Advanced web scraping techniques and tools are crucial for gathering and analyzing large data. If you’re new to our Web Scraping series, let’s quickly recap.
In the previous articles, we discussed:
- The fundamental tools, techniques, and best practices for web scraping
- Introduction to Python as a powerful language for web scraping
- How to overcome common challenges while web scraping
This article will explore advanced web scraping methods and tips for success.
You’ll learn how to handle complex web pages, work with APIs, and more. Buckle up and prepare to take your web scraping skills to the next level!

Advanced Web Scraping Techniques
Let’s have a look at some methods of web data extraction from complex websites with security measures:
XPath Expressions
XPath is a query language used to navigate and select elements within an XML or HTML document. It allows for the precise selection of specific elements within a web page.
One of the main advantages of using XPath is its flexibility. It can select elements based on their attributes, text content, and tags within the HTML hierarchy.
Here is an example of using XPath with Scrapy in Python. This code helps extract the titles and links of the top articles from any webpage.
import scrapy
import requests
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['https://www.example.com']
def parse(self, response):
title = response.xpath('//title/text()').get()
links = response.xpath('//a/@href').getall()
for i in range(len(title)):
print(f'{i+1}. {title[i]} - {links[i]}')
In this example, we define a Scrapy spider named “MySpider” that starts by requesting the URL ‘https://www.example.com.’ Note that you can use the URL of any website to extract data.
We call the “parse” method on downloading a page, which uses XPath expressions to extract data from the HTML response.
Specifically, we use the XPath expression “//title/text()” to extract the text content of the title tag and the expression “//a/@href” to extract the href attribute of all a tags on the page.
Finally, we print the results using a for loop.
Scraping JavaScript – Complex Websites
Another challenge is scraping JavaScript at heavy websites.
JavaScript is a scripting language that runs client side scripts of web applications. You can use it for creating dynamic and interactive web pages.
However, it can also make web scraping difficult. Many websites use JavaScript document object model to render content dynamically, which means you cannot extract data using traditional scraping techniques. We must use advanced web scraping tools like Scrapy-Splash and Selenium to scrape data from websites like these.
 Scrapy-Splash is an open-source Python library that enables web scraping with Scrapy while supporting JavaScript rendering.
Scrapy-Splash is an open-source Python library that enables web scraping with Scrapy while supporting JavaScript rendering.
Scrapy is a web scraping framework. Splash is a lightweight browser that can render JS, CSS, and HTML and can be controlled through an HTTP API.
Using Scrapy and Splash together allows Scrapy to send a request to Splash. It renders the web page and returns the rendered HTML to your Scrapy web scraping project.
You can install it using the following command on your terminal:
pip install scrapy-splash
Moreover, you need to install the Splash server by running the following command on your terminal:
docker run -p 8050:8050 scrapinghub/splash
This command will download the Splash image and start the Splash server on your local machine.
Now you can define a spider, “MySpider,” that uses Scrapy-Splash to scrape data from a website.
For example, the following web scraping script requests a URL using the SplashRequest object. The “parse” method processes the response for extracting data.
import scrapy from scrapy_splash import SplashRequest class MySpider(scrapy.Spider): name = 'my_spider' def start_requests(self): yield SplashRequest( url='http://example.com', callback=self.parse, ) def parse(self, response): #Extract required data from the website
Selenium is more of a general-purpose web testing framework that is widely used for web scraping.
Scraping Websites With Infinite Scrolling
Infinite scrolling is a design feature that loads new content automatically as the user scrolls down the page, creating an endless stream of content.

Infinite scrolling can present a challenge. The browser renders only some content at first and the rest later. It means that traditional web scraping tools may be unable to capture all the data on the page. Still, we can use advanced techniques to overcome this challenge.
One approach to scraping websites with infinite scrolling is to use a tool like Selenium. It allows for the automation of web browsers: it’s necessary for work as manual web scraping is impossible and ineffective in most cases. Selenium can simulate user behavior by scrolling down a page and capturing the loaded content.
