
What is Cloudflare
Cloudflare is one of the most well-known anti-bot solutions. Bypassing it is a difficult challenge for any web scraping project. But are there any best web scraping tools for that? In my past articles, I’ve written several times about bypass Cloudflare using different approaches. I will summarize them in this post.
Undetected Chromedriver
We have seen in the Anti-Detect Anti-Bot matrix post that a good service for web scraping with Python against Cloudflare could be the Undetected Chromedriver python package.
Basically, it consists of a Chromedriver version modified for specific usage in web scraping projects. Combined with Selenium, you can automate most of the Chromium browsers. So it’s not only Chrome then, but also more secure options like GoLogin.
The setup for this solution comes in two easy steps.
1. Setting up the connection to the chromedriver. After importing the package, with a few lines, we can load a page and eventually take a screenshot, like in this example.
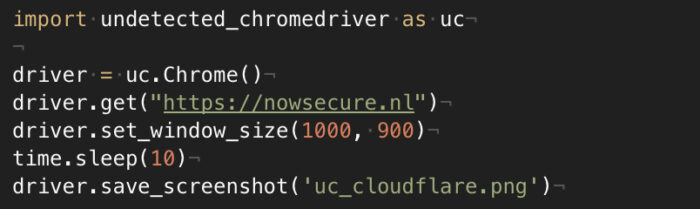
2. Then, using Selenium, we can extract data from nodes using its classical syntax, as described in the documentation.

Playwright
In this blog, we often write about Playwright, because of its ductility and its ease to use. As an example, in one of the latest “The Lab” posts we have seen how to use it together with GoLogin, but it’s not the only setup we can use. It supports natively all modern rendering engines including Chromium, WebKit, and Firefox so we can have a lot of fun testing around which solution fits the best for our needs.
During the last 4-5 months I’ve noticed that the one of the best web scraping tools to bypass most of the Cloudflare-protected websites consists in using Firefox together with Playwright, as stated also in our Anti-Detect Anti-Bot matrix.
Even in this case, the setup is quite easy.
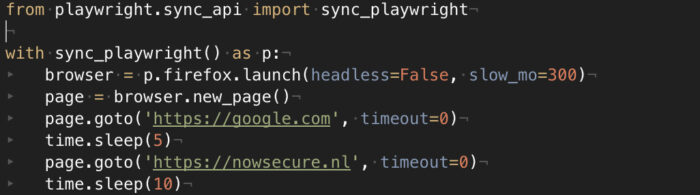
After importing the package, we set up a Playwright session (sync or async, depending on your needs for multi-threading and parallelism) and then we load the page in the browser we prefer.
The different options and setups we can try are countless but I’m bringing to attention some of them I’ve found useful.
- slow_mo: in the previous example you have noticed I’ve added this option when creating an instance of Firefox. It’s an option to slow down, in milliseconds, the execution of the commands. It happened to me that scrapers launched and working from my laptop did not work from VMs on data centers. Changing only this option allowed me to make it work, probably because the connection or the hardware of the servers was too much performing compared to the average desktop machine and the anti-bot used the execution speed as a red flag.
- launch_persistent_context: using this option, Playwright will create (if it does not exist) a directory where it will store all the files the browser usually stores when executing (cookies, history files, and so on). This is useful when you need to show the anti-bot you’re not using a brand-new user profile but one with some history. You can use this option as follows
browser = p.chromium.launch_persistent_context(user_dir, headless=False)
Conclusions: Are There Best Web Scraping Tools?
Yes, Cloudflare can be a pain to bypass, especially on some websites where the rules for detecting bots are strict, but usually these configurations damage also real users.
We have the means for bypassing the anti-bot solution, but it all depends from case to case and there’s no silver bullet for it. And if there was, it would work only until the next release. It’s always a cat-and-mouse game and techniques need to be always updated. The only permanent condition is to treat target websites respectfully and ethically, to not cause harm or malfunction.
Download GoLogin here and explore the scraping world with our free plan!


