Does scraping apps require any specific web scraping services? Why scrape apps in the first place?
In this article we’ll be inspecting the app network traffic with Fiddler Everywhere – and scrape the data from the app servers.

Why Scrape Data From an App?
I usually write in this newsletter about how to extract data from websites but what if our target is an app with no web interface? Or if the website is too complex to scrape and, knowing the target has an app, we want to test if there’s another door to access the data.
Since we cannot see the source code of the app, we must intercept the requests made from it to its servers and try to replicate them in our scraper.
To do so, we need a network traffic analysis tool. In this post, we’ll use Fiddler Everywhere to support us, but there’s plenty of similar web scraping services software on the market, like Wireshark.
How Fiddler Everywhere Works
Fiddler works like a “man-in-the-middle” between your target app and its servers.
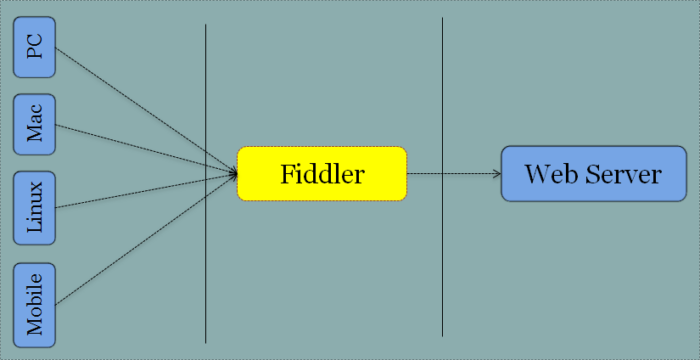
First of all, we need to install Fiddler on our computer and set it up to decrypt HTTPS traffic, as described on this page.