Here is an example of how to use Selenium to navigate and extract data from infinite-scrolling websites:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("https://www.example.com/")
while True:
driver.find_element_by_tag_name('body').send_keys(Keys.END)
time.sleep(2)
if driver.execute_script("return window.scrollY + window.innerHeight") == driver.execute_script("return document.body.scrollHeight"):
break
#extract the required data from the page
elements = driver.find_elements_by_xpath("//div[@class='my-class']")
for element in elements:
data = element.text
print(data)
driver.quit()
Here’s what this code does:
- The web driver module from Selenium launched the Chrome browser and navigated to the website.
- The “while” loop scrolled down and waited for new content. It checked if it had reached the end of the page.
- Once we reached the page end, XPath scraped data from the relevant elements and printed it to the console.
Tips for Successful Web Scraping techniques
Web scraping can be a powerful tool for extracting data from the internet. Still, it can also be challenging and sometimes even illegal – if done wrong.
We have discussed all the tips and tricks to ensure successful and efficient web scraping. In this section, we will discuss the technical part of how to scrape data like a pro.
Ethical Web Scraping Practices
Ethical web scraping practices are critical for maintaining a good relationship with webmasters and users. Not to mention that it’ll avoid legal issues.
Before scraping any website, reading and understanding its Terms of Service is essential. The ToS will outline any restrictions on web scraping, like the frequency and number of requests. They may also provide guidelines for using the data.
Moreover, making requests at reasonable intervals is essential. Don’t launch a DDoS attack, please!
Throttling the requests also does not affect the website’s performance.
The robots.txt is a standard file websites use to communicate with your web scraper. It tells search engines and other automated tools which pages on the site it can access and which it cannot. Respect the rules outlined in the file and avoid scraping disallowed pages.
Data Storage and Management
Data storage and management are critical components of web scraping, critical for large-scale operations. Scraped data can accumulate quickly and become challenging to analyze without proper management.
One way to manage scraped data is to use a database management system (DBMS) such as SQLite, PostgreSQL, or MongoDB. These systems offer a structured and scalable way to store and manage large amounts of data. A DBMS can organize scraped data into tables, each representing a different data type.
Let’s say you are scraping data from many e-commerce websites. You want to store product information, prices, and customer reviews. You could create a table for each data type, with columns for the specific attributes. As you scrape data, you can insert it into the appropriate table. This would organize it and make it retrievable.
Install the DBMS on your PC. You can install them from their respective official websites. Here is an example code snippet using Python and SQLite to store scraped data for the above scenario:
import sqlite3
conn = sqlite3.connect('mydatabase.db')
conn.execute('''CREATE TABLE products
(id INTEGER PRIMARY KEY,
name TEXT,
price REAL)''')
product_data = [('Product 1', 10.99),
('Product 2', 19.99),
('Product 3', 7.99)]
for product in product_data:
conn.execute('INSERT INTO products (name, price) VALUES (?, ?)', product)
# Retrieve product data from the database
cursor = conn.execute('SELECT * FROM products')
for row in cursor:
print(row)
conn.close()
In this example, we create a ” products ” table with columns for the product ID, name, and price. We then scrape product data, insert it into the database using a loop, and finally retrieve it using a SELECT statement.
Once the database has the data, we can query and analyze it using SQL.
Error Handling and Logging
Error handling consists of identifying and handling errors that may occur during the scraping process, while logging involves recording information about the scraping process for future reference.
Error handling is essential to ensure your program’s safety and reliability. For example, a website may have missing or incomplete data. Or, it may be in a different format than expected. Error handling can help to identify and handle these issues appropriately.
Additionally, some websites may have security measures that can cause errors when scraping. Using proper error-handling techniques, you can prevent these errors from disrupting the scraping process.
Logging is also crucial in web scraping because it allows you to track the scraping process and identify any issues that may arise. You can identify patterns and trends that can help you optimize your scraping process by logging information such as:
- The URLs scraped
- The number of requests made
- Errors encountered
Here’s an example of how to implement error handling and logging in web scraping using Scrapy:
import scrapy
from scrapy.spidermiddlewares.httperror import HttpError
from scrapy.utils.log import configure_logging
from scrapy.utils.project import get_project_settings
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, callback=self.parse, errback=self.error_handler)
def parse(self, response):
# Parse the response here
pass
def error_handler(self, failure):
# Handle any errors here
pass
if __name__ == '__main__':
configure_logging(install_root_handler=False)
settings = get_project_settings()
settings.setdict({
'LOG_ENABLED': True,
'LOG_FILE': 'log.txt',
'LOG_LEVEL': 'INFO'
})
process = scrapy.crawler.CrawlerProcess(settings)
process.crawl(MySpider)
process.start()
In this example, the “MySpider” class extends the “scrapy.Spider” class and defines the “start_requests”, “parse”, and “error_handler” methods.
