On your journey to mastering web scraping, you will face many challenges like captchas, anti-bot measures, IP blocking, rate limiting, and more.
Although, you don’t need to be scared or discouraged by that!
This article will cover common challenges you will face while web scraping and how you can work your way around them. We’ll also go over real-world use cases of web scraping and build some cool projects together!
Note: we recommend checking out the previous two articles on the intro to web scraping and web scraping with Python to learn more.
- The fundamental tools, techniques, and best practices for web scraping
- Introduction to Python as a powerful language for web scraping
- Web Scraping Tools and Services: A Comprehensive Review

Common Challenges in Web Scraping
First, we’ll go over common web scraping challenges. These include:
- Dynamic content
- Captchas and anti-bot measures
- Rate limiting and IP blocking
1. Dynamic Content
What is it?
Websites that use dynamic content automatically change their content based on user behavior, time, activity, and many other external factors.
Social media sites like Netflix, Twitter, Facebook, and Instagram use dynamic content to personalize content to match your interests.
This can present a challenge while you’re web scraping.
Why?
Because these websites use JavaScript in the browser/server to render the website instead of plain old HTML.
How to identify a dynamic website?
Here’s how you can identify a dynamic website (we’ll use YouTube in this example):
Step 1) Inspect the website (Ctrl + Shift + C, Cmd + Opt + I).
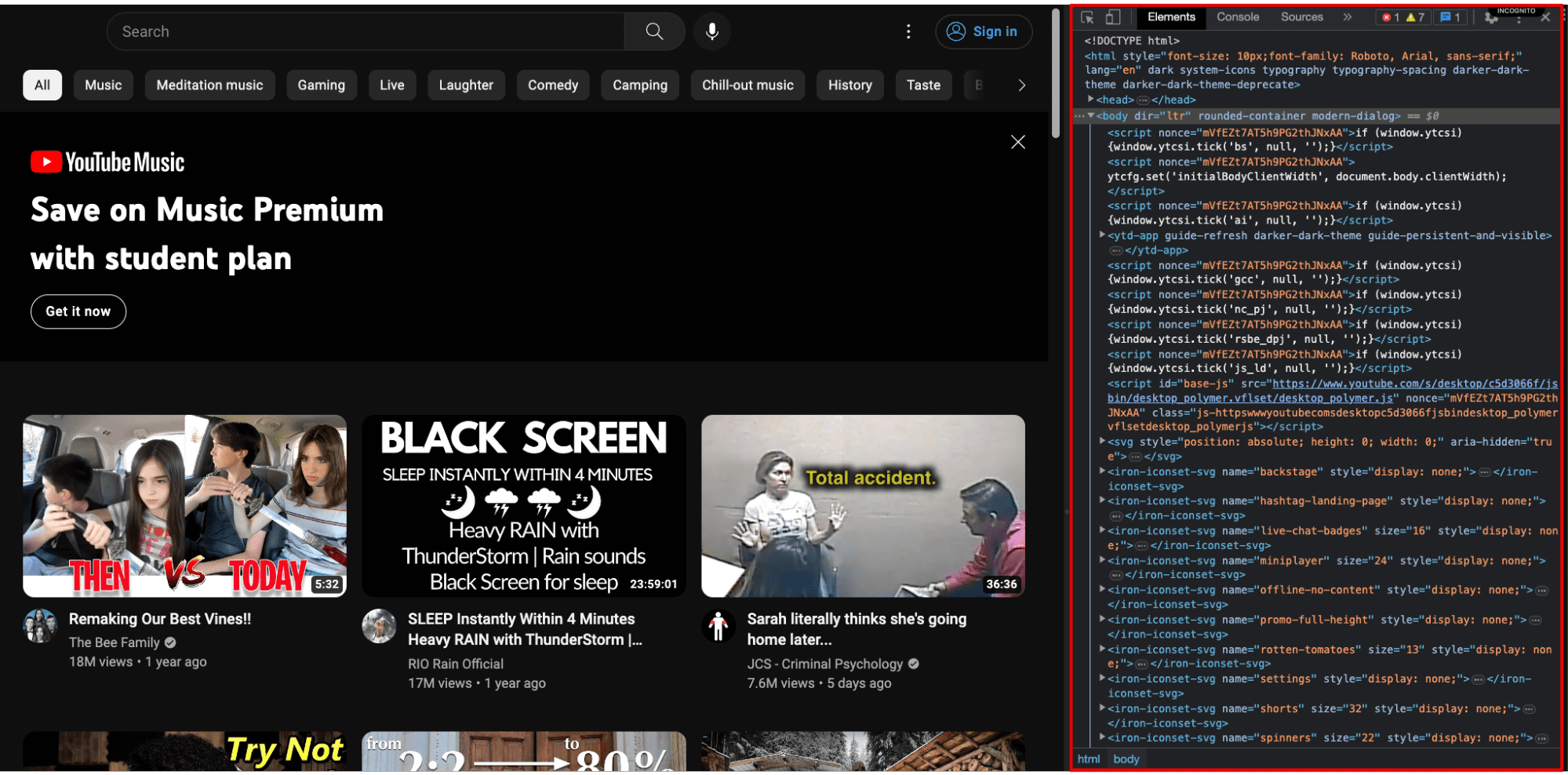 Step 2) Press Cmd + Shift + P (Mac) or Ctrl + Shift + P (Windows).
Step 2) Press Cmd + Shift + P (Mac) or Ctrl + Shift + P (Windows).
Step 3) Type in ‘Disable Javascript’ and select that.
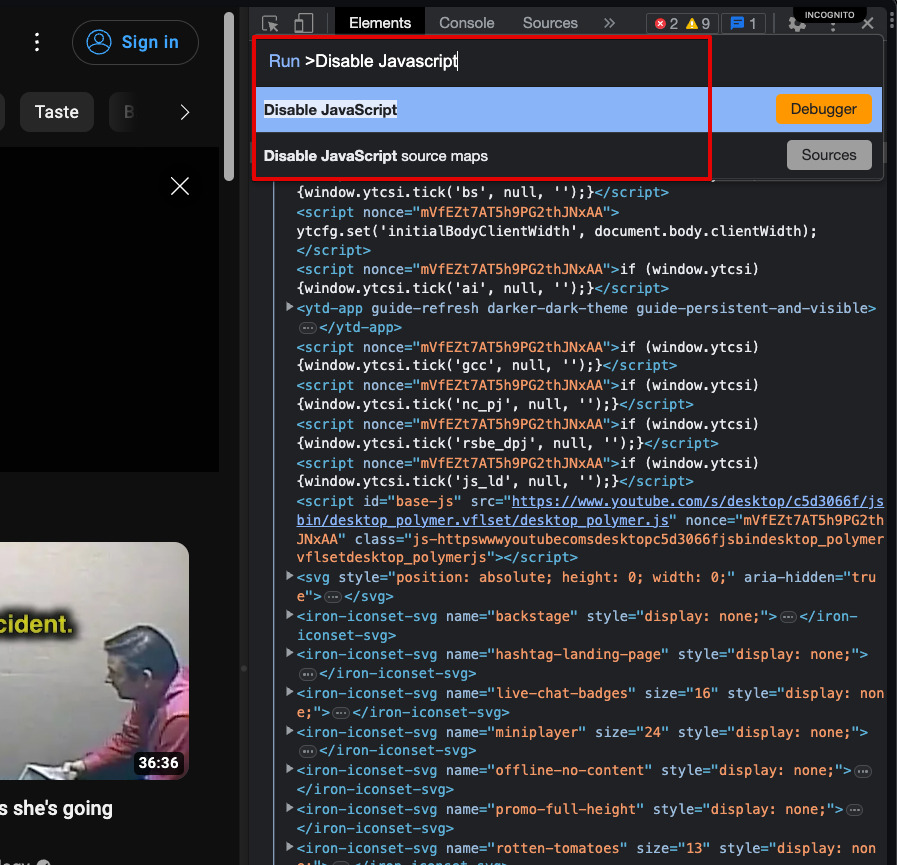
Step 4) Refresh the page.
