflare can detect patterns of behavior that are typical of bots. Cloudflare may identify and block requests from bots if there is a large number of requests with the same screen resolution.
IP Address Reputation (Trust).
Cloudflare maintains a database of IP addresses known for malicious activity, such as spamming, phishing, and distributing malware. Cloudflare can block a request from an IP address with a bad reputation, or challenge the requester with CAPTCHAs.
Cloudflare can use IP address reputation to quickly identify malicious sources. This protects websites from bot attacks.
Machine Learning Algorithms
These are used to analyze patterns in web traffic and identify bots accurately. Algorithms can learn to identify bots. They do this by looking at features, such as:
- The number and frequency of requests
- The types of resources requested
- The IP addresses.
![]()
Cloudflare’s ML algorithms can also adapt to new threats quickly. When a new type of bot attack emerges, the algorithms can learn from examples of previous attacks and adjust their criteria for detecting bots accordingly.
While Cloudflare’s anti-bot techniques are effective at detecting and preventing many types of bot attacks, it is still possible for determined attackers to bypass them. However, the difficulty of bypassing these techniques will depend on several factors, including:
- the sophistication of the attacker,
- the specific techniques used by Cloudflare
- and the security measures implemented by the website owner.
For example, CAPTCHAs can be bypassed using automated tools or by outsourcing the task to human workers in low-wage countries. Similarly, canvas fingerprinting can be circumvented by using virtual machines, headless privacy browsers like GoLogin or other methods to hide the device’s real hardware configuration.
However, sophisticated attackers may find it more challenging to bypass some of the more advanced techniques used by Cloudflare. Machine learning algorithms and environment API querying are harder to override. These techniques are designed to detect subtle patterns of behavior. It is difficult for bots to replicate these patterns, which makes them more resistant to attack.
Environment API Querying: unique, but normal
Environment API querying is a technique used by Cloudflare to identify bots by analyzing various attributes of the client’s device. These include operating system, browser type, and screen resolution. It can be difficult to bypass this technique since it relies on collecting information about the device itself.
Possible methods to bypass Environment API querying might include:
- virtual machines
- privacy browsers managing fingerprints
- devices with fake attributes
- using an anonymity service that alters or hides the real device information.
However, these methods may not always be effective and could potentially trigger other anti-bot measures employed by Cloudflare. Staying normal on the web is extremely difficult. Even one parameter altered at random will immediately get you detected by anti-bot software. It’s the normality you’re looking for.
Another potential method to bypass Environment API querying is to modify the HTTP request headers sent by the bot client. That includes the user-agent string and other relevant device information. However, sophisticated bots may have the ability to mimic these headers accurately. They are hard to detect through this technique alone.
Everything Matters
Ultimately, the effectiveness of Cloudflare’s anti-bot techniques will depend on how well they are implemented and configured. Website owners who use Cloudflare IP addresses must ensure that they have set up their security measures correctly. These include configuring rate limiting and firewall rules, enabling SSL encryption, and monitoring their logs for suspicious activity.
By taking a proactive approach to security, website owners can help ensure that their sites remain protected against bot attacks.
Way 1: bypass Cloudflare CDN by calling the origin server
Cloudflare provides DDos protection against bot attacks. It acts as a proxy between the user and the server to hide the original IP address. This can make it difficult for web scrapers to access data from websites that are protected by Cloudflare. However, there are ways to bypass Cloudflare by calling the origin server directly.
Find the origin IP address
The first step in bypassing Cloudflare is to find the origin IP address of the website you want to scrape. This can typically be done by performing a DNS lookup on the website’s domain name. You can use the “nslookup” command in a terminal to perform the DNS lookup. For example:
nslookup example.com
This will return the IP address of the website’s Cloudflare proxy. Find the origin IP address by using a tool like “ping” or “traceroute.” These tools will determine the path from your computer to the origin server. For example:
ping example.com
This will return the IP address of the origin server.
Request data from the origin server
Once you have the origin IP address, you can send HTTP requests directly to the origin server to bypass Cloudflare. You can do this using a tool like cURL or by writing a custom script in Python or another programming language.
To make the request, you will need to include the origin IP address in the URL of your request, like so:
http://[origin IP]/path/to/resource
You will also need to include the appropriate headers in your request such as the “User-Agent” header. These help mimic the behavior of a normal web browser. You can also include other headers, such as “Referer” and “Accept-Language”, to make your request appear more legitimate.
Way 2: override Cloudflare waiting room
One of the security features offered by Cloudflare is the “waiting room” page, also known as the “I’m Under Attack” mode. When a user visits a website protected by Cloudflare, the user’s IP address is first checked by Cloudflare’s security measures.
If the IP address is flagged as potentially harmful, the user is redirected to a waiting room page with a challenge. The challenge typically involves solving a CAPTCHA or completing a challenge that requires human-like interaction with the page. It might be clicking on a specific element or dragging and dropping objects on the page.
 We’ve met this screen a thousand times.
We’ve met this screen a thousand times.
The waiting room page is designed to protect websites from various types of attacks. Some of these are DDoS (Distributed Denial of Service) attacks, brute force attacks, and web scraping attempts. Bots and other automated tools are unable to complete the challenge presented by the waiting room page. This effectively blocks them from accessing the website.