The start_requests method initiates the scraping process by sending requests to the specified URLs. The parse method handles the response from each request and extracts the desired data. The error_handler method handles any errors encountered during the scraping process.
The “configure_logging” and “get_project_settings” functions are used to set up logging for the scraping process. The LOG_ENABLED parameter is set to “True” to enable logging, the LOG_FILE parameter specifies the file to log to, and the LOG_LEVEL parameter sets the logging level to “INFO”.
Implementing error handling and logging in your web scraping project ideas. Using it, you can ensure that your scraping process runs smoothly and efficiently. It helps quickly identify and address any issues that arise.
Leveraging APIs for Web Scraping Tools
APIs provide a set of protocols and tools necessary for building web scraping software applications. They allow developers to interact with a website’s database more efficiently and predictably.
APIs can be incredibly useful as they allow for a structured and reliable way of retrieving data from websites.
Here are a few benefits of using APIs for your web scraping needs:
- Standardized interface for accessing data. It makes the data easier to process and analyze.
- Access to data that may not be available through traditional scraping methods.
- Using APIs can reduce the load on the website, preventing detection and blocking.
- Most APIs can handle large amounts of data and heavy traffic. They are less likely to encounter errors or issues.
- APIs can improve web scraping projects’ efficiency, accuracy, and reliability.
One excellent example of a user friendly API that can ease web scraping tasks and bypass restrictions is GoLogin. We’ll discuss GoLogin in detail in the next section.
The GoLogin API
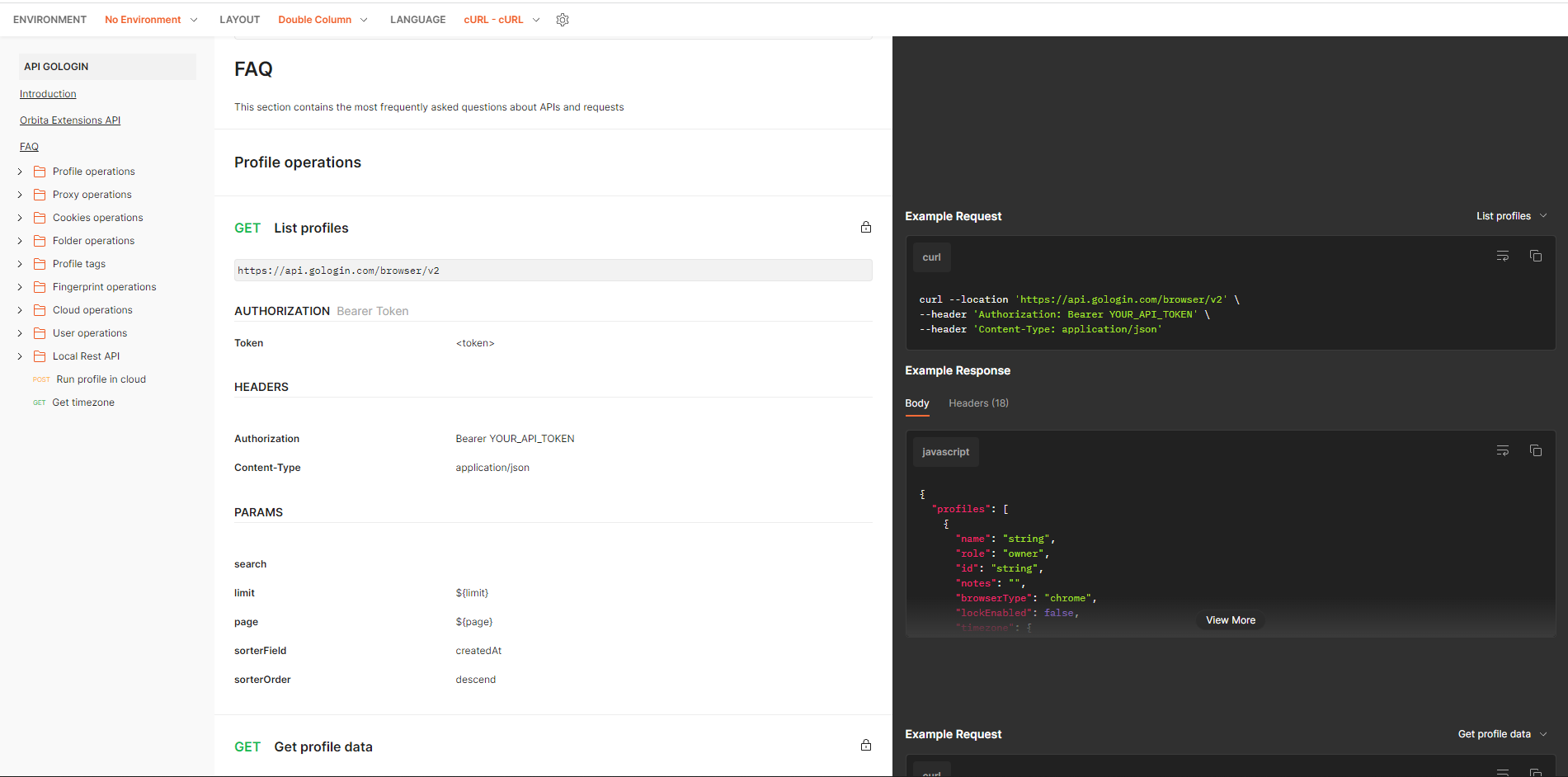
GoLogin is one of the newest web scraping tools that helps you to scrape even most complex and secure websites. Its built-in security measures ensure that your spider will not get detected and blocked.
