In this short article we will test Scrapy Playwright and discuss the nearest future of web scraping. Browser fingerprinting and anti-bot solutions are evolving fast, making old methods and tools obsolete.
How does a good scraper keep up with the progress?


Rising Costs and Difficulties: Scrapy Playwright Is Losing It?
Do you have the feeling that scraping data from website is becoming more difficult and expensive?
I do, especially in the last 12 months, I’ve noticed an increasing number of websites using advanced anti-bot solutions to protect their public data.
But what do I mean when I say “advanced anti-bot solution”?
In the past, when websites were much less sophisticated and scraping data from website techniques quite plain, checking the number of requests for a certain IP or the user agent, combined with a well-configured robots.txt file, was enough to stop the scrapers.
Solutions like IP rotation via proxies and change of settings of headless scrapers like Scrapy requests were and still are enough to avoid blocks and get all the data needed.
The increasing number of bots and their fraudulent use pushed websites with a larger budget to adopt more complex and harder-to-bypass anti-bot solutions to fight them. These systems generally rely on two main factors:
- AI to detect anomalies in the behaviors of the user
- active fingerprinting analysis
Behavioral analysis helps greatly when there’s the need to stop fraudulent bots, like the ones that try to buy as fast as they can the latest drop of a sneakers collection or make some brute force attack on website credentials.
In our case, we at databoutique.com we’re experts in scraping public data on major e-commerce so browsing a product catalog is an action a real user does very often so we do not incur this kind of block very often.
The major issue we’re facing recently is related instead to active fingerprinting, which lead us to study a completely new toolkit and configuration to use in the hardest situations.
What Is “Active Fingerprinting”?
When we make an HTTP request to a server, our browser sends a header with it.
Reading all the header data, together with the requesting IP, and creating a unique hash string from this information is called passive fingerprinting. The server does not need to retrieve actively any information from the client, since everything it needs is included in the request itself.
When the server runs also some Javascript to get information about the client used for the requests, it’s called active fingerprinting.
In this category we can have different types of fingerprints: when these scripts gather information about the browser configuration, this is called browser fingerprinting. When the scripts gather information about how the browser renders images and fonts, this is called canvas fingerprinting.
The two fingerprints combined return to the marketing team of the website a huge amount of data without even installing any cookies on the client.
Anti-bot softwares instead use a catalog of fingerprints that correspond to common installations, to cut out requests coming from configurations that are not coming from traditional configurations.
Implications for Scraping Data From Websites
These checks on fingerprints imply that a scraper written with Scrapy cannot be enough for reading the content of the target website but we need a real browser, configured to mimic a real user environment.
For this scope, we’re using a tool called Playwright, a framework for automated testing of websites using headful browsers and we’ll see together how to configure it to mimic real humans browsing the website.
Assessment: Who Is a Real User?
The first step of the process is to understand what’s the current configuration of the browser of a human, like ourselves as an example.
To have a look at all the variables set in a default installation of Chrome, as an example, let’s go to the Console tab inside the Developers tool, write “window” and then press Enter.