To minimize the impact on legitimate users, Cloudflare allows website owners to customize the waiting room page. It’s done to match the branding of their website and to adjust the sensitivity of the security measures.
To minimize the impact on legitimate users, Cloudflare allows website owners to customize the waiting room page to match the branding of their website and to adjust the sensitivity of the security measures.
How long does it take to bypass Cloudflare waiting room?
The times can vary depending on the complexity of the challenge and the user skill level. In some cases, the waiting room can be bypassed within a few minutes. In harder cases it may take several hours or even days.
Factors that can affect the time it takes to bypass the waiting room include:
- the use of automated tools
- the type of challenge used by Cloudflare
- the level of security measures implemented by the website being accessed.
Some websites may have more robust security measures in place, such as additional check layers or complex JavaScript challenges. This can make the bypassing more difficult and time-consuming.
Experienced developers and security professionals have an advantage when trying to bypass the waiting room. They are familiar with the technologies used by Cloudflare and the underlying web technologies. This helps them to do it more quickly and efficiently than those with less experience.
Reverse engineering the Cloudflare JavaScript challenge
Reverse engineering Cloudflare JavaScript challenge can be a daunting task, but it is possible with the right tools and techniques. In this guide, we will cover the steps involved in reverse engineering Cloudflare JavaScript challenge, with code examples.
Step 1: Check out the network log
The first step is to open the browser’s network log and examine the requests and responses. Look for any requests that return a 503 error code or have a “cf-chl-bypass” cookie. These requests are usually the ones that trigger the Cloudflare JavaScript challenge.
import requests url = "https://example.com" response = requests.get(url) print(response.content)
The code sends an HTTP GET request to the target website URL using the requests library. The response content is printed to the console with the HTML content of the website and any loaded scripts.
Step 2: Debug the Cloudflare JavaScript challenge script
Next, open the browser’s debugger and look for the JavaScript file responsible for the challenge. This file is usually named something like “cf_chl.js” or “challenge.js”. Set a breakpoint at the beginning of the script to stop the execution and allow for easier analysis.
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Add print statements to debug the JS code
def challenge_callback(solved_token):
print("Solved token:", solved_token)
context = {
"success": False,
"callback": challenge_callback
}
exec(js_code, context)
- This code sends an HTTP GET request to the target website URL using the requests library.
- The response content is parsed using the BeautifulSoup library to find the script tag that contains the Cloudflare challenge script.
- The script tag’s source URL is extracted and another HTTP GET request is sent to retrieve the contents of the script.
- The retrieved script contents are executed using the exec function. A custom context is passed in to allow for callback functions to be defined.
- A sample callback function is defined and passed in to the custom context. It will be called if the Cloudflare challenge is successfully solved.
![]()
Step 3: Deobfuscate the Cloudflare JavaScript challenge script
The Cloudflare JavaScript challenge script is usually obfuscated to prevent reverse engineering. Use a tool like JSNice or Unminify to deobfuscate the script and make it easier to read. Alternatively, you can use the built-in JavaScript beautifier in the browser debugger.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
def challenge_callback(solved_token):
print("Solved token:", solved_token)
context = {
"success": False,
"callback": challenge_callback
}
exec(deobfuscated_code, context)
- This code is the same as Step 2 up to retrieving the challenge script contents.
- The jsbeautifier library is used to deobfuscate the script contents and make it more readable.
- A sample callback function is defined and passed in to the custom context. It will be called if the Cloudflare challenge is successfully solved.
Step 4: Analyze the deobfuscated script
Now that the script is deobfuscated, it’s time to analyze it. Look for functions that generate the challenge token or verify the response.
These functions are usually named something like “gen_challenge” or “verify”. Examine the script for recurring patterns or algorithms. If found, these can be used to create the correct challenge token or response.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
# Extract relevant code snippets
challenge_function = ""
challenge_callback = ""
for line in deobfuscated_code.split("
"):
if "function " in line and "challenge_" in line:
challenge_function += line + "
"
elif "success:!1," in line:
challenge_callback += line + "
"
# Create a custom environment for executing the JS code
class ChallengeEnvironment:
def __init__(self, callback):
self.callback = callback
self.success = False
def setTimeout(self, func, delay):
func()
def atob(self, str):
return bytes(str, "ascii").decode("base64")
# Execute the challenge function with the custom environment
context = ChallengeEnvironment(challenge_callback)
try:
exec(challenge_function, context.__dict__)
except Exception as e:
print("Error:", e)
if context.success:
print("Challenge solved successfully!")
else:
print("Failed to solve the challenge.")
This code is the same as Step 3 up to deobfuscating the challenge script contents.
- Relevant code snippets are extracted from the deobfuscated script, including the challenge function and the success callback function.
- A custom environment class is defined to mimic the browser environment and allow for the challenge script to execute properly.
- The challenge function is executed with the custom environment and any errors are caught and printed to the console.
- If the success callback function is called with the success flag set to True, then the Cloudflare challenge was successfully solved.
Way 3: Use Cloudflare solvers
The effectiveness of open source Cloudflare solvers can vary depending on the specific challenge presented by Cloudflare. In general, some solvers are more effective than others at solving different types of challenges.