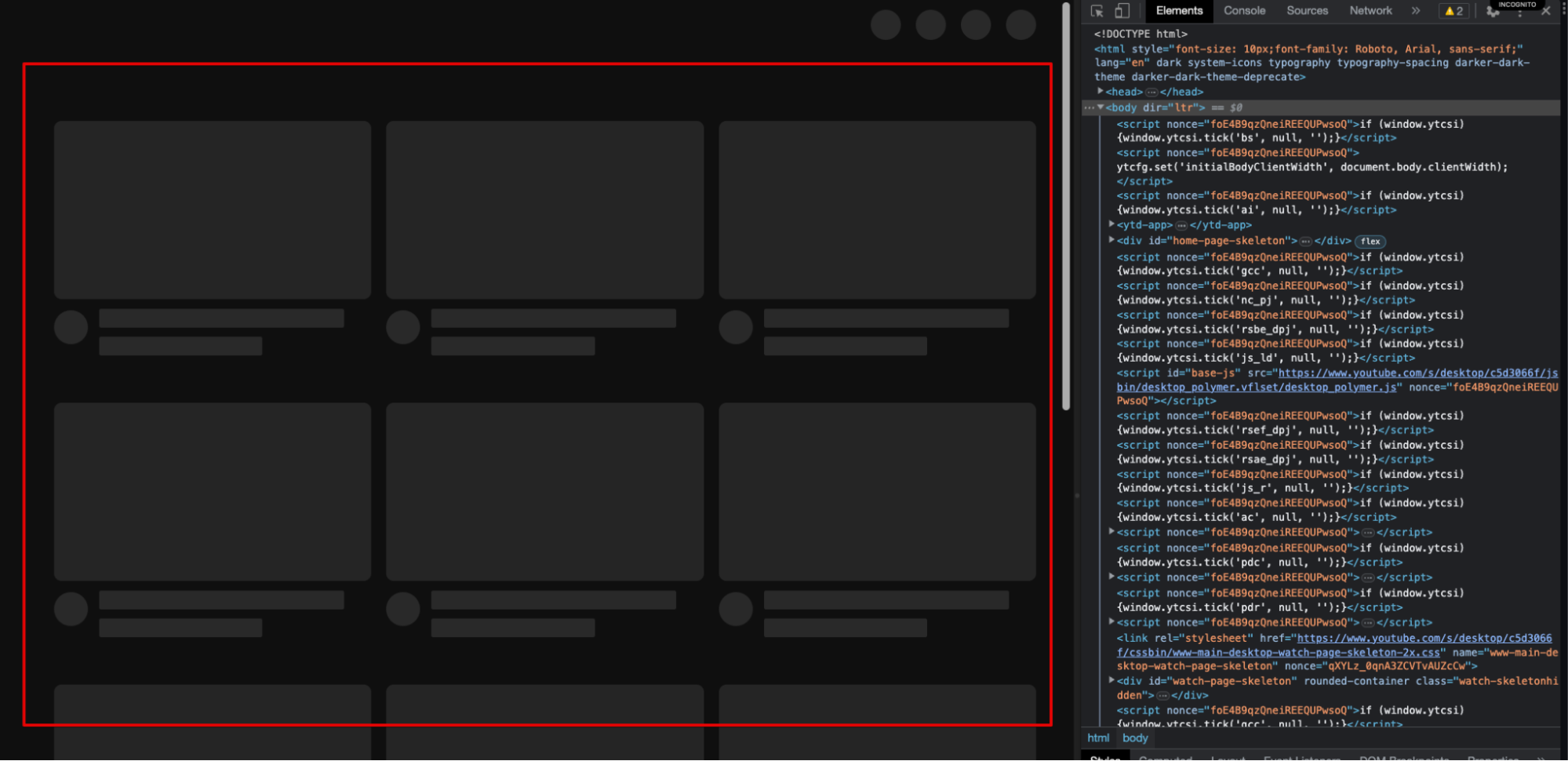
Now, all the dynamic content will disappear from the page while the static content remains.