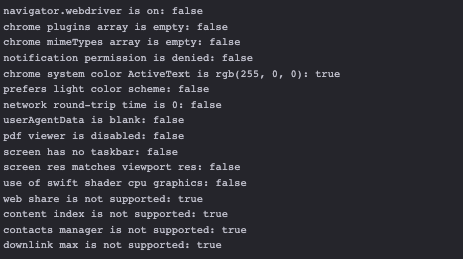
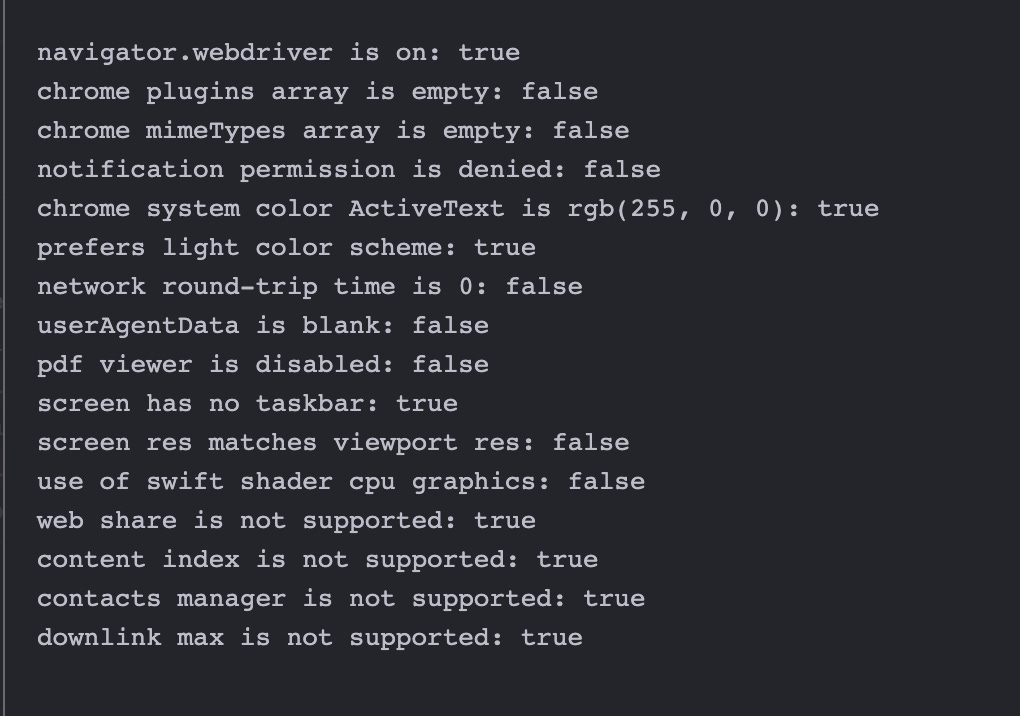
We will get the full list of hundreds of variables and some of them will be checked from anti-bot software via Javascript to create the fingerprints and find incongruences with a real human user.
One option is key: window.navigator.webdriver is set to False in the most recent versions of Chrome and null in the previous, while True in the standard version of Chromium installed with Playwright pages.
Since comparing all the hundreds of variables inside Chrome with our Playwright setup will take too much time, we’ll use some websites that test for us the most common variables and help us to find what to improve.
Some useful websites to test our settings are:
- https://antoinevastel.com/bots/ by Antoine Vastel, Head of Research at Datadome, an anti-bot solution
- https://bot.incolumitas.com/ is a list of tests collected by several websites
- https://abrahamjuliot.github.io/creepjs/ another set of tests about the browser and canvas fingerprint, I think the clearest one
Let’s Start With The Tests
Baseline
This is what happens when I take the test with my Chrome installation for scraping data from website.
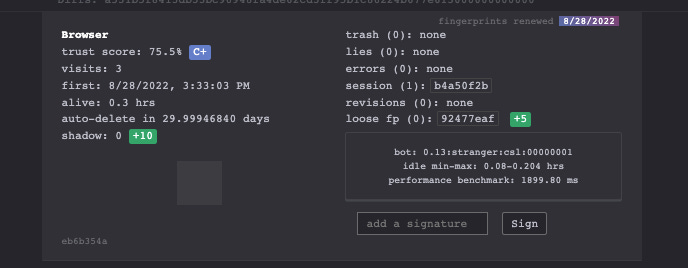
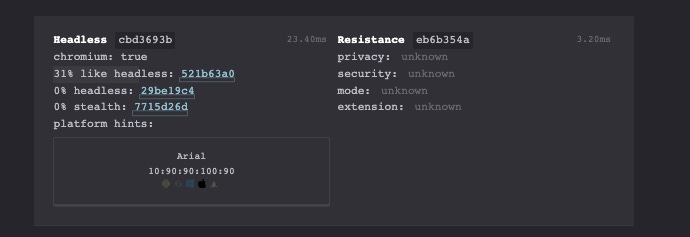
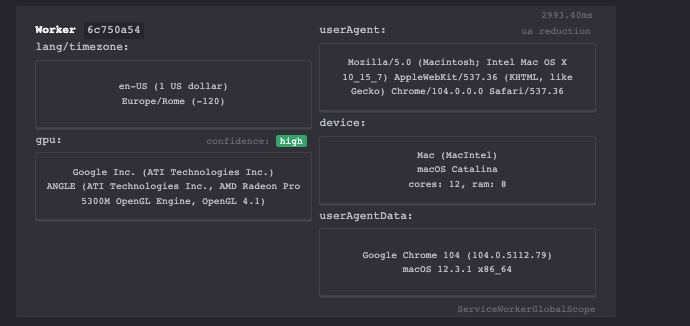
First Run – Plain Playwright with Chromium
Let’s compare it with what happens when we run the same tests with Scrapy Playwright, without any configuration. Below there is the code for the test and then the images, where in red I’ve highlighted the main differences from the previous run.