Imagine you are a social media manager or a web dev for a marketing research company. You need to analyze your competitors’ social media presence. You must scrape data from various social media sites, like Facebook, Twitter, and Instagram.
This is where GoLogin’s API comes in. Using it, you can perform web scraping tasks on social media sites – without getting detected! The app allows you to set up many accounts from different IP addresses (and use other security measures) without writing a single line of code.
Isn’t it cool and easy? Here are the exact steps to carry that out:
Step 1: Create an account
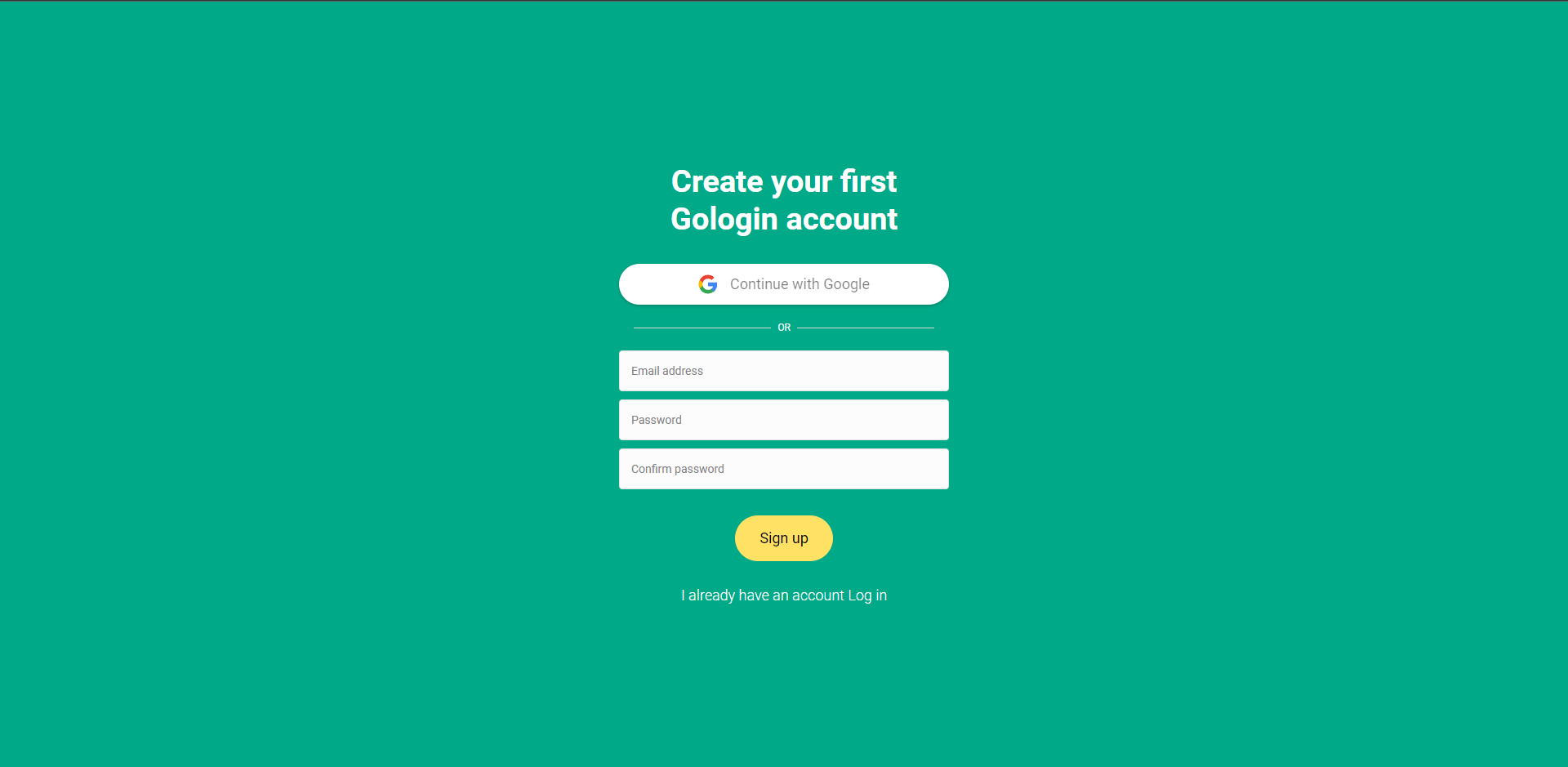
Go to GoLogin website, download the browser and generate an API key (click on New Token). You can do this by logging in to your account and navigating to the API section. You’ll be able to generate a unique API key that you can use to make requests to GoLogin’s API.
 Step 2: Choose the website you want to scrape
Step 2: Choose the website you want to scrape
Target an online platform and the required data you want to extract. Some examples could be extracting product information from an e-commerce site or scraping social media data.