Once you’ve identified whether the website you’re scraping is dynamic, you can move on to the next step: scraping it!
How to scrape a dynamic website?
The best method for scraping dynamic websites is by using headless browsers. They are normal browsers without a visible user interface.
Selenium is the most well-known example, and we’ll use it today! It executes JavaScript like a regular browser and allows you to extract data from it.
Consider this code here:
<html> <body> <div id="result"></div> <script> document.getElementById("result").innerHTML = ` <h1> Posts </h1> <h2> This is post #1 </h2> <p> lorem ipsum dolor sit amet 1 </p> <h2> This is post #2 </h2> <p> lorem ipsum dolor sit amet 2 </p> <h2> This is post #3 </h2> <p> lorem ipsum dolor sit amet 3 </p> `; </script> </body> </html>
Here, our regular web scraping with Beautiful Soup wouldn’t work as JavaScript renders the website code.
Here’s how you would use Selenium to scrape all the H2s from this webpage:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from dotenv import load_dotenv driver = webdriver.Chrome(service=Service( ChromeDriverManager().install())) website = "https://namancoderpro.github.io/dynamic-website/" driver.get(website) headings = driver.find_elements(By.XPATH, '//*[@id="result"]/h2') for heading in headings: print(heading.text) driver.close()
Here’s a breakdown of this code. First of all, we’re importing all the required modules from Selenium.
Then, we’re initiating our Chromedriver, so Selenium would automatically open Chrome and use it to scrape the website.
Next, we’ve entered the URL of our website. Selenium opens the website and finds all the H2 headings on the page using XPath.
We loop over the list of headings and print the text in each.
Simple, right?
And that’s how you can scrape dynamic websites! Now, you have a basic foundation you can use for more complex projects.
2. Captchas and anti-bot measures

We all hate captchas, don’t we? Well, so do our web scrapers!
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a verification system that separates humans from bots using character recognition, image recognition, audio tests, and more.
Why does this work? That’s because:
- Computers are bad at recognizing distorted letters and blur images.
- Computers move their cursor in a very predictable way and without delay – not like real humans. CAPTCHAs detect that and block you.
- They also check your cookies and history to check if you’re a human.
So, how do you bypass them?
GoLogin is an anonymous browser to help you scrape websites without getting detected or blocked. We’ll use its API to demonstrate how you can get past CAPTCHAs.
With GoLogin, you can create browser profiles with unique browser fingerprints to avoid CAPTCHAs. The website will think you’re a real human. Thus, you’ll be able to avoid CAPTCHAs. Also, they provide proxies that will further protect your data from tracking.
3. Rate limiting and IP blocking

As the name suggests, rate limiting limits the number of requests one specific IP can send to a website in a given timeframe. IPs are like identity cards on the internet.
It’s how websites identify who is using them.
If you send too many requests in a short timeframe, the app will stop entertaining any more of them for some time and say, “Back off, bud.”
Rate limiting is essential for preventing DDoS or brute-force attacks by bots, and they’re set in place to stop web scraping too. If there is repeated suspicious activity from your IP, websites can even ban it.
What’s the solution for this?
If you haven’t guessed, it’s rotating your IP address and using proxies. Proxies act as middlemen between you and the server, allowing you to mask your IP address to prevent blocking.
The best way is to buy many proxies from a provider and then rotate between them in your code at some interval.
In this tutorial, we’ll use ScraperAPI, which provides a free proxy for up to 5,000 requests per month. Their API automatically handles proxy rotating, captchas, and retries.
Step 1) Sign up for a free account at ScraperAPI.
Step 2) Write the following code:
import requests
proxies = {
'http': 'http://scraperapi.render=true:[email protected]:8001'
}
r = requests.get("http://httpbin.org/ip", proxies=proxies, verify=False)
print(r.text)
# Here’s the output of the above code (IP of the proxy)
# Output: {
# "origin": "104.164.122.88"
# }
Here’s what this code does:
- First, we import the requests module from Python
- Second, we declare our proxies like we usually would. You can copy this from the ScraperAPI dashboard.

