In today’s competitive real estate market, Zillow web scraping is an absolute must-have tool. Agencies must leverage it to stay ahead of the curve. You simply can’t imagine today’s fast-paced online market without it anymore.
By extracting valuable data from Zillow, agencies gain crucial insights into market trends, property listings, and consumer behavior. We have prepared a guide with code, so you can perform Zillow web scraping with Python yourself.
What Is Web Scraping?
Using automated software applications – web scraping – is the process of gathering and extracting big data from websites. Sometimes it’s referred to as web data extraction.
The program, commonly referred to as a web scraper or spider, is used to browse web pages, collect and send data into a structured format that may be further analyzed.
Web scraping is important for several reasons:
Businesses and organizations can use it to obtain useful data on their rivals, the market, client behavior, and more. Companies can learn more about what their customers want and how to improve their goods, services and APIs.
Research purposes, such as in academic or scientific studies, are also served by web scraping. Web scraping allows to swiftly and effectively gather enormous amounts of data. It enables them to find patterns, trends, and insights that would be hard to find any other way.
Certain chores, including keeping track of prices or product availability online, can be automated via web scraping. Companies can automate their data collecting procedures by scraping data from multiple websites. This saves a lot of time and resources that are better used for other tasks.
What Is GoLogin?
GoLogin is a privacy browser for managing several online identities. It offers users a private and secure environment for web browsing. Thanks to its top notch browser fingerprinting engine, it’s able to protect web scrapers on a professional level. This includes spiders used for Zillow web scraping.
Users can establish and maintain several profiles with GoLogin that each have their own set of browser parameters. This feature enables users to sign in to multiple zillow agent login on the same website at once completely anonymous. This might be helpful for companies and SMMs who maintain many social media or e-commerce accounts.
How GoLogin Helps Developers?
GoLogin can help developers scrape websites more efficiently and securely in several ways:
Secure browsing environment
GoLogin provides a secure and private browsing environment for web scraping. It protects user data and prevents detection by websites that may attempt to block scraping activities.
Multiple browser profiles
GoLogin allows developers to create and manage multiple browser profiles. Each profile comes with its own set of cookies, browser settings and user agent. This allows developers to log in to multiple accounts on the same website simultaneously and stay completely anonymous. To keep it shorter – it’s a great protection level for a Zillow data scraper.
Protection for web scrapers
GoLogin offers top-tier protection web scrapers, allowing developers to use unique user agents. This makes scrapers look like normal users, allowing to extract data from Zillow and other websites more efficiently.
Proxy server integration
GoLogin supports integration with proxy servers, allowing developers to scrape websites from different IP addresses and locations. This helps avoid detection and prevent websites from blocking scraping activities.
Overall, GoLogin can help developers scrape websites more efficiently and securely by providing a secure and private browsing environment. It allows for multiple browser profiles and automation of web scraping tasks. GoLogin also allows for comfortable and fast work with proxy servers.
Using Selenium for Web Scraping
There are many technologies that may be used to perform web scraping, which is a potent method for gathering data from websites. You can do web scraping using Selenium, a well-liked automation tool.
The capability to interact with web pages, model user behaviour, and automate operations are just a few of the characteristics that make it an effective web scraping tool.
Set Up Selenium On Your Computer
To use Selenium with Python , you’ll need to have Python installed on your computer. Then you’ll need to install the Selenium package by running the command pip install selenium in a command prompt or terminal window.
Importing Driver
Selenium requires a web driver to interact with web pages. You can download the web driver for your preferred web browser from the official Selenium website. Once you’ve downloaded the web driver, you’ll need to specify its location in your code by adding a few lines of code at the beginning of your script.
Making an account on GoLogin’s website is the initial step in using the service. You can accomplish this by going to the GoLogin website and creating an account using your email address. You can log in to the platform and begin configuring your browser profiles after creating an account.