The second step is to find out the IP of our computer and configure the network on our mobile phone, where the app is installed, to use our computer as a proxy, using the port opened by Fiddler to route the network traffic.
From now on, every request made by our mobile to external servers will be shown in Fiddler. This is extremely interesting to understand what happens after the installation of a new app and to find out hidden calls to external services we are not aware of.
Start Scraping From an App: A Real Case
Going back to our web scraping services, let’s see a real-world case of how to use Fiddler.
We’ll use the app of the well-known streetwear brand Off White as an example, even if they have a website to scrape data from.
Before starting our test, let’s close all the apps on the phone in the background to reduce the noise in the requests made by our phones.
As soon as we open the app, we will see all these requests to Facebook and the Off-White internal API.
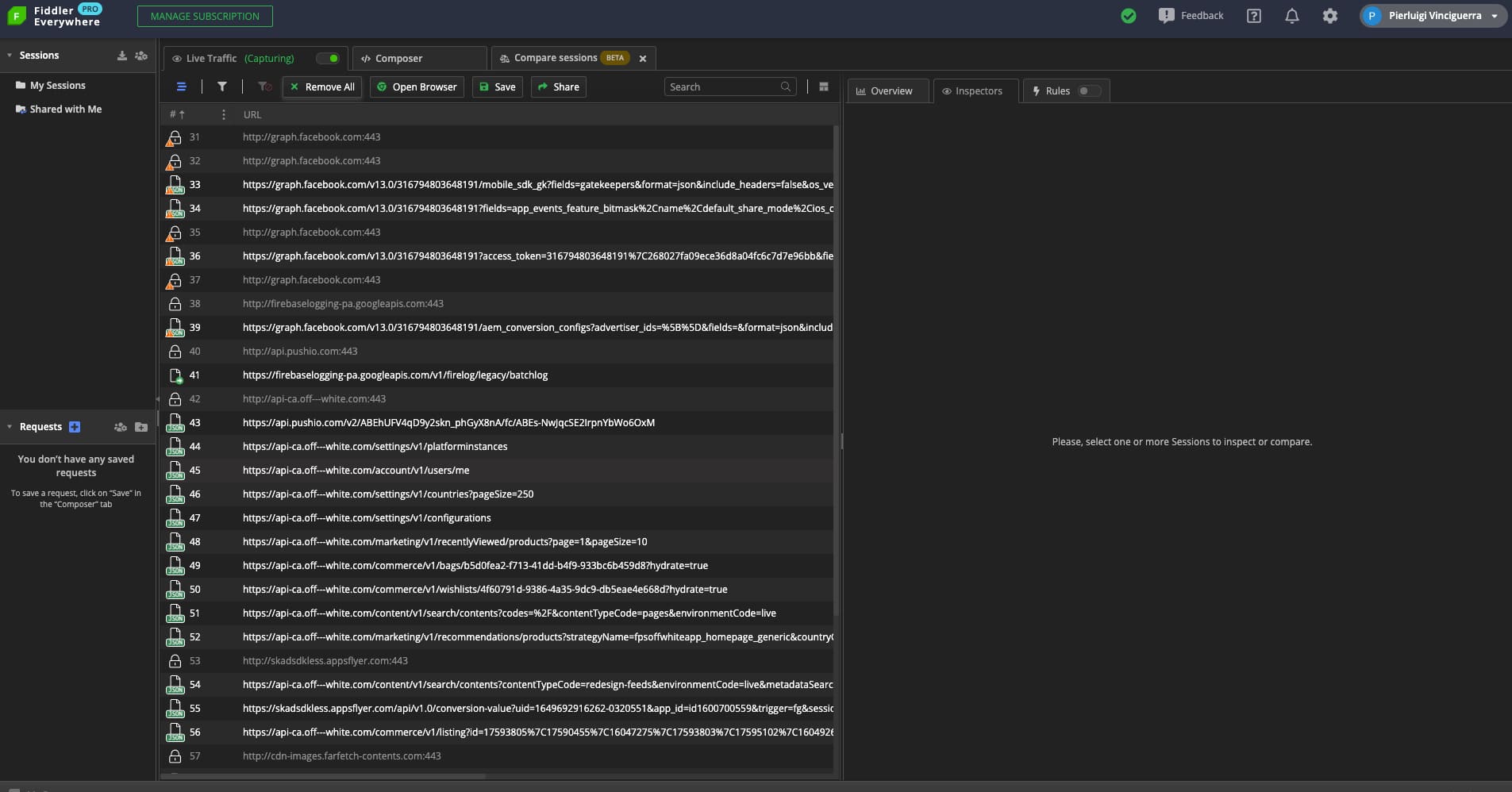
Let’s try to open a catalog page to see what happens.
I browsed to man’s ready-to-wear and, after entering the section, noticed this request.