- Third, we use the requests module to send a request to this page and pass in the required parameters.
- Fourth, we print out the text. Once needed, you can upgrade to their paid version.
Web Scraping Use Cases
Awesome! Now that you know how to overcome some common web scraping challenges, it’s time to see everyday use cases of web scraping.
Data Extraction for Market Research
Market research is necessary if your business is looking to extract insights from a market or launch a product in a new market.
It’ll give you a good idea of the current market dynamics, flaws with the competition, and customer problems.
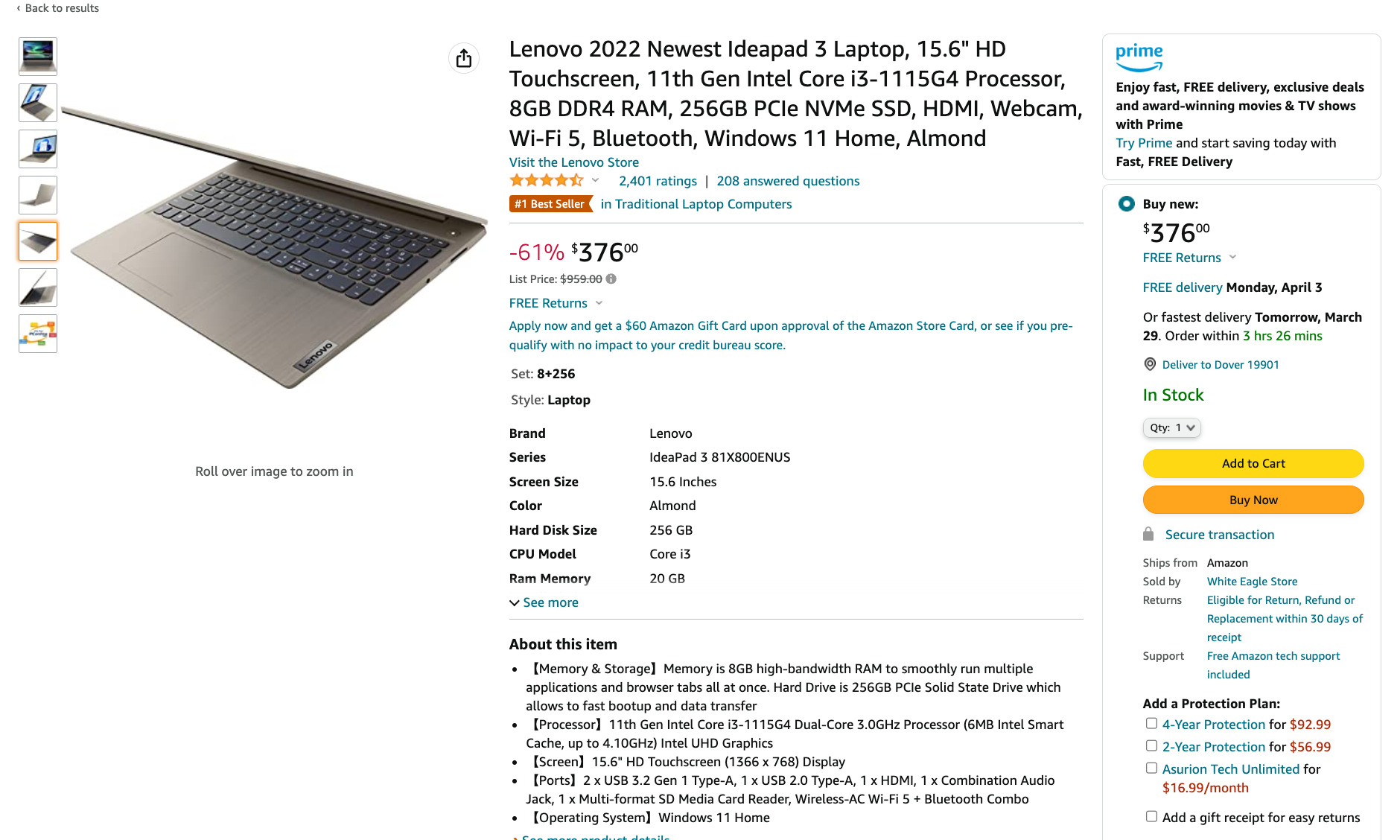
For example, if you’re launching a new laptop company, you might want to scrape existing laptops on Amazon and their customer reviews to learn what consumers want.