import scrapy from scrapy.http import Request, FormRequest from playwright.sync_api import sync_playwright from random import randrange import time class PhaseASpider(scrapy.Spider): name = "start" def start_requests(self): with sync_playwright() as p: browser = p.chromium.launch(headless=False) self.page = browser.new_page() url='https://abrahamjuliot.github.io/creepjs/' self.page.goto(url, timeout=0) interval=randrange(300000,500000) time.sleep(interval)
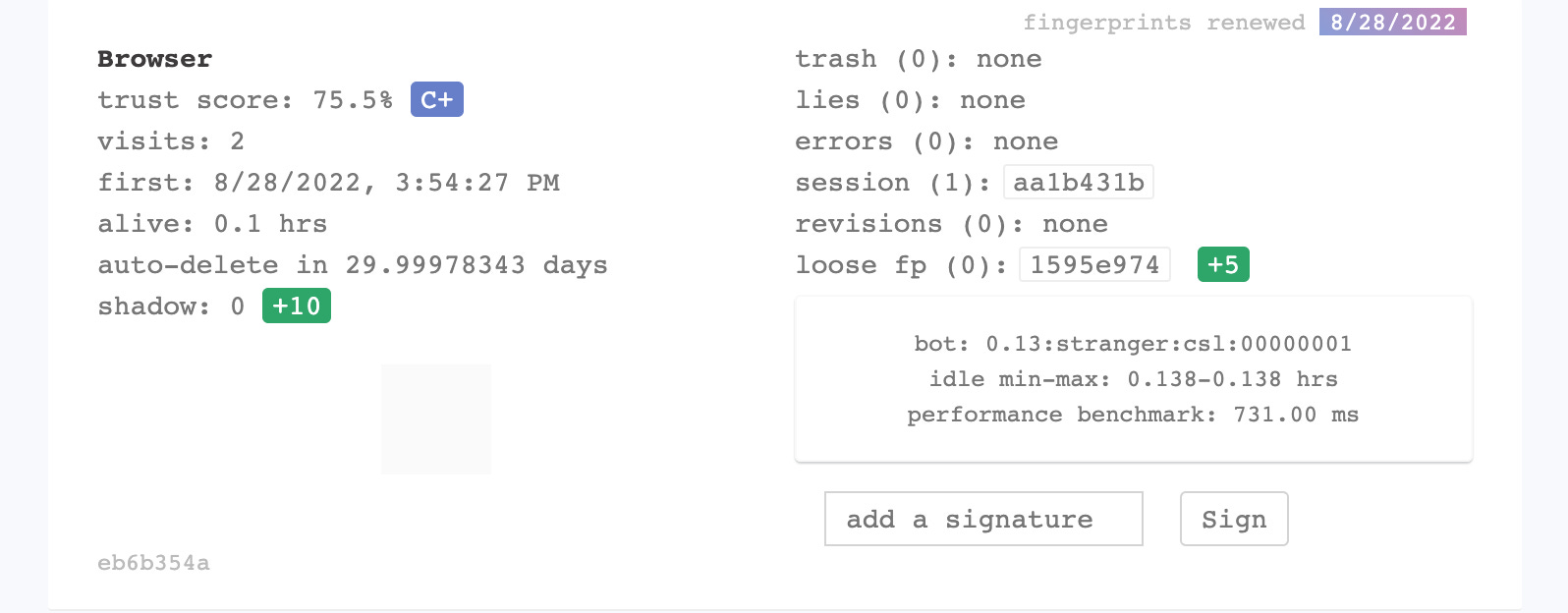
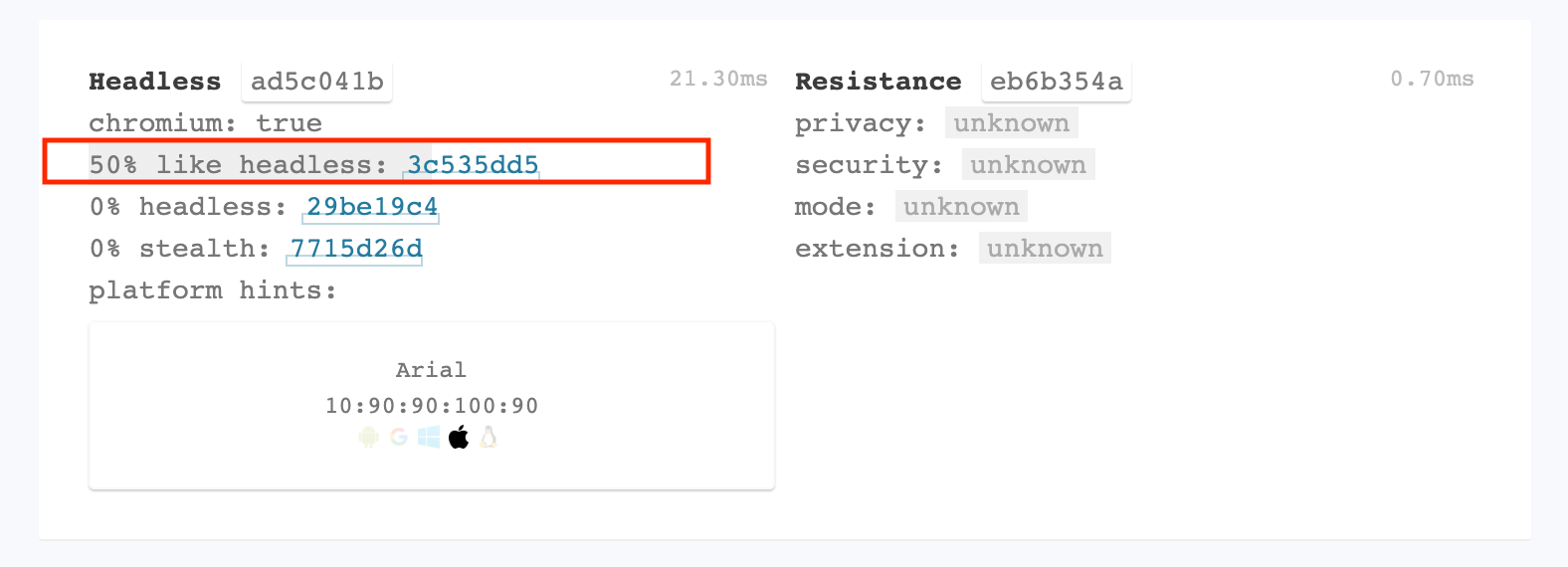
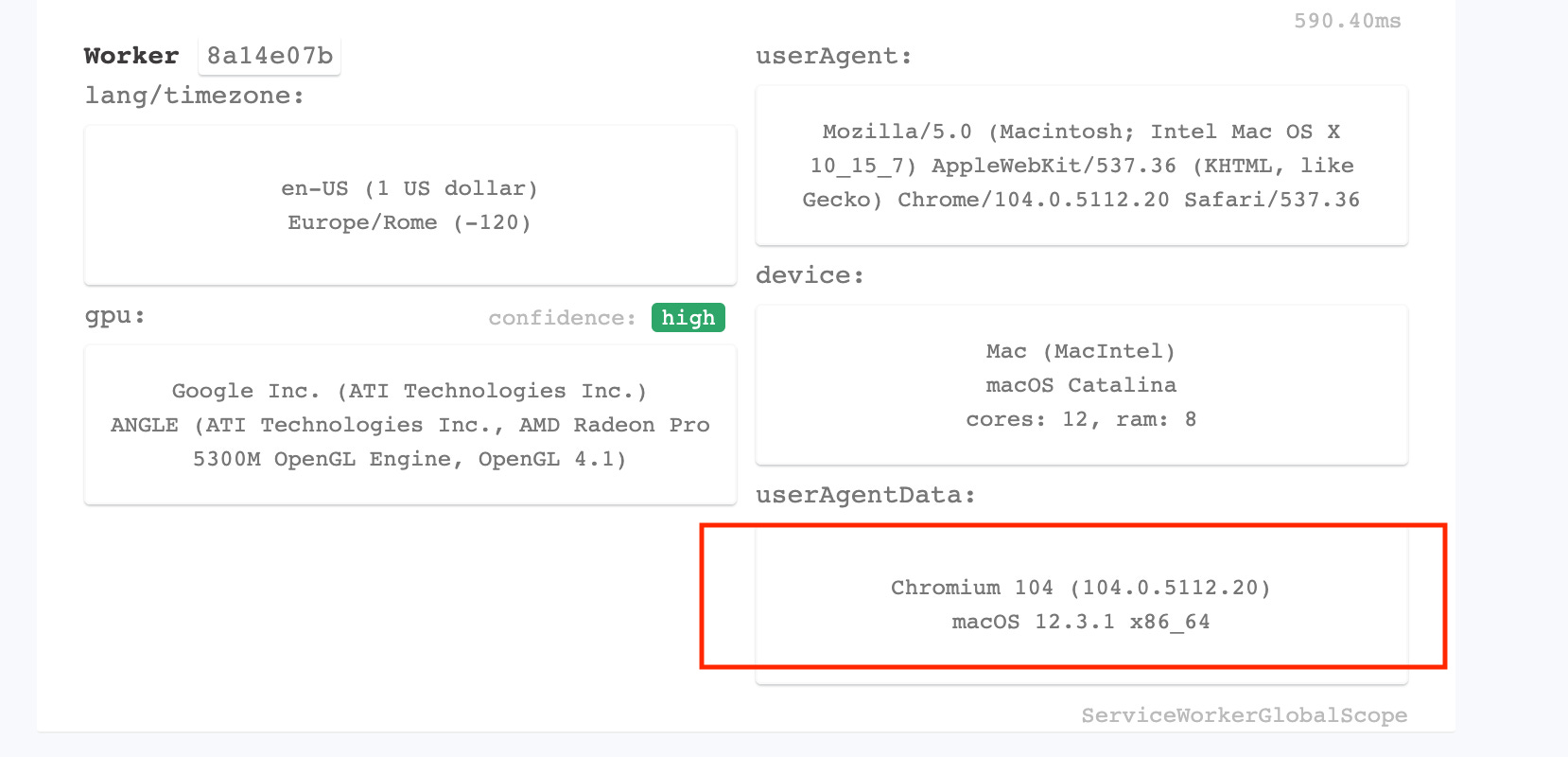

As we expected, Playwright is doing nothing to hide the usage of a Chromium webdriver and sets also the flag navigator.webdriver to True.
Second Run – Scrapy Playwright with Chrome
Let’s make a small change to the code, to use an headful installation of Chrome instead of Chromium Webdriver.
browser = p.chromium.launch(headless=False, channel="chrome")
Running again the test, the improvements are marked in green.