For example, Cfscrape and cloudscraper are two popular Python libraries that can be effective at solving basic JavaScript challenges. They both utilize headless browsers to mimic a user’s interaction with the Cloudflare ddos challenge page. Simple challenges can often be dealt with easily.
FlareSolverr spins up a headless browser, providing the user with the cookies and other data needed to solve the challenge. This approach can be more effective at solving more complex challenges. Here, user interacts with the challenge page in a more realistic manner.
 FlareSolverr
FlareSolverr
cloudflare-scrape and cloudflare-iuam-solver are two other Python libraries that utilize headless browsers to solve Cloudflare challenges. While they are less popular than some of the other solvers, they can still be effective at solving simple challenges.
Finally, CloudflareSolverRe is a newer solver that works by analyzing the Cloudflare challenge page. It automatically generates a solution using regular expressions. This approach can be highly effective at solving simple challenges. More complex challenges that require more nuanced solutions can make it struggle.
Way 4: Leverage headless browsers
Headless browsers mimic the real user behavior in a normal browser. They allow the user to execute JavaScript, handle cookies, and interact with the website as a normal user would. This makes it more difficult for Cloudflare to detect and block automated traffic. There the traffic appears to be coming from a legitimate user rather than a bot.
One popular headless browser for bypassing Cloudflare is Puppeteer, a Node.js library that provides a high-level API for controlling the headless Chrome browser. Puppeteer can be used to access web data protected by Cloudflare. It can solve the challenge with JavaScript and extract the cookies needed to avoid future challenges.
Another option is Selenium, a widely-used framework for automating web browsers. Selenium can be used to control headless versions of popular browsers like Chrome and Firefox, and can interact with websites in a way that closely mimics the behavior of a human user.