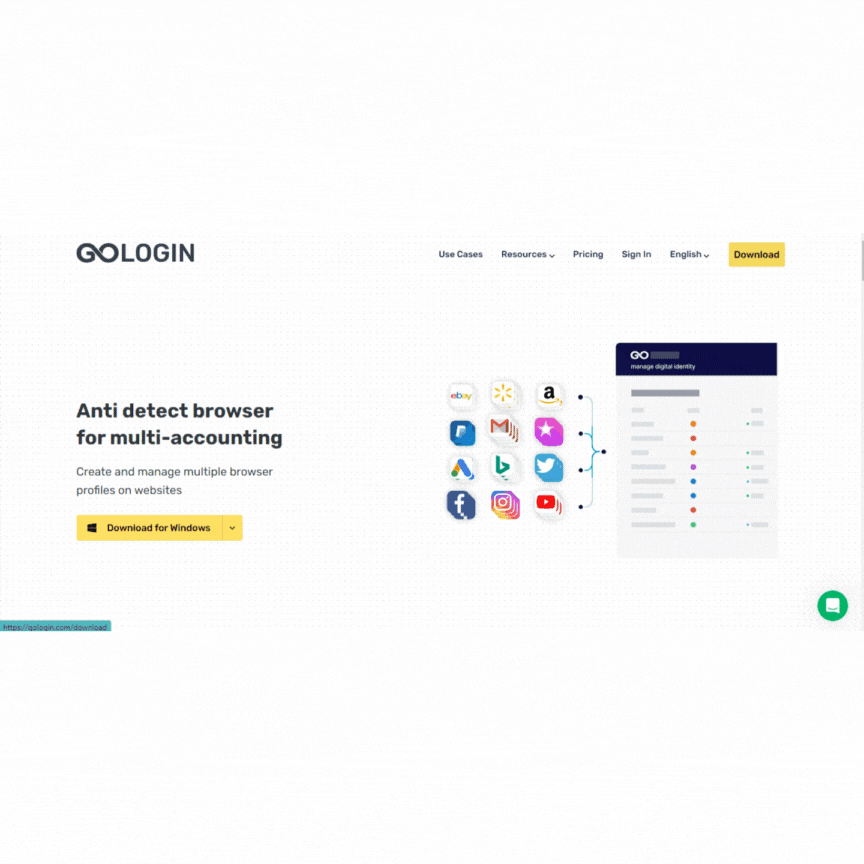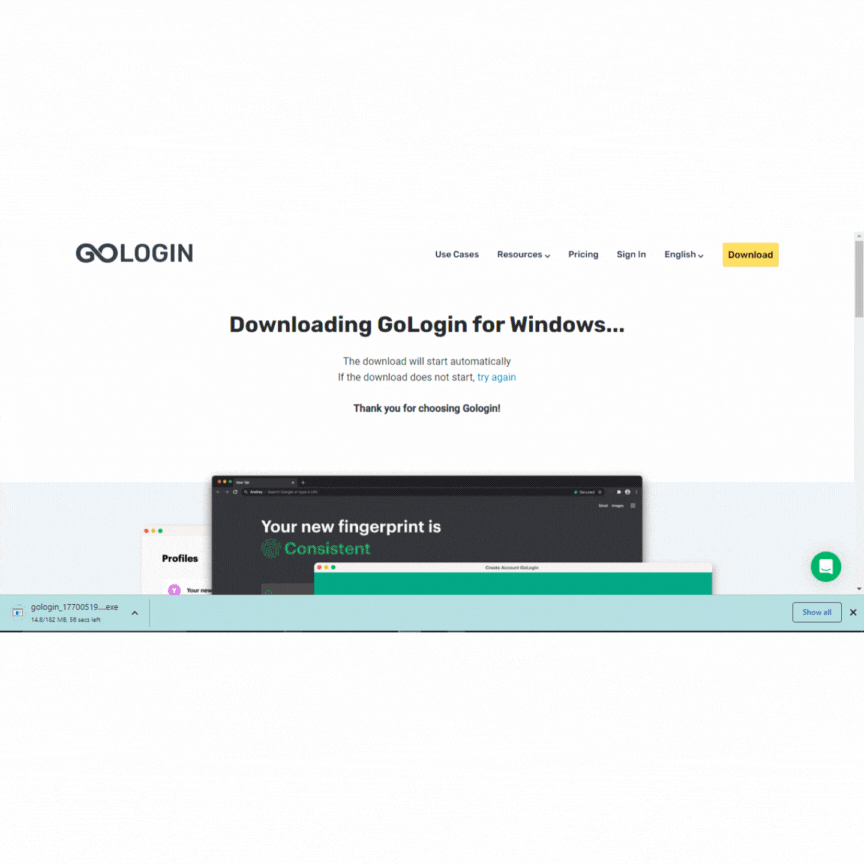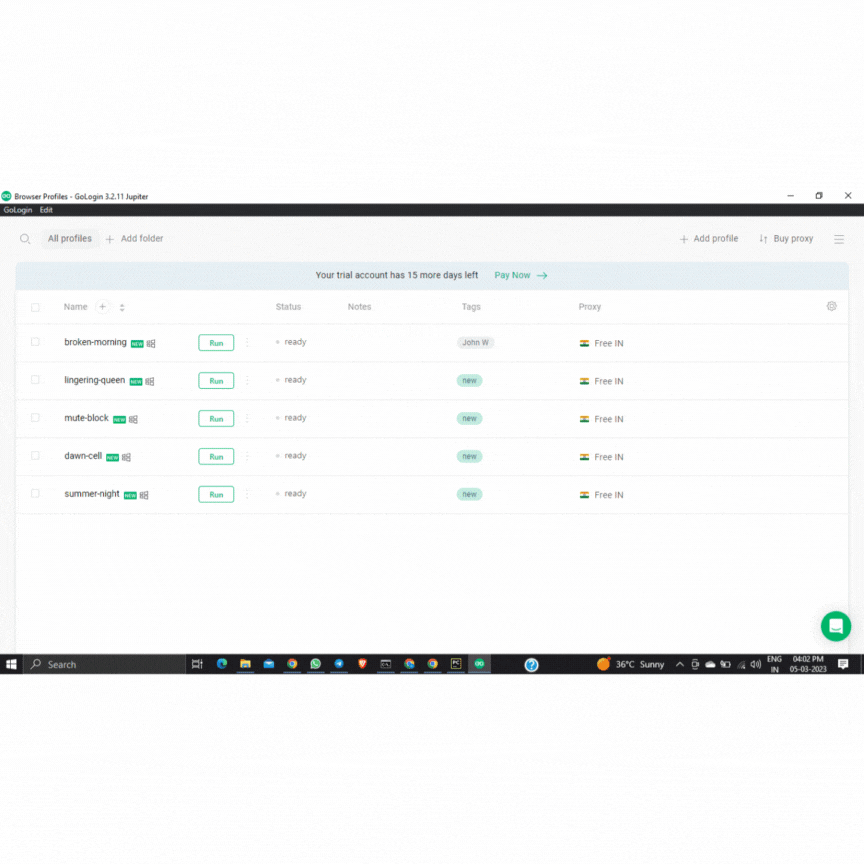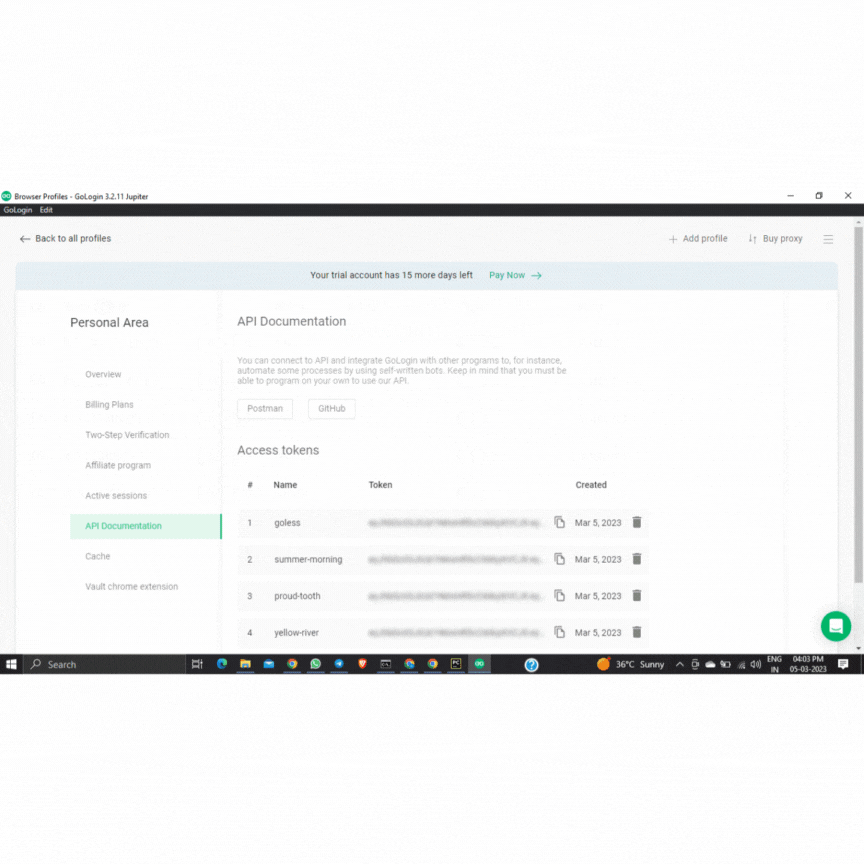
Step 2: Set up a browser profile
GoLogin employs a browser profile as a distinct identity to simulate actual user behavior. Just create a new profile with the “+” icon on the top left of the Profiles table. You can then alter the profile in the Quick settings tab.