To demonstrate it, we’re going to scrape the title of this product from Amazon:
Here’s how you can implement this with Beautiful Soup:
import requests
from bs4 import BeautifulSoup
proxies = {
'http': 'http://scraperapi.render=true:[email protected]:8001'
}
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
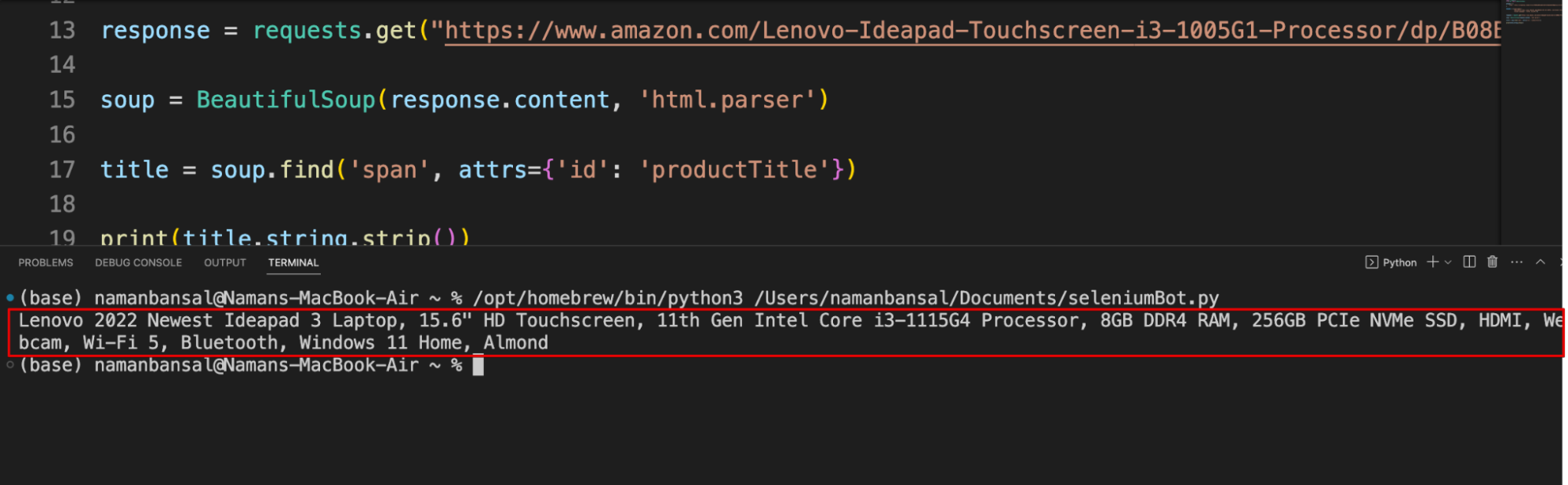
response = requests.get("https://www.amazon.com/Lenovo-Ideapad-Touchscreen-i3-1005G1-Processor/dp/B08B6F1NNR/ref=sr_1_3?crid=2KJYDQNW424SA&keywords=laptops&qid=1680007667&refresh=1&sprefix=lapt%2Caps%2C441&sr=8-3&th=1", proxies=proxies, headers=HEADERS)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find('span', attrs={'id': 'productTitle'})
print(title.string.strip())
And, here’s the output of this code:
Here’s what this code does:
- You import the requests and Beautiful Soup libraries.
- Then, use the proxies we had used previously in this tutorial for additional security.
- Add a user agent so Amazon doesn’t know we’re a bot.
- Fetch the product URL, and pass the proxies and headers.
- Parse the response using Beautiful Soup, find the product title from it, and print it.
Awesome job!