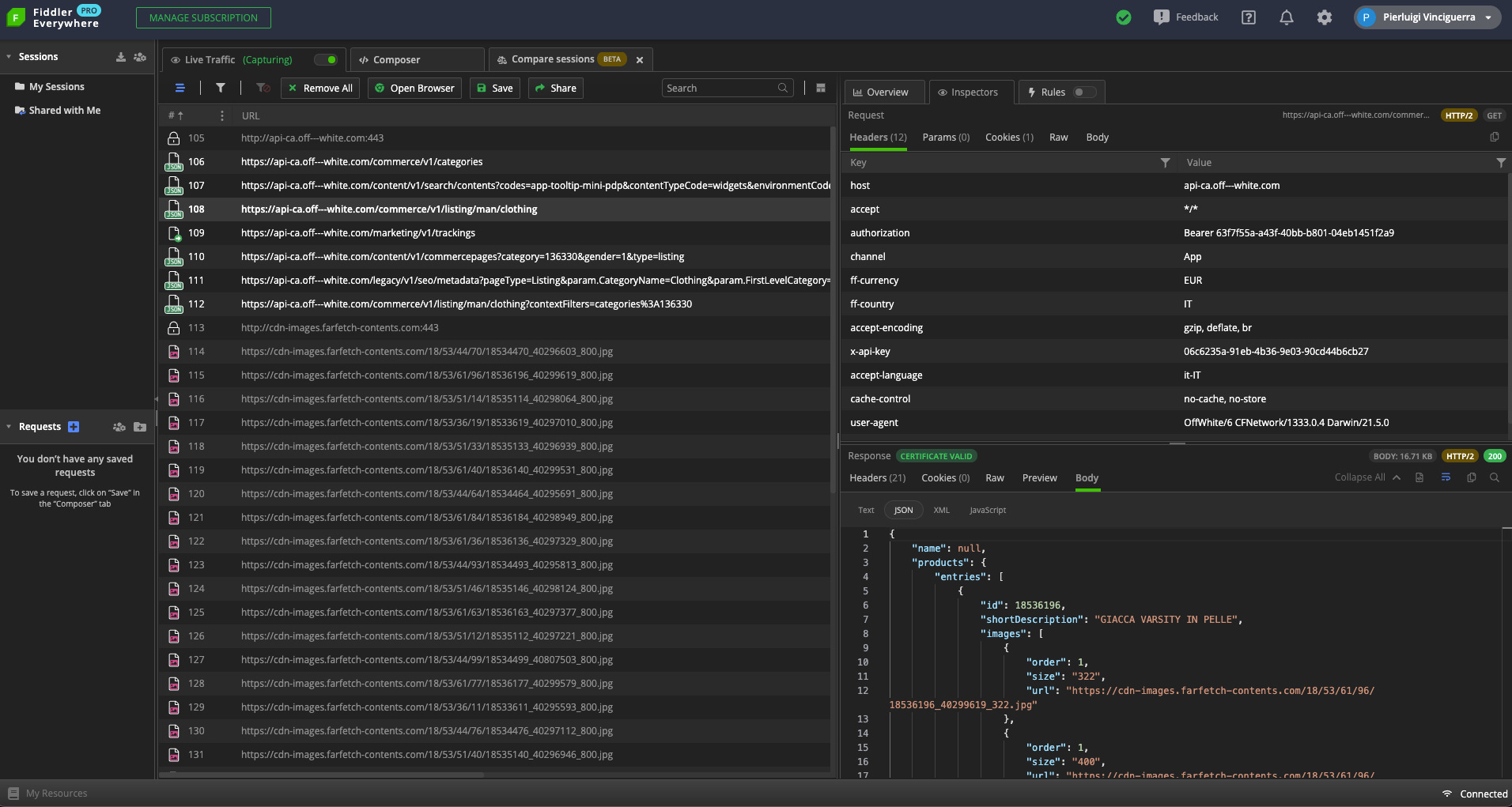
Bingo!
There’s a web scraping API that retrieves the product information from the server.
Let’s try to replicate the same request, with the same headers, on a Scrapy project to see if it works.
I’ll start with a basic scraper, that requests only this API call, so after starting a new project in Scrapy, my spider will look like the following.
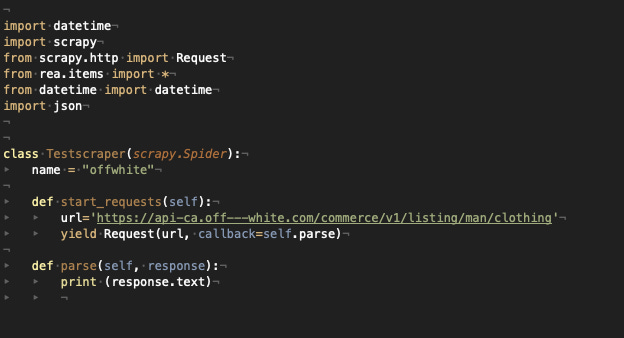
While the settings.py file will have the variable DEFAULT_REQUEST_HEADERS set with almost all the headers we read on Fiddler.
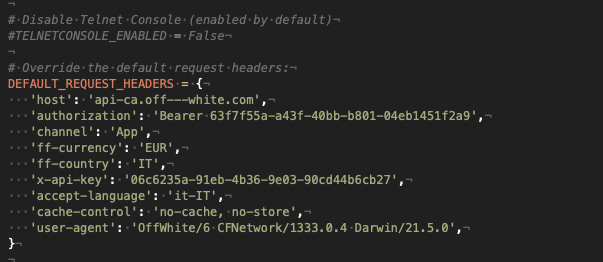
As you may have noticed, I’ve deleted the “Accept” and “Accept-Encoding” voices, otherwise, Scrapy would mess out with the response output format.
I’ve deleted also the Cookie parameter because I wanted to be sure that this configuration will work also in the future and not only now because we have the right Cookie assigned.
At the moment we’ll use the Bearer token read from Fiddler even if probably it won’t work in few hours, but we’ll see later how to get it dynamically.
The scraper should print the resulting JSON on the terminal.