For more complicated tasks requiring browser fingerprinting, GoLogin can be used. Originally a privacy browser, it’s widely used for scraping in headless mode. GoLogin manages browser fingerprints with a custom solution. Multiple browser profiles can be run from one machine, all looking unique and normal to even most advanced websites.
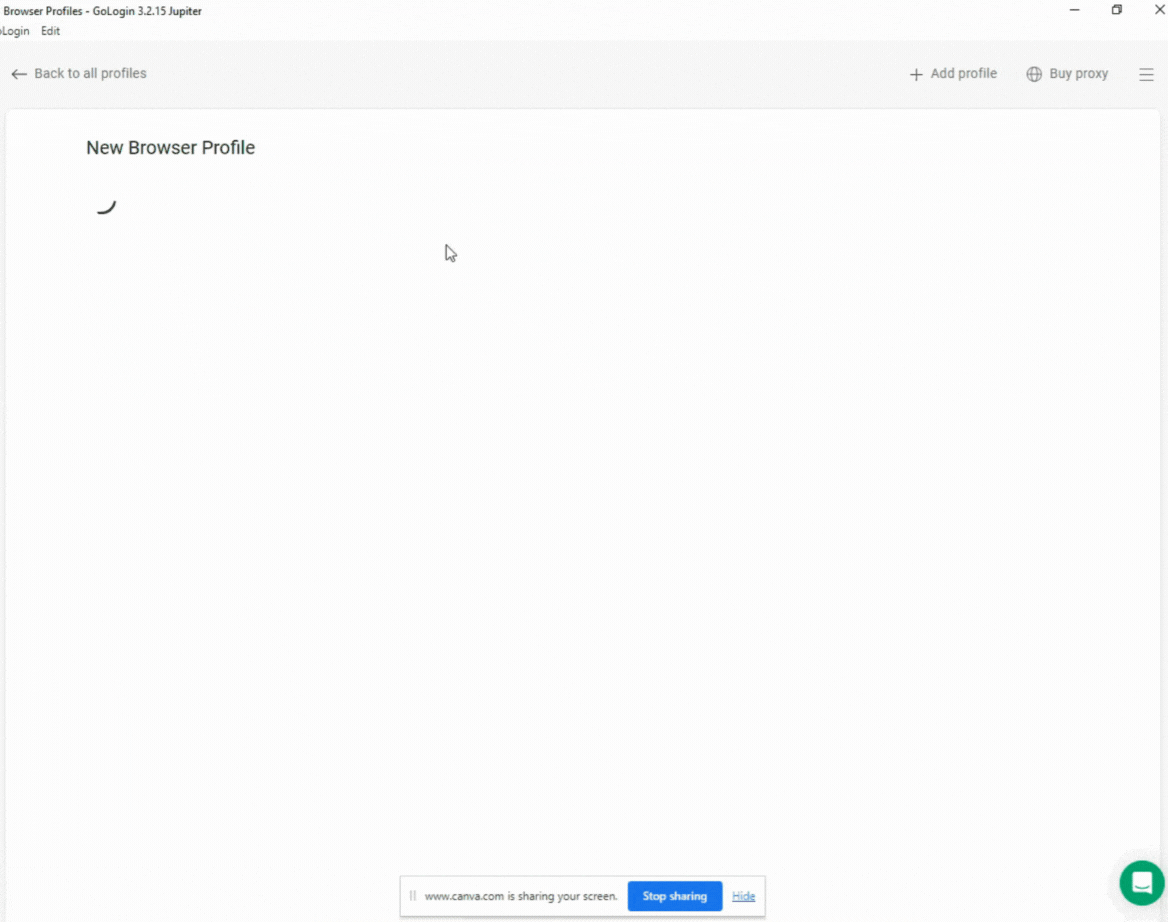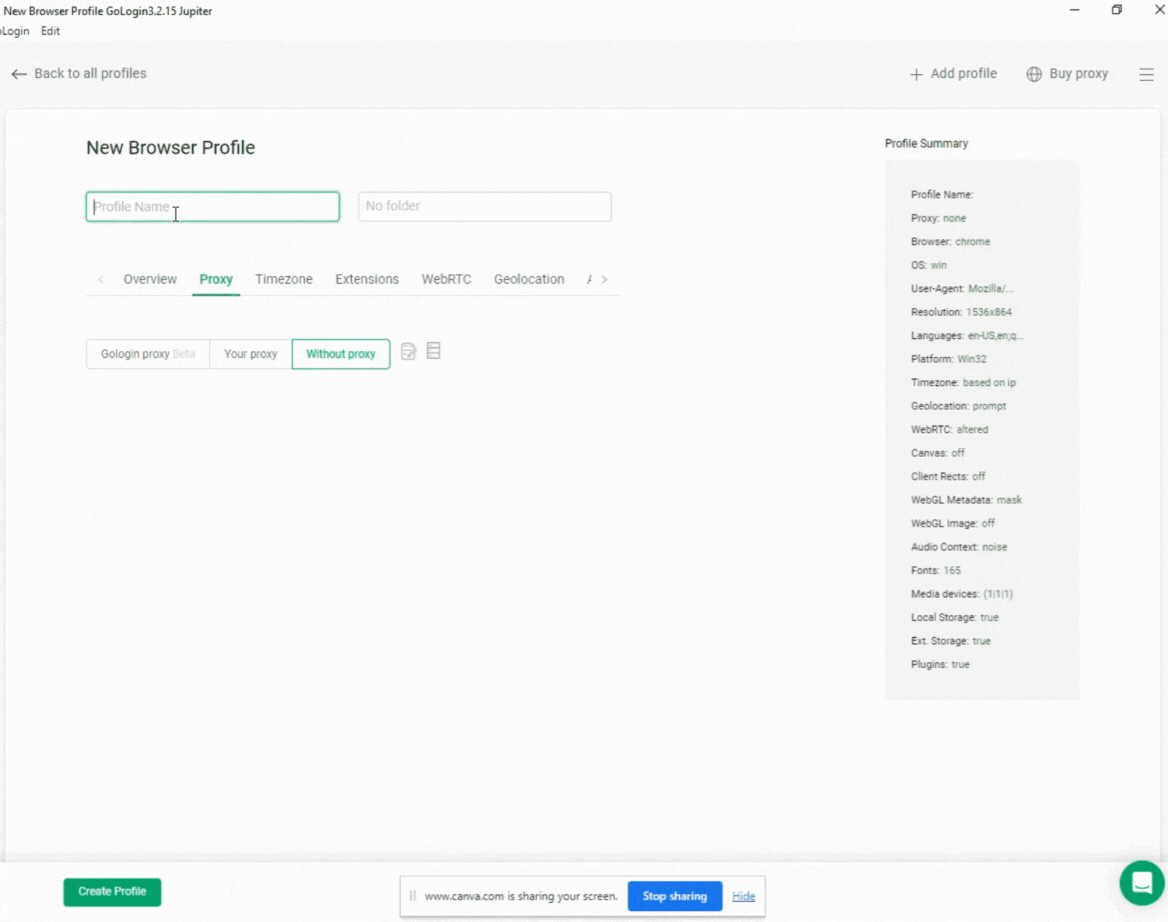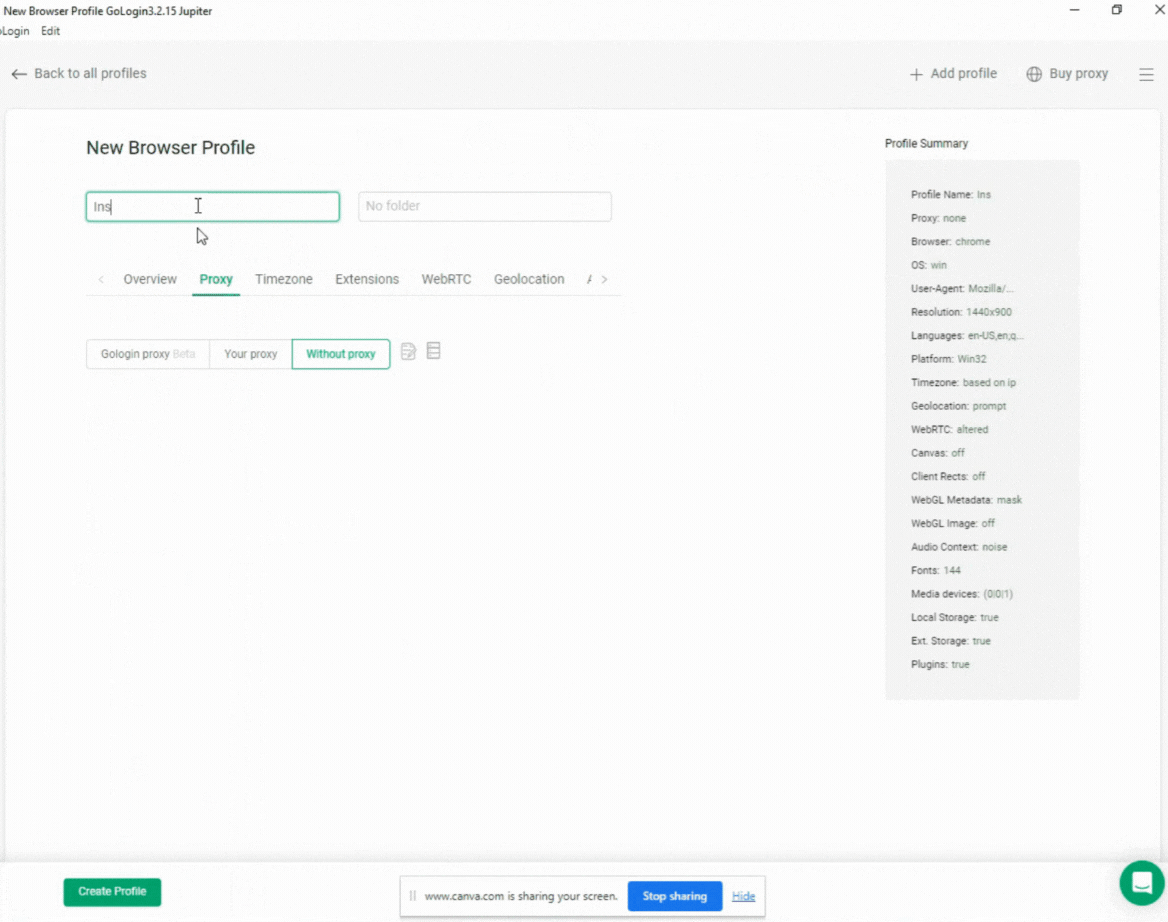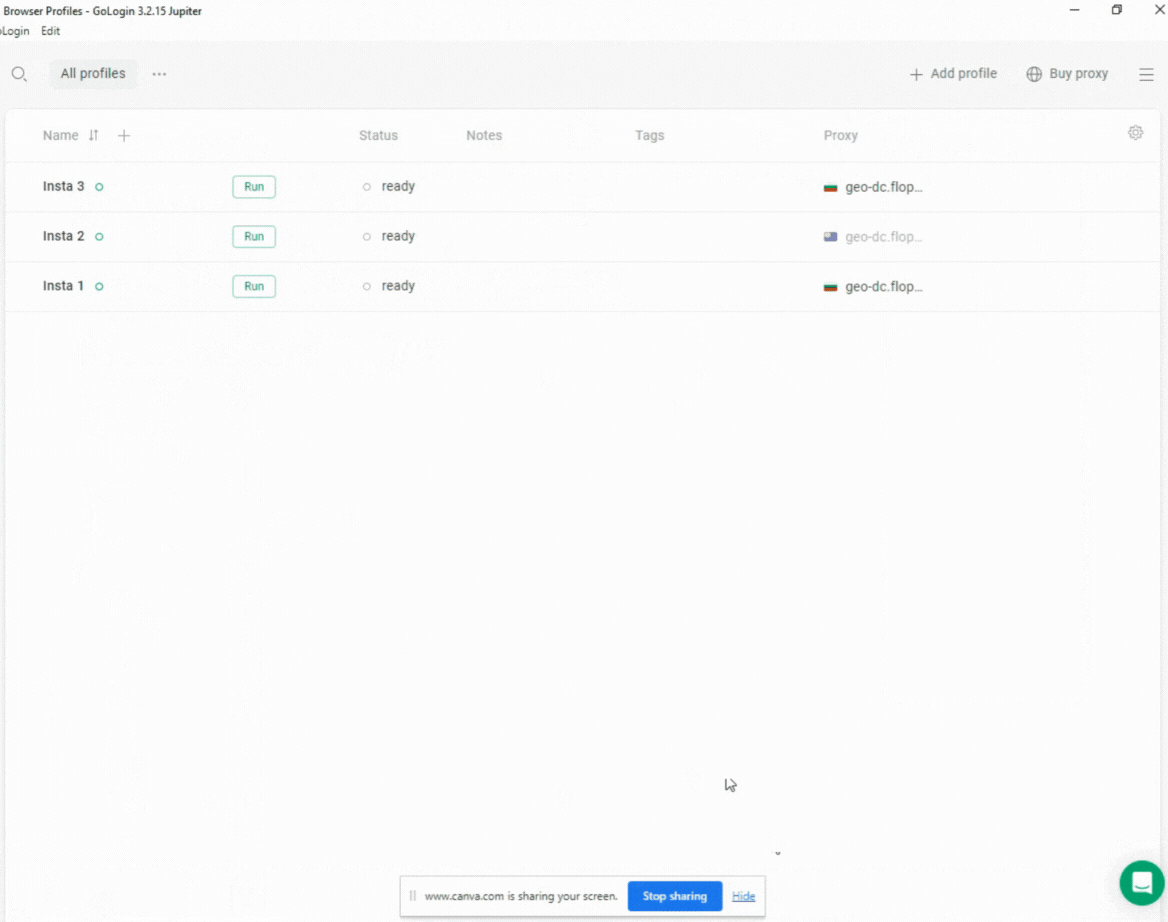 Setting up a browser profile in GoLogin
Setting up a browser profile in GoLogin
Headless browsers: pros and cons
One potential disadvantage of using headless browsers is that they require more resources than simpler solutions like Cloudflare solvers. Running a headless browser can be memory-intensive and can slow down the scraping process. It’s particularly seen when dealing with large amounts of data.