These features will assist in making the profile appear more authentic. Your chance of getting blocked while web scraping Zillow gets significantly lower.
Step 3: Configure the proxy settings
You can modify the proxy settings for your browser profile to further lower the chance of detection. By doing this, you can give every website you visit a distinct IP address. This makes it more challenging for them to monitor your online behavior.
Step 4: Start web scraping
You can begin web scraping after setting up your proxy settings and browser profile. You need to do this by writing a web scraping script in a computer language like Python. The script should access the website and extract the necessary data via GoLogin browser profile.
Zillow Web Scraping with Python
Importing Libraries
The pandas library is used to operate and analyze data. Requests is used for making HTTP requests to retrieve data from API (Application Programming Interface) or a website. The json library is used for working with JSON data.
Time is used for pausing the script for a specified amount of time. The io library is used for working with file-like objects, and plotly.express is used for data visualization.
import pandas as pd
import requests
import json
import time
import io
import plotly.express as px
The script is required to retrieve data from an API or web service, store extracted data in a pandas dataframe, and visualize it using plotly.express.
Retrieving Information
This code is used to get the ZPID of a property listed on Zillow page, given its address price details. This ZPID can be used to retrieve additional information about the property, such as its estimated value and sales history.
def get_zpid(street=None, city=None, state=None, zip_code=None, full_address=None):
# get search query string
if full_address == None:
try:
query = '{0}, {1}, {2} {3} zillow home details'.format(street, city, state, str(zip_code))
except:
return 'Please enter a query string or address details'
else:
query = full_address + ' zillow home details'
# get google search results
search_results = search(query, tld='com', lang='en', num=3, start=0, stop=1, pause=0)
search_results_list = [u for u in search_results]
url = search_results_list[0] # extract first returned result
# return zpid
try:
return [x for x in url.split('/') if 'zpid' in x][0].split('_')[0]
except:
return None
The function attempts to extract the ZPID from the selected URL by splitting the URL string based on the ‘/’ character and selecting the first substring that contains the string ‘zpid’.
The code then further splits the selected substring based on the ‘_’ character and returns the first element, which should be the ZPID. If this process fails for any reason, such as the selected URL not containing a valid ZPID, the function returns `None`.
Accessing Zillow API
We define a function called get_property_detail that retrieves property details using an API provided by RapidAPI. It takes two parameters: rapid_api_key and zpid.
The function sets the endpoint URL and querystring, and makes a GET request with the provided API key and querystring. The function returns the response from the API, which should contain the requested property details.