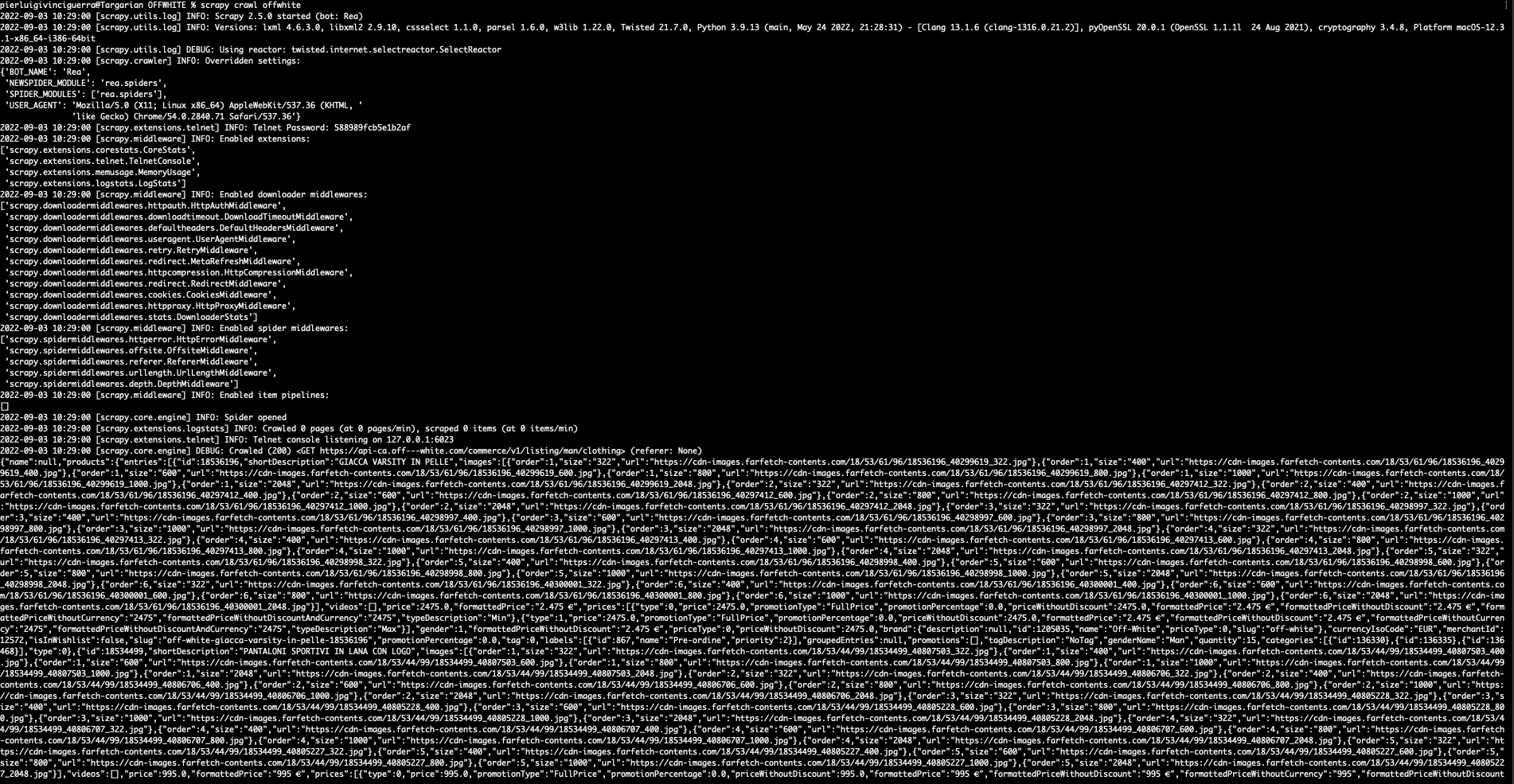
It works!
Now let’s define the Item properties and fields and read the JSON. I suggest copying the whole JSON output into any online formatter tool, like https://jsonformatter.curiousconcept.com/, it helps a lot to understand its structure.
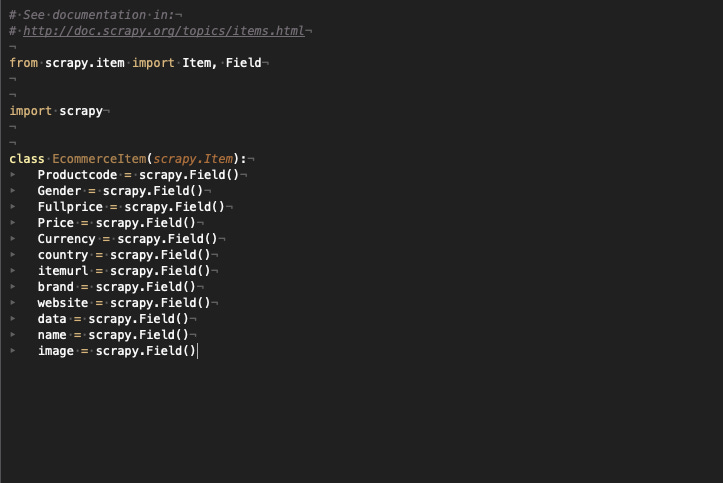

Let’s use the JSON structure to assign fields to Item fields, the scraper will run like the following.