Another limitation is that headless browsers can be more complex to set up and use than other solutions. They require knowledge of programming and web development, and can be more difficult to use for non-technical users. However, you are likely tech savvy if you are already facing the challenge of scraping a highly protected website.
Headless browsers can be an extremely effective tool for bypassing Cloudflare. It’s important to weigh the pros and cons of using headless browsers against other solutions, and to consider factors:
- the amount of data being scraped
- the overall level of website protection
- the technical proficiency of the user
- the resources available for running headless browsers.
Way 5: Leverage a smart proxy to bypass Cloudflare
Smart proxy APIs are another effective way to bypass Cloudflare protection mechanisms. Smart proxy APIs are designed to route HTTP traffic through a pool of real residential IP addresses. This makes it more difficult for websites to detect and block automated traffic.
These APIs work by providing access to a large pool of real residential IP addresses. The API sends requests to these IP addresses, effectively masking the origin of the requests. This makes it harder for Cloudflare to identify and block automated traffic.
Examples
One popular smart proxy API is the Oxylabs Residential Proxies API. This API provides access to a pool of over 100 million residential proxies. This makes Oxylabs one of the largest smart proxy APIs available. The API is designed to be easy to use, with great documentation and support for popular languages like Python and Node.js.
To use the Oxylabs Residential Proxies API, you first need to sign up for an account and obtain an API key. Once you have an API key, you can use it to make HTTP requests through the API. The API will route your requests through a pool of residential IP addresses. This makes it more difficult for Cloudflare to detect and block your requests.
Another popular smart proxy API is the Luminati Proxy API. This API provides access to a pool of over 72 million residential proxies. A range of other features like geotargeting and browser fingerprinting is also there. The API is designed to be flexible and easily customized, with support for a wide range of use cases.
In some cases, smart proxy APIs are an effective way to bypass Cloudflare proxy protection mechanisms. By routing requests through a pool of real residential IP addresses, these APIs can help you evade detection.
Way 6: Scrape Google cache
Scraping Google cache is another technique that can be used to bypass Cloudflare. Google cache is a snapshot of a website taken by Google’s web crawler and stored in its cache. When accessing a website through Google cache, the request is directed to Google’s servers instead of the actual website. This can help bypass Cloudflare protection.
 Source: ProxyScrape
Source: ProxyScrape
So, start with a simple google search: look if the website you’re scraping has a cached version. You need to use a search query that includes the “cache” prefix followed by the URL you want to access.
This will display the cached version of the website in the search results – click on the “Cached” link to access. That very URL (without the “cache:” mark) might work for scraping.
However, it’s important to note that Google cache may not always have the most up-to-date version of the website. Certain elements, such as images, may not be displayed properly. Additionally, Google may block or limit access to its cache if it detects excessive scraping or unusual traffic patterns.
Way 7: Cloudflare CAPTCHA bypass
Captcha solving services can also be used to bypass Cloudflare’s JavaScript challenges. This is one of the most expensive ways to do the job (especially for bigger volume tasks). However, sometimes it’s the only way that actually works.
Services like 2Captcha use real humans to solve captchas quickly and efficiently. Many of them have APIs that can be integrated into scripts or programs. Simply sign up for an account and obtain an API key. Then, you can use the API to submit a captcha challenge and receive a response that contains the solved captcha.
 2Captcha
2Captcha
Bypassing Cloudflare’s JavaScript challenges requires capturing the challenge. After that, send it to the captcha solving service’s API. The service would then return the solved challenge, which you could use to bypass the challenge and access the protected website.
It’s important to note that using a captcha solving service may not always be reliable. The service may not be able to solve certain types of captchas or may take longer to solve them.
Way 8: Privacy Browsers For Web Scraping Protection
I’ve tried working with Playwright in different browsers and contexts, as well as on several cloud providers – no success whatsoever. So, I decided to give Playwright a try in an antidetect browser.
What Are Privacy Browsers?
Privacy browsers (also called multi accounting or antidetect browsers) are usually based on Chromium, but with features that enhance user privacy. Typically they create new fingerprints that look authentic to websites, protecting the real location of the user. This is the key difference from a classic Playwright or Selenium execution.
I’ll put it in simpler words. Using Playwright under Chrome, the server knows you’re using a genuine version of Chrome. It’s running from a Datacenter machine – because of its device fingerprint. With a privacy browser, you’re using a version of Chromium set up for maximum privacy.
It sets up a sophisticated connection profile that sends custom device fingerprints. So, even the most advanced website engines see you’re running the browser from a regular Mac. The fact you’re actually running from a server is not seen. Thus, your work is protected.