Social Media Sentiment Analysis
Social media sentiment analysis means listening to what consumers and brands think about your or somebody else’s brand. It’s quite popular, considering that 26% of companies hiring web scrapers use them to monitor consumer opinions.
It’s carried out by scraping many reviews about a particular product/brand/service from social media sites and then using NLP (natural language processing) to analyze them and the emotions behind them.
Keeping a good perception of your brand is especially important. It leads to more word-of-mouth marketing and referrals with a 16% higher value than a non-referred customer.
Here’s how you can perform sentiment analysis on Twitter tweets.
Here’s a code sample that does exactly that:
import re
import tweepy
from tweepy import OAuthHandler
from textblob import TextBlob
class TwitterClient(object):
'''
Generic Twitter Class for sentiment analysis.
'''
def __init__(self):
'''
Class constructor or initialization method.
'''
# keys and tokens from the Twitter Dev Console
consumer_key = 'XXXXXXXXXXXXXXXXXXXXXXXX'
consumer_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXX'
access_token = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXX'
access_token_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
# attempt authentication
try:
# create OAuthHandler object
self.auth = OAuthHandler(consumer_key, consumer_secret)
# set access token and secret
self.auth.set_access_token(access_token, access_token_secret)
# create tweepy API object to fetch tweets
self.api = tweepy.API(self.auth)
except:
print("Error: Authentication Failed")
def clean_tweet(self, tweet):
'''
Utility function to clean tweet text by removing links, special characters
using simple regex statements.
'''
return ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])
|(\w+:\/\/\S+)", " ", tweet).split())
def get_tweet_sentiment(self, tweet):
'''
Utility function to classify sentiment of passed tweet
using textblob's sentiment method
'''
# create TextBlob object of passed tweet text
analysis = TextBlob(self.clean_tweet(tweet))
# set sentiment
if analysis.sentiment.polarity > 0:
return 'positive'
elif analysis.sentiment.polarity == 0:
return 'neutral'
else:
return 'negative'
def get_tweets(self, query, count = 10):
'''
Main function to fetch tweets and parse them.
'''
# empty list to store parsed tweets
tweets = []
try:
# call twitter api to fetch tweets
fetched_tweets = self.api.search(q = query, count = count)
# parsing tweets one by one
for tweet in fetched_tweets:
# empty dictionary to store required params of a tweet
parsed_tweet = {}
# saving text of tweet
parsed_tweet['text'] = tweet.text
# saving sentiment of tweet
parsed_tweet['sentiment'] = self.get_tweet_sentiment(tweet.text)
# appending parsed tweet to tweets list
if tweet.retweet_count > 0:
# if tweet has retweets, ensure that it is appended only once
if parsed_tweet not in tweets:
tweets.append(parsed_tweet)
else:
tweets.append(parsed_tweet)
# return parsed tweets
return tweets
except tweepy.TweepError as e:
# print error (if any)
print("Error : " + str(e))
def main():
# creating object of TwitterClient Class
api = TwitterClient()
# calling function to get tweets
tweets = api.get_tweets(query = 'Donald Trump', count = 200)
# picking positive tweets from tweets
ptweets = [tweet for tweet in tweets if tweet['sentiment'] == 'positive']
# percentage of positive tweets
print("Positive tweets percentage: {} %".format(100*len(ptweets)/len(tweets)))
# picking negative tweets from tweets
ntweets = [tweet for tweet in tweets if tweet['sentiment'] == 'negative']
# percentage of negative tweets
print("Negative tweets percentage: {} %".format(100*len(ntweets)/len(tweets)))
# percentage of neutral tweets
print("Neutral tweets percentage: {} % \
".format(100*(len(tweets) -(len( ntweets )+len( ptweets)))/len(tweets)))
# printing first 5 positive tweets
print("\n\nPositive tweets:")
for tweet in ptweets[:10]:
print(tweet['text'])
# printing first 5 negative tweets
print("\n\nNegative tweets:")
for tweet in ntweets[:10]:
print(tweet['text'])
if __name__ == "__main__":
# calling main function
main()
Source: https://www.geeksforgeeks.org/twitter-sentiment-analysis-using-python/
Here’s what this code does:
- First, it authorizes the Twitter API client.