def get_property_detail(rapid_api_key, zpid):
# get property details from API
url = "https://zillow-com1.p.rapidapi.com/property"
querystring = {"zpid":zpid} # zpid
headers = {
"X-RapidAPI-Host": "zillow-com1.p.rapidapi.com",
"X-RapidAPI-Key": rapid_api_key # your key here
}
# request data
return requests.request("GET", url, headers=headers, params=querystring)
If API Key is stored in a file:
# read in api key file
df_api_keys = pd.read_csv(file_dir + 'api_keys.csv')
# get keys
rapid_api_key = df_api_keys.loc[df_api_keys['API'] =='rapid']['KEY'].iloc[0] # replace this
Extracting Property Details Given A Unique ZPID
Setting Property Address and Creating a Search Query for Zillow Home Details
# property address
property_address = "11622 Pure Pebble Dr, RIVERVIEW, FL 33569" # https://www.zillow.com/homedetails/11622-Pure-Pebble-Dr-Riverview-FL-33569/66718658_zpid/
# search query
query = property_address + ' zillow home details'
print('Search this phrase in Google Search:', query)
Retrieving Zillow Property ID (ZPID) from the First Google Search Result
# google search results
search_results = search(query, tld='com', lang='en', num=3, start=0, stop=3, pause=0)
search_results_list = [u for u in search_results] # get all results
# get the first search result
url = search_results_list[0] # extract first returned result
# extract the zpid
zpid = [x for x in url.split('/') if 'zpid' in x][0].split('_')[0]
print('Zpid of the property is:', zpid )
Requesting and Validating the Response from Zillow API for Property Details
# get property details from API
url = "https://zillow-com1.p.rapidapi.com/property"
querystring = {"zpid":zpid} # zpid
headers = {
"X-RapidAPI-Host": "zillow-com1.p.rapidapi.com",
"X-RapidAPI-Key": rapid_api_key # your key here
}
# request data
response = requests.request("GET", url, headers=headers, params=querystring)
# show success
response.status_code # 200 is success!
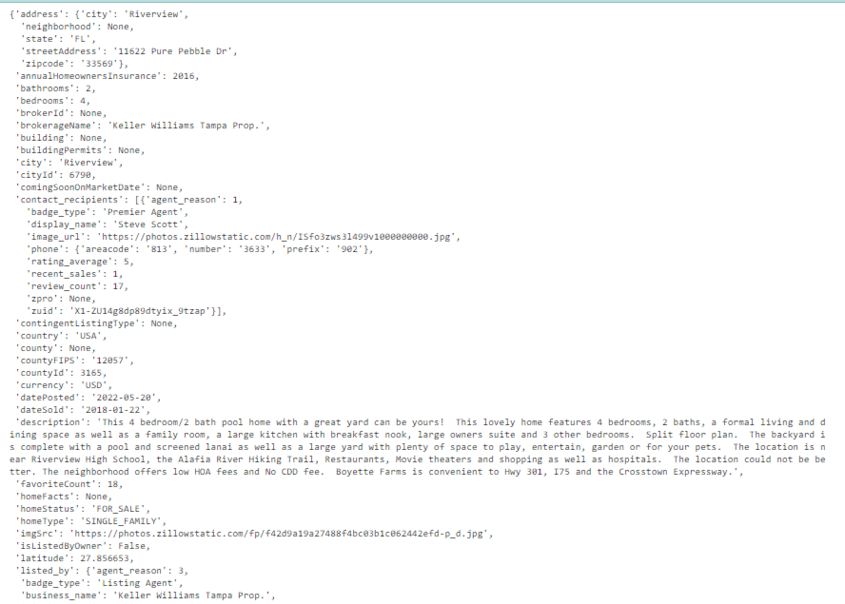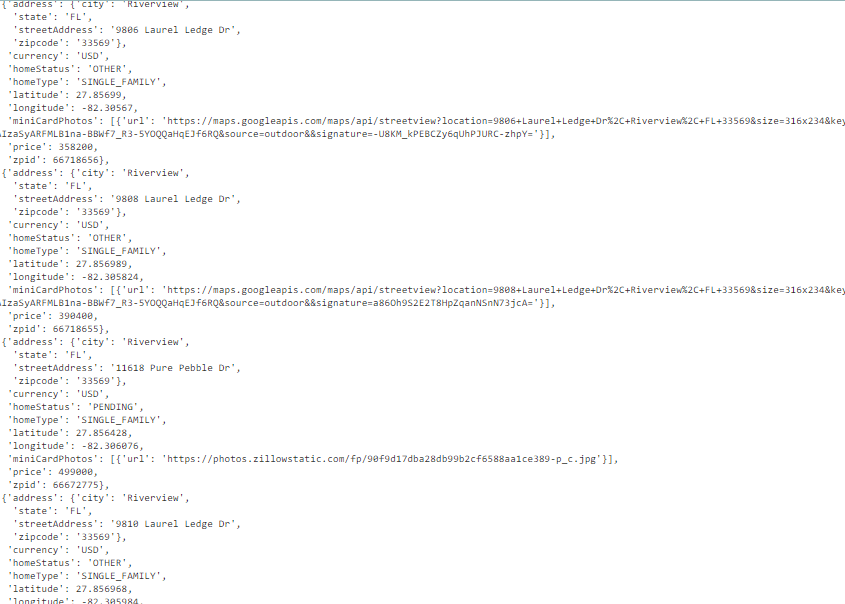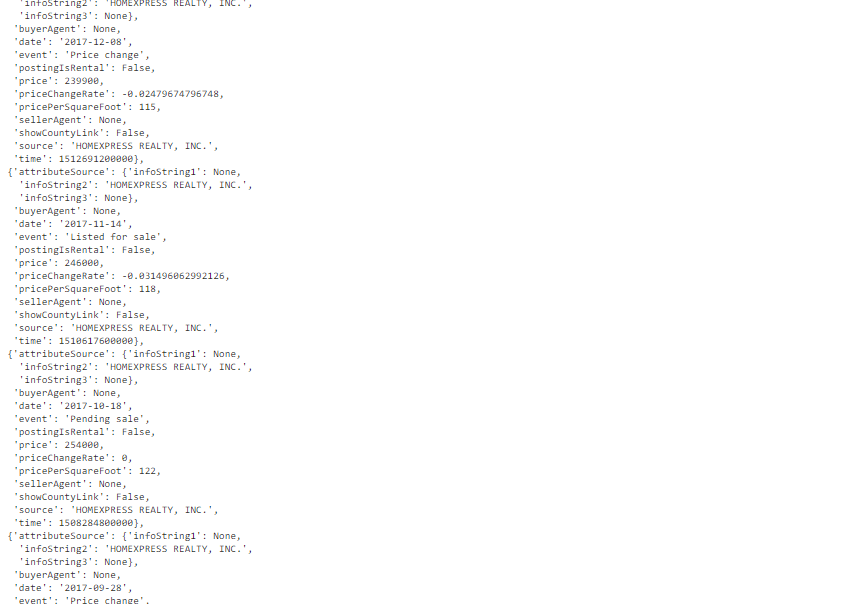
Printing The Response
response.json()
Output
Using Gologin