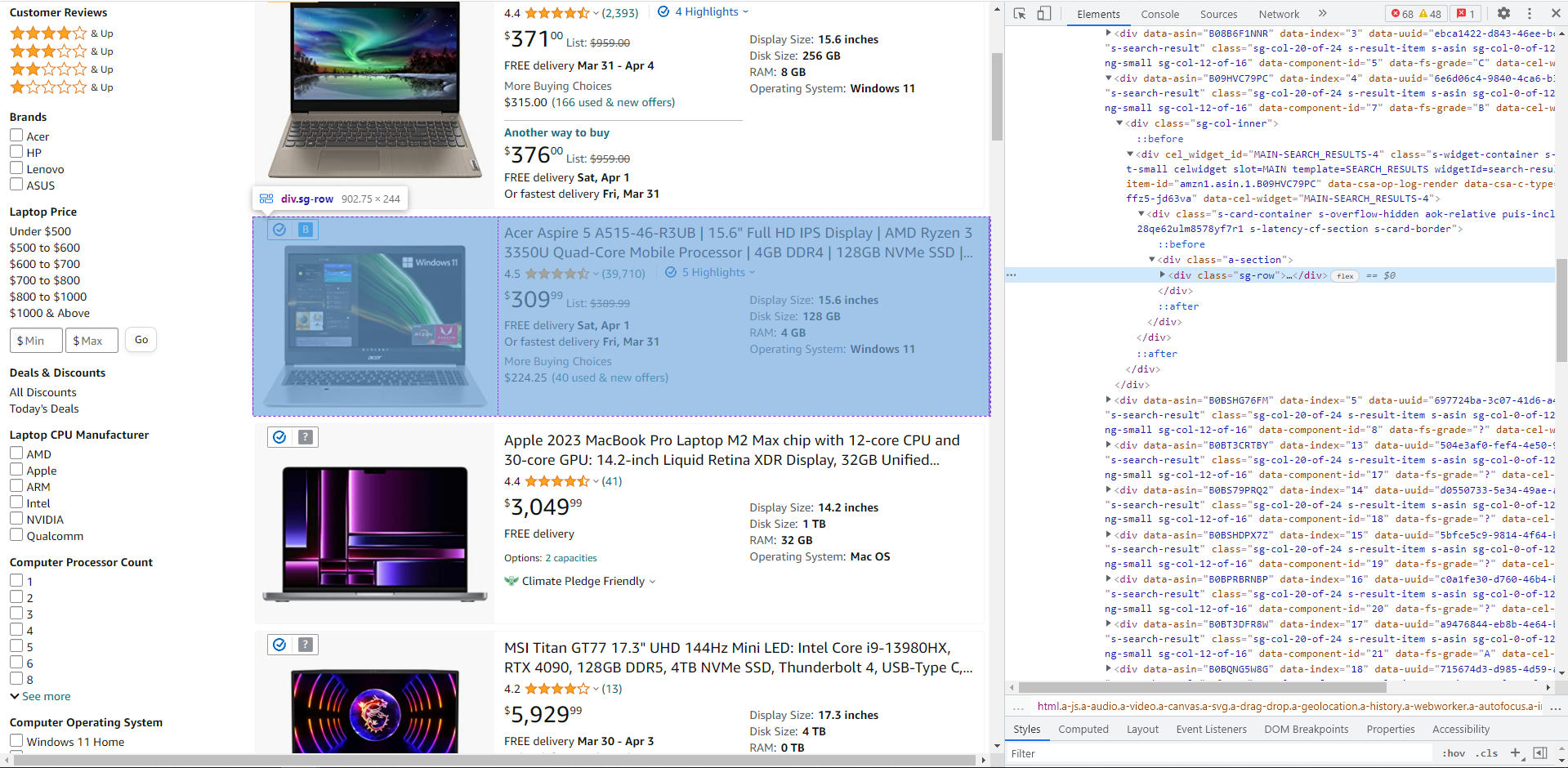 Laptop listings on Amazon.com
Laptop listings on Amazon.com
Step 3: Using the GoLogin API documentation
GoLogin API documentation provides a detailed list of available endpoints, parameters, and response formats. You can use this to customize your request based on the website you’re scraping and the data you’re extracting.
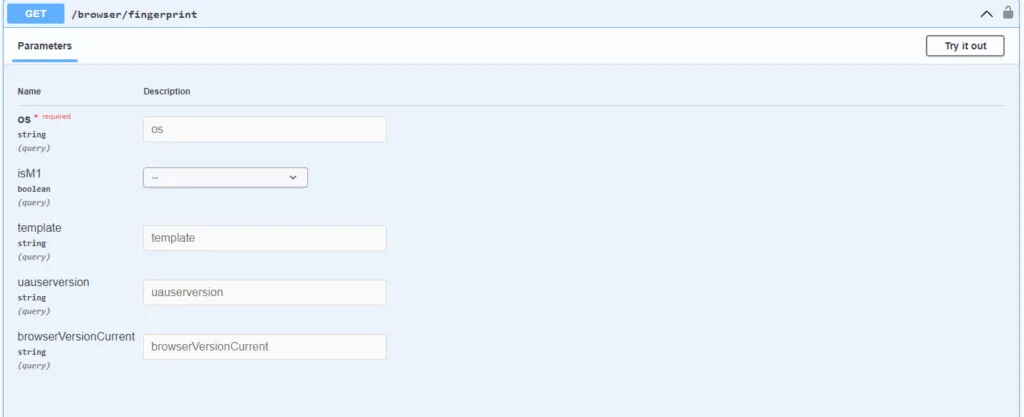 Step 4: Send the request to GoLogin’s API
Step 4: Send the request to GoLogin’s API
Then you can use your API key to send a request to GoLogin’s API. You can use any programming language that supports HTTP requests, such as Python or JavaScript. GoLogin’s API provides a RESTful interface, so you can use HTTP methods like GET, POST, and DELETE to interact with the API.
Step 5: Receive and parse the response from the API.
The response returned by GoLogin’s API will be in JSON format, so you can use a JSON parser to extract the data you need. You can then use this data for analysis, visualization, or any other downstream processes.