- Second, gets the entered number of tweets for a certain topic using the ‘get_tweets()’ function.
- Then, it analyzes the sentiment of the tweets with the ‘get_tweet_sentiment’ function using the TextBlob library. In the process, it also cleans the tweets by removing special characters or links using RegEx.
- Lastly, it gives us the % of positive, negative, and neutral tweets.
Very cool!
Web monitoring and change detection
We’re sure you’ve heard of all the price monitoring tools that allow you to buy a product at its lowest price. Those tools use web scraping to show you the data and are a prime example of web monitoring and change detection in action.
If you prefer a more formal change, it’s monitoring changes to a webpage and notifying people about it.
It’s fantastic to snag those cheap flight tickets and hotel reservations! Here’s how you can build one yourself:
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException, NoSuchElementException
from twilio.rest import Client
from apscheduler.schedulers.background import BackgroundScheduler
import time
def tracker():
# Product URL that we want to track along with desired price to buy it
wishlist = {
"https://www.amazon.in/HP-Laptop-Graphics-Anti-Glare-Warranty/dp/B0BVQJ5R2H/ref=sr_1_3?keywords=laptop&qid=1680097303&sr=8-3": 24999,
"https://www.amazon.in/Dell-Vostro-3510-39-62Cms-ICC-D585046WIN8/dp/B0BQJ8QZ9D/ref=sr_1_5?crid=2RF9JLLZYY2ZN&keywords=laptop&qid=1680103521&sprefix=lapto,aps,233&sr=8-5": 31900
}
# Twilio authentication to send SMS when product price is lower than desired price
account_sid = os.environ['TWILIO_SID']
auth_token = os.environ['AUTH_TOKEN']
client = Client(account_sid, auth_token)
# for loop to go over each product
for product in wishlist:
# Opening browser window with selenium
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
# Getting Amazon URL
driver.get(product)
# Finding price using XPath
price = driver.find_element(
By.XPATH, '/html/body/div[2]/div[2]/div[5]/div[4]/div[4]/div[10]/div[3]/div[1]/span[2]/span[2]/span[2]')
# Checking if price is less than desired price
if int(price.text.replace(',', '')) <= wishlist[product]:
print(int(price.text.replace(',', '')))
print("Product available at desired price")
# Sending an SMS
message = client.messages.create(
body=f'The product {product} is available at your desired priced. Buy it now!',
from_='YOUR_TWILIO_PHONE_NUMBER',
to='YOUR_REAL_PHONE_NUMBER'
)
driver.close()
else:
print(int(price.text.replace(',', '')))
print("Product unavailable at desired price")
driver.close()
# Scheduler to make it run every hour automatically
if __name__ == '__main__':
scheduler = BackgroundScheduler()
scheduler.add_job(tracker, 'interval', hours=1)
scheduler.start()
while True:
time.sleep(0.001)
Here’s a quick explanation of what this code does:
- We’ve made a dictionary with our product URL and our desired price to buy it.
- Authenticate Twilio SMS using SID and auth token to send SMS messages: sign up here.
- Loop over each product in our wishlist with a for loop.
- Open a Selenium window for it, fetch the product URL, and then use XPath to find the price.
- Convert the price into an integer and compare it with the price in our wishlist.
- If it’s lower than that, we send an SMS
- If it’s higher, we just print it to the console
In the end, it is our scheduler’s job to make this script run automatically every hour.
Cool, right?
Conclusion
Let’s recap what we’ve covered. Now, you know about overcoming common web scraping challenges like dynamic content, captchas, and IP blocking, along with code examples.
You also know how to use web scraping in the real world for market research, social media sentiment analysis, web monitoring, and change detection. Amazing!
GoLogin is a valuable web scraping tool that you can use to bypass captchas, prevent detection, manage multiple browser profiles, and surf anonymously.
Next up in this series are more advanced web scraping tips and techniques to help you become an expert! Stay tuned for more and download GoLogin to scrape even the most advanced web pages without being noticed!