What’s the main benefit of using GoLogin in the above code? It allows the code to automate web scraping tasks while avoiding the risk of IP bans and CAPTCHA challenges.
GoLogin provides users with a secure and private browsing experience by allowing them to use multiple and rotating proxies, unique user agents and browser fingerprints. This helps to reduce the chances of being detected as a bot by the website and getting blocked.
GoLogin’s top-tier fingerprinting techniques help reduce the chances of being detected as a bot. It improves the effectiveness of the web scraping process and saves resources and time.
from gologin import GoLoginAuth
import requests
# configure GoLogin settings
api_key = "your_api_key"
gl_auth = GoLoginAuth(api_key)
# set the URL and headers of the API endpoint
url = "https://example.com/api/endpoint"
headers = {"Authorization": "Bearer YOUR_ACCESS_TOKEN"}
# make the API request using the authenticated session
session = requests.Session()
session.auth = gl_auth
response = session.get(url, headers=headers)
# check the response status code
if response.status_code == 200:
print("API request successful!")
else:
print(f"API request failed with status code {response.status_code}")
We first create an instance of the GoLoginAuth class by passing our GoLogin API key as an argument. Then, we set the URL and headers of the API endpoint we want to authenticate. We create a new requests.Session object and set the auth attribute to our gl_auth object, which will use our GoLogin credentials to authenticate the session.
Finally, we make the API request using the session object and check the response status code to see if the request was successful.
Before scraping any website, it is important to read and understand the website’s terms of service. Some websites explicitly prohibit web scraping or data extraction, and violating these terms can lead to legal issues.
Use an API if available
Some websites provide APIs that allow developers to access their data in a structured format. If an API is available, it is usually the preferred method for data extraction as it is more efficient and less likely to cause issues with the website.