To further guide you, here is an example code to perform a basic web scraping task using GoLogin’s API in Python:
import requests
import json
url = 'https://gologin.com/api/v1/scraping/execute'
api_key = 'your_api_key'
headers = {'Content-Type': 'application/json', 'Authorization': f'Token {api_key}'}
data = {
'url': 'https://example.com',
'cookies': [],
'js_snippets': [],
'scroll': False,
'wait_for_selector': None,
'wait_for_timeout': 30
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
results = response.json()['result']
print(results)
else:
print(response.json()['error'])
In this example, we are making a POST request to GoLogin’s API endpoint to execute a web scraping task.
We pass the website URL, cookies, and other parameters to configure the scraping behavior. Once the request is processed, we receive a JSON response containing the scraped data.
Overall, leveraging APIs like GoLogin can greatly simplify the web scraping process while ensuring security and reliability. Using advanced techniques such as these, web scraping can become a powerful data extraction and analysis tool.
Tips for Finding and Using APIs Provided by Websites or Third-Party Services
Many websites provide APIs to allow third-party developers to access their data and create new applications or services.
For example, Twitter provides APIs that allow developers to access data about tweets, users, and other information. This data can be used for sentiment analysis, marketing research, or other purposes.
 Similarly, Google provides APIs for its search engine, which can be used to gather data on search results, keywords, and other metrics.
Similarly, Google provides APIs for its search engine, which can be used to gather data on search results, keywords, and other metrics.
To find APIs for web scraping, you can start by checking the documentation or developer resources provided by the website. Look for information about the types of data available, the methods for accessing the API, and any authentication or security measures that may be required.
If the website does not provide an API, you may be able to use third-party services that provide APIs for scraping specific websites or types of data. These services may charge a fee or require registration, so be sure to read the terms of service carefully before using them.
For example, Scrapy Cloud is a cloud-based web scraping service that provides an API for scraping data from various websites, including Amazon. With it, you can create custom spiders that crawl Amazon’s website and extract data on product prices, ratings, reviews, and other relevant information.
Other famous third-party services include Octoparse, Webhose, Apify, ParseHub, etc.
Conclusion
Advanced web scraping techniques and tips can significantly enhance the effectiveness of your web scraping projects.
Leveraging APIs and utilizing third-party services are just a few examples. By implementing these techniques, you can improve the quality and quantity of your data collection and ultimately make more informed business decisions.
GoLogin’s API is a valuable resource for web scraping projects, providing a secure and easy-to-use platform for managing multiple accounts and avoiding IP blocks. By integrating GoLogin’s API into your web scraping workflow, you can increase efficiency and improve the quality of your data.
In our next article in the series, we will comprehensively review the top web scraping tools and services available today.
Stay tuned for more and Download GoLogin to scrape even the most advanced web pages without being noticed!
FAQ
What are web scraping techniques?
- automating the retrieval of information from web pages
- parsing the HTML or XML structure
- extracting the desired data for analysis or other purposes.
Which tools are used for web scraping?
Can you get banned for web scraping?
What is an example of web scraping?
What are the different methods used for web scraping in Python?
- BeautifulSoup provides a simple and intuitive way to parse HTML and extract data.
- Scrapy is a powerful framework for building web crawlers with advanced features.
- Requests library is often used for fetching web pages and making HTTP requests in combination with other parsing libraries.
References:
- Khder M. A. Web Scraping or Web Crawling: State of Art, Techniques, Approaches and Application //International Journal of Advances in Soft Computing & Its Applications. – 2021. – Т. 13. – №. 3.
- Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
- Sirisuriya D. S. et al. A comparative study on web scraping. – 2015.
- Zhao B. Web scraping //Encyclopedia of big data. – 2017. – Т. 1.
- Dale K. Data Visualization with Python and JavaScript. – ” O’Reilly Media, Inc.”, 2022.
- Smith V. Go Web Scraping Quick Start Guide: Implement the power of Go to scrape and crawl data from the web. – Packt Publishing Ltd, 2019.
- Clark T. Storage virtualization: technologies for simplifying data storage and management. – Addison-Wesley Professional, 2005.
- Norberg S., Norberg S. Logging and Error Handling //Advanced ASP. NET Core 3 Security: Understanding Hacks, Attacks, and Vulnerabilities to Secure Your Website. – 2020. – С. 321-353.