GoLogin
I needed to test if this solution could work. Between the several browsers available, I had to choose one with the following specs:
- Has a fully working free demo to test my solution
- Can quickly be integrated with Playwright, minimizing the impact on my production environment
- Has a Unix client for my production environment.
Given that, technically, any chromium-based browser could run with Playwright if the executable_path is specified in the following way
browser = playwrights.chromium.launch(executable_path='/opt/path_to_bin')
I’ve chosen GoLogin web scraping service because of all the features above. I also considered the fact I could create different profiles (each under different fingerprints), which I could use for my experiments.
The Configuration
After signing up, I created my first profile that mimics a Windows workstation. Then I downloaded the browser’s client and the python source code from their repository. It is needed for interacting with Playwright using their API.
Using the tests on amiunique.org we can see the differences between the Playwright Chrome from my Mac laptop and the one with a GoLogin profile.
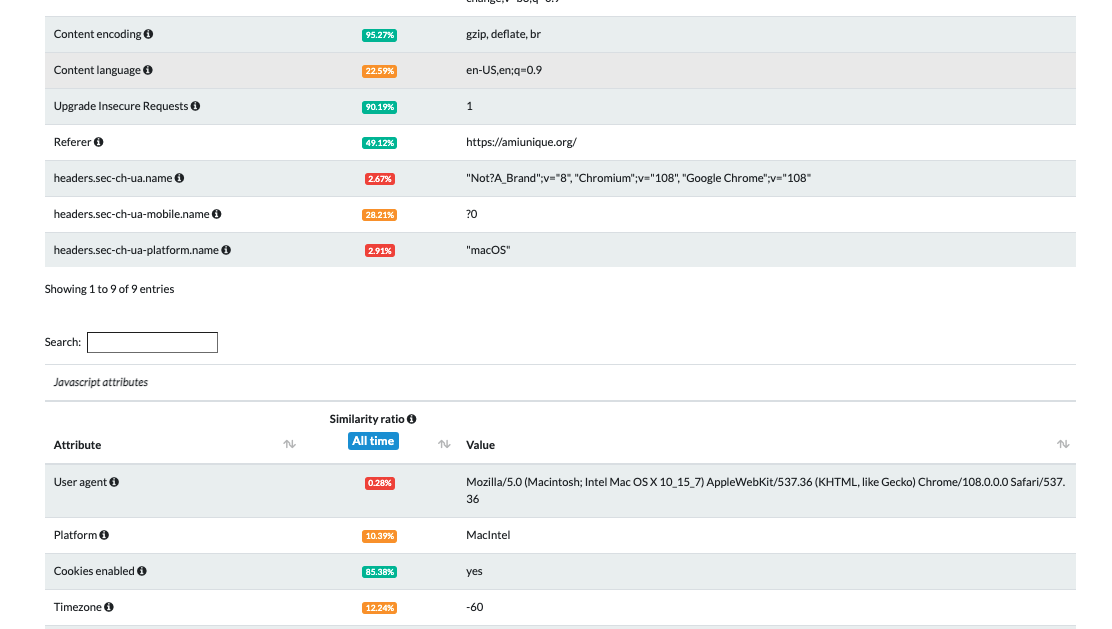
In the first case, we can see the Macintel platform and the macOS headers, which could be easily changed anyway.
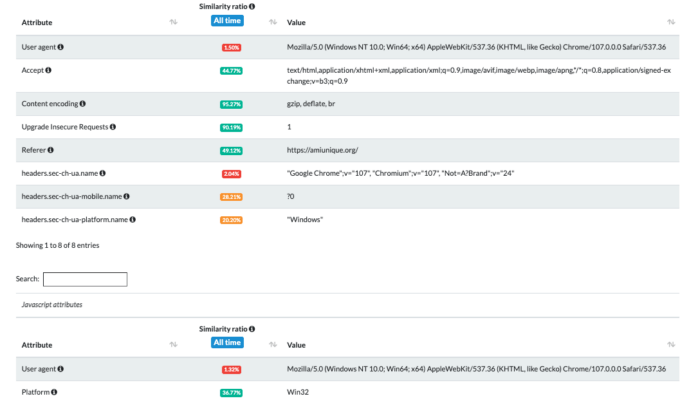
Using Gologin instead, I am imitating the execution from a Windows machine.
Some Considerations for Effective Web Scraping in 2025
The evolution of web scraping tools and methodologies in 2025 emphasizes the importance of ethical practices and compliance with legal standards. More and more websites implement strict security measures, including sophisticated CAPTCHAs and behavioral analysis.
Additionally, the rise of AI-driven detection systems means that scrapers must continually update their strategies to avoid detection. This includes utilizing more advanced techniques such as rotating user-agent strings, employing distributed scraping across multiple IP addresses, and leveraging AI tools that can mimic human browsing behavior more effectively.
Simply said, scraping and specifically bypassing Cloudflare is still possible in 2025 with old methods. However, it will be more difficult to keep it economically viable because of rising costs on every tool and method.
Bypassing Cloudflare In 2025: Emerging Tools and Methods
Based on our research of web scraping market and user experience, here are the top five techniques of bypassing Cloudflare to consider in 2025:
- Using Smart Proxies: Smart proxies are essential for bypassing Cloudflare as they can rotate IP addresses and manage requests effectively. This helps avoid detection by distributing traffic and mimicking human-like browsing patterns, making it harder for Cloudflare’s systems to flag the activity as bot-related.