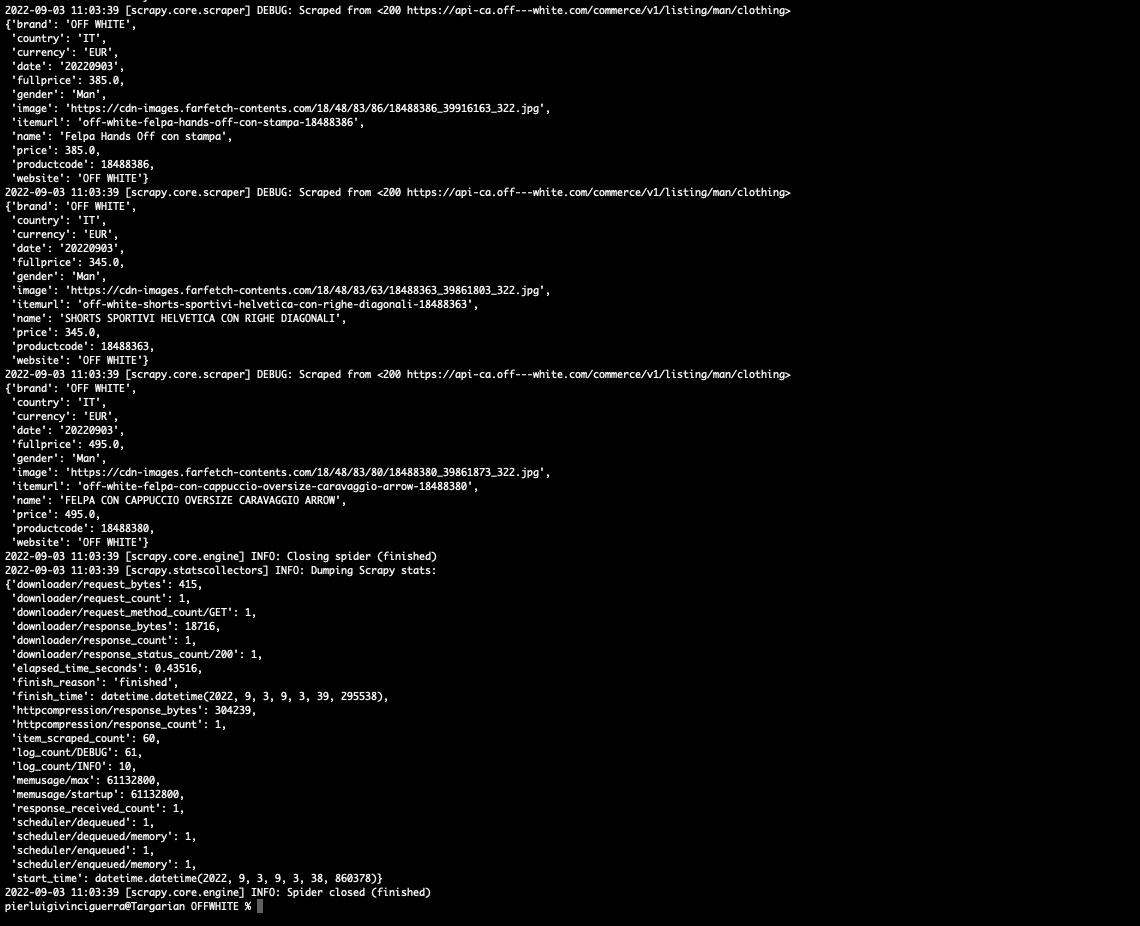
60 items scraped, perfect, the same number as the items in the JSON!
***
This article was kindly provided by Pierluigi Vinciguerra, web scraping expert and founder of Web Scraping Club. Follow this link to see the original post.
Download GoLogin here and explore the scraping world with our free plan!