Limit requests and use delay
Sending too many requests to a website can cause it to slow down or even crash. To avoid this, it is important to limit the number of requests made and to use a delay between requests to avoid overloading the server.
Use user-agents and proxies
Websites can detect when automated bots are accessing their pages, which can lead to being blocked or banned. To avoid this, it is important to use a user-agent that mimics a real browser and to use proxies to mask the IP address.
Handle errors and exceptions.
When scraping data from websites, errors and exceptions are bound to occur. It is important to handle these errors gracefully by logging them and retrying the request if necessary.
Respect copyright laws
When scraping data from websites, it is important to respect copyright laws by not using copyrighted material without permission and by giving credit where credit is due.
Don’t scrape sensitive data
It is important to avoid scraping sensitive data such as personal information, financial data, or confidential information. Doing so can lead to legal issues and ethical concerns.
Monitor website changes
Websites can change their structure or content, which can cause issues with a web scraper. It is important to monitor website changes and update the scraper accordingly to ensure it continues to function correctly.
Conclusion
As the real estate landscape continues to evolve, embracing web scraping and other data-driven approaches will be crucial for agencies to maintain a competitive edge and thrive in this dynamic industry. It is still relatively simple to extract and analyze data from websites like Zillow thanks to Python tools.
In this article, we’ve explored how to set up GoLogin and Python for Zillow web scraping. Additionally, we have offered ethical principles and best practises for web scraping, such as how to manage mistakes and exceptions, how to handle website blocks, and how to scrape data from Zillow while upholding moral and legal standards.
Download GoLoginand enjoy safe web scraping Facebook with our free plan!
FAQ
Does Zillow allow web scraping?
Technically, yes. It may be against their terms and conditions – as a private company, Zillow is free to forbid data extraction. However, extracting data that’s public domain is not prohibited by US and international laws. At GoLogin, we recommend to always keep to local laws and never go for data that’s not open access.
How do I use a web scraper on Zillow?
Using a web scraper on Zillow, or any website that prohibits scraping, would be a violation of their terms of service. Instead consider using their official API – if available. If the API is not available, you can apply standard open-source tools like BeautifulSoup, Pandas, requests and others. Be sure to register for GoLogin’s trial or free plan to get safe user agents for your scrapers – you may get blocked otherwise.
How do I scrape a website on Zillow using Python?
It’s possible for any Python enthusiast. Use free programming environments (Beautiful Soup and Python programming language), register for GoLogin’s trial or free plan to get safe user agents for your scrapers, and consult the scraping community for more advice.
Can you download Zillow data into Excel?
Sure! Excel export is available in most open source scraping tools. For example, you can export Pandas DataFrame to an Excel file using command to_excel. This command also works for BeautifulSoup4 and other environments with minor code alterings.
Source references:
Berry N. Modern Web Scraping and Data Analysis Tools to Discover Historic Real Estate Development Opportunities : dis. – Massachusetts Institute of Technology, 2022.
Holt J. R., Borsuk M. E. Using Zillow data to value green space amenities at the neighborhood scale //Urban Forestry & Urban Greening. – 2020. – Т. 56. – С. 126794.
Zhao B. Web scraping //Encyclopedia of big data. – 2017. – Т. 1.
Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
Diouf R. et al. Web scraping: state-of-the-art and areas of application //2019 IEEE International Conference on Big Data (Big Data). – IEEE, 2019. – С. 6040-6042.
An Innovative Option to Bet More With Multiple Bet365 Login
Scaling wins on bet365 can be quite limited with account restrictions. Read on to find about new safe methods of multiple bet365 login!
Top 6+1 Web Browsers for PC
In this article, we are going to quickly dissect the main advantages of the most renowned web browsers for PC, what they are not really good at, and explain our pick.
How And Where To Buy LinkedIn Accounts? New 2024 Guide
Looking to boost your LinkedIn presence? You might be wondering about how to buy LinkedIn accounts – here’s a complete guide for 2024!
We’d love to hear questions, comments and suggestions from you. Contact us [email protected] or leave a comment above.
Are you just starting out with GoLogin? Forget about account suspension or termination. Choose any web platform and manage multiple accounts easily. Click here to start using all GoLogin features