- Headless Browsers: Puppeteer or Playwright allow scrapers to interact with web pages as a real user would. These tools can execute JavaScript, handle dynamic content, and respond to Cloudflare’s challenges, such as JavaScript checks and CAPTCHAs, which makes them a popular choice for bypassing security measures.
- Cloudflare Solvers: Utilizing specialized services or tools that can solve CAPTCHAs and other challenges presented by Cloudflare is another effective method. These solvers can automate the process of completing CAPTCHAs, allowing scrapers to gain access without manual intervention.
- Directly Accessing the Origin Server: If the origin server’s IP address can be discovered, scrapers can send requests directly to it instead of going through Cloudflare’s proxy. This method involves performing DNS lookups or using tools like traceroute to find the origin IP, enabling access without triggering Cloudflare’s defenses.
- Antidetect Browsers: Browsers such as GoLogin mask digital fingerprints by altering browser attributes and behaviors that could reveal scraping activities. GoLogin allows users to create multiple profiles with different settings, making it more challenging for Cloudflare to identify automated requests based on fingerprinting techniques.
Final tips on bypassing Cloudflare passive and active bot detection
These are some general tips for cases when nothing works at all. There are times when you’re simply experimenting with new ways and combining existing ones.
Bypassing Cloudflare Passive Bot Detection
- Disable JavaScript: prevent Cloudflare from gathering this information and bypass this detection mechanism. However, this may not be suitable for all use cases, as some websites rely heavily on JavaScript for their functionality.
- Use a Proxy with JavaScript Rendering: Cloudflare’s passive bot detection can also identify bots that do not execute JavaScript. By using a proxy service that supports JavaScript rendering, you can bypass this detection mechanism. A proxy service that supports JavaScript rendering will run it on the server and return the page to the client.
- Use a Web Scraping Framework: Cloudflare’s passive detection can also identify bots that do not behave like a real user. By using a web scraping framework that can mimic the behavior of a real user, you can bypass this detection mechanism.
Bypassing Cloudflare Active Bot Detection:
- Change User Agent: by changing your user-agent string to mimic a browser, you can bypass this detection mechanism. You can use the User-Agent Switcher extension for Chrome or Firefox to quickly switch between user-agent strings.
- Rotate IP Addresses: cloudflare’s active bot detection can also identify bots based on their IP addresses. By rotating your IP addresses, you can bypass this detection mechanism. You can use a proxy service or a VPN to rotate your IP addresses. The Tor network is another option, but it may not be suitable for all use cases.
- Use a Headless Browser: Cloudflare’s active bot detection can also identify bots based on their browsing behavior. By using a headless browser, you can mimic the browsing behavior of a real user and bypass this detection mechanism.
Headless browsers are automated browsers that can be controlled via a programming interface. Some popular headless browsers include Puppeteer, Selenium, GoLogin and Playwright.
Recap FAQ
- What activity is considered suspicious by Cloudflare?
Cloudflare considers activities like excessive request rate, accessing resources that don’t exist, requests from blacklisted IP addresses. Many other patterns are deemed suspicious by their algorithms as potential bot activity. - What is the most common method to bypass Cloudflare?
There is no one-size-fits-all answer to this question. It depends on the specific Cloudflare protections in place and the attacker’s resources and goals. Some commonly used methods include solvers, headless browsers like Puppeteer, and using proxies or smart proxy APIs. - Is it possible to bypass Cloudflare?
Yes! Use combinations of various methods: using solvers, headless browsers, captcha services, smart proxy APIs, scraping Google cache, etc.
Bypassing Cloudflare for scraping can be quite difficult. Their system evolves all the time and there is no simple solution against it.
However, there is always a golden key to even the strongest lock out there. Web scraping is an extremely powerful tool. It’s important to use it ethically and with respect for the websites you scrape.
You should never scrape more data than you need. With that in mind, happy scraping! Don’t give up on your scraping projects, be ready to learn, look for new insights – and you will reach success!
Part of this article was kindly provided by Pierluigi Vinciguerra, web scraping expert and founder of Web Scraping Club. Follow this link to see the original post.
Read Also: Web Scraping Tools and Services: A Comprehensive Review
Read this article in Portuguese: Como Burlar a Proteção de Bot do Cloudflare? Serviço de Web Scraping em 2023
References:
- Graham-Cumming J. Cloudflare outage on July 17, 2020. – 2020.
- Dewi Estri J. H., Umar R., Riadi I. Implementation of cloudflare hosting for speeds and protection on the website //Universitas Ahmad Dahlan. – 2019.
- Stephani K., Goldstein D. DNS study of transient disturbance growth and bypass transition due to realistic roughness //47th AIAA Aerospace Sciences Meeting Including the New Horizons Forum and Aerospace Exposition. – 2009. – С. 585.
- Böttger T. et al. An Empirical Study of the Cost of DNS-over-HTTPS //Proceedings of the Internet Measurement Conference. – 2019. – С. 15-21.
- Dickey J. Instant CloudFlare Starter. – Packt Publishing Ltd, 2013.