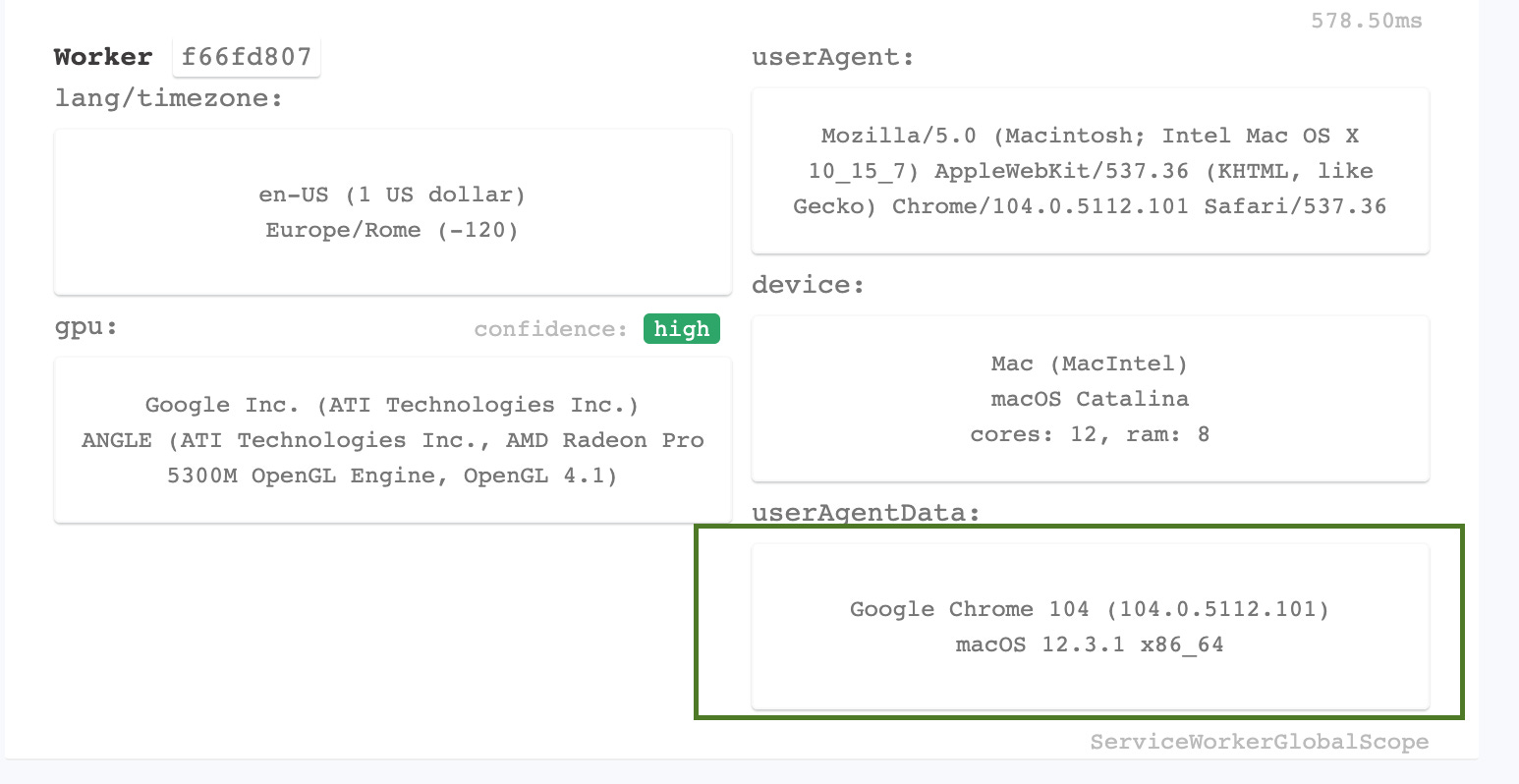
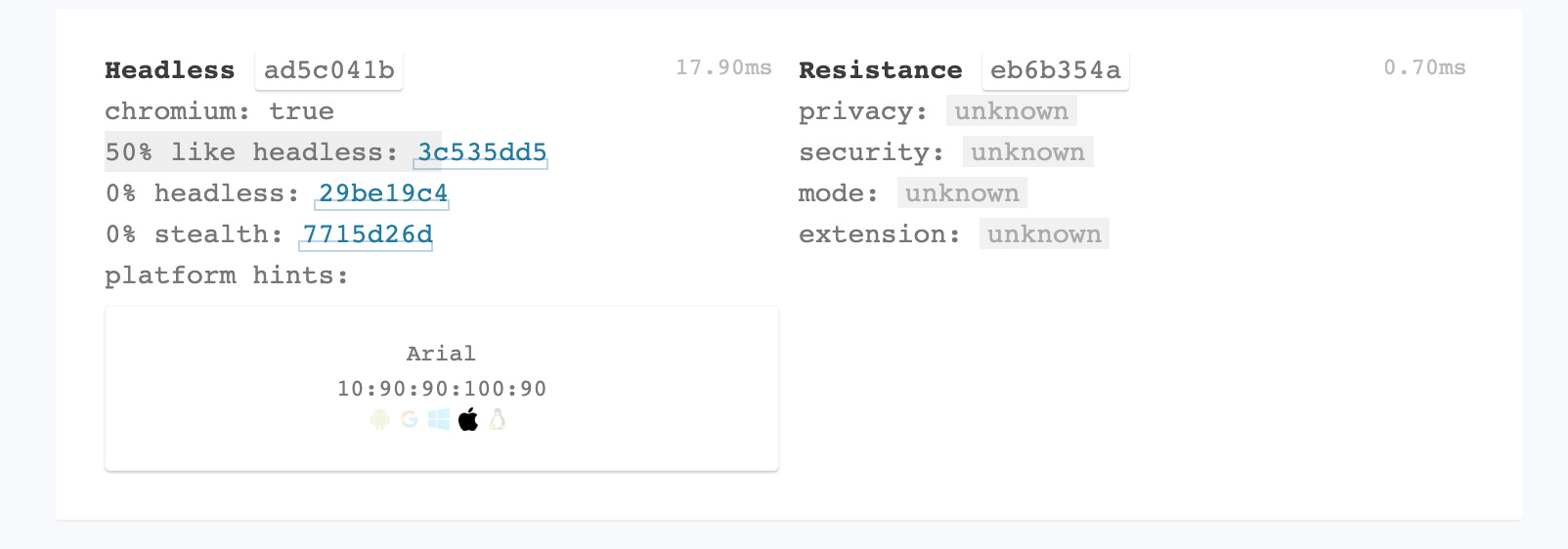

User agent data of the worker improved as expected but still no improvement in navigator.webdriver flag.
Third run – Scrapy Playwright with Playwright Stealth
Let’s add then the playwright-stealth plugin, a Python package that sets a list of sensible variables to hide the fact we’re running an automation tool.
import scrapy from scrapy.http import Request, FormRequest from playwright.sync_api import sync_playwright from random import randrange import time from playwright_stealth import stealth_sync class PhaseASpider(scrapy.Spider): name = "start" def start_requests(self): with sync_playwright() as p: browser = p.chromium.launch(headless=False, channel="chrome") self.page = browser.new_page() stealth_sync(self.page) url='https://abrahamjuliot.github.io/creepjs/' self.page.goto(url, timeout=0) interval=randrange(300000,500000) time.sleep(interval)
Run again the test and now the differences will be highlighted in blue.
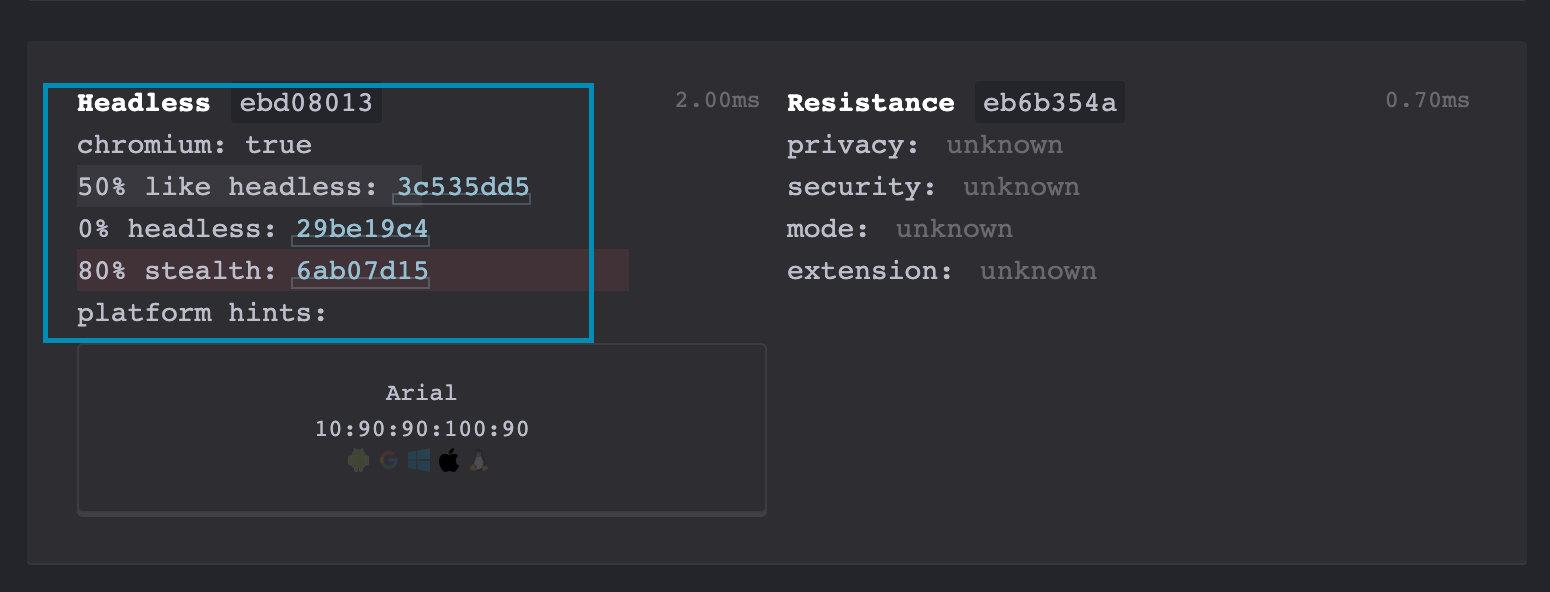
Things seem to worsen but there’s a reason why. The stealth plugin development stopped one year ago and the changes that make now in the variables of Chrome are seen as incongruent with the most advanced tests like the one we’re doing.
An example is the navigator.webdriver variable is not set, but as we said before from release 104 of Google Chrome should be set to false.
The need of being regularly updated reflects also on test websites. In fact, if we run the test on incolumitas, the webdriver option seems ok.

For now, in our experience, the stealth plugin still makes its job but we’re planning to release our version of it, to make it more robust and up-to-date.
Final thoughts on Scrapy Playwright and Browser Fingerprinting
This article reflects on the difficulties around scraping data from websites, which is becoming a more complex and expensive task.
It’s a continuous research of the tools needed to solve the issues we’re facing and this means also staying up-to-date with browser releases and anti-bot techniques.
As we have seen, tools risk becoming obsolete in a year if there’s not a regular update, and in this cat-and-mouse game wins who runs faster.
This article was kindly provided by Pierluigi Vinciguerra, web scraping expert and founder of Web Scraping Club. Follow this link to see the original post.
Download GoLogin here and explore the scraping world with our free plan!


