
Web scraping Reddit and extracting data from there is easy, if you follow certain rules.
Is there one proper way for web scraping Reddit? What tools work best? Can scrapers avoid bans?
Let’s find out!

What Is Web Scraping?
Using a technique called web scraping , you can automatically collect data from Reddit or any other website. It entails the use of computer programs called web scrapers or spiders to browse websites and extract data such as text, images, links, and other content.
Depending on the target website and the requested data, there are various methods for web scraping. It is simpler to extract data from some websites because they offer it in a structured style, such as through an API. Other times, Reddit scraper must parse a website’s HTML code in order to collect data, which might be more difficult.
Python, R, and Selenium are just a few of the computer languages and tools that can be used for web scraping. Web scrapers can use these technologies to automate the procedure of viewing websites, submitting forms, and data extraction.
Why Web Scraping Reddit Is Worth Attention
Online scraping is crucial because it makes it possible for businesses, individuals, and academics to swiftly and effectively collect data from the internet. Web scraping is now a crucial method for gathering and evaluating data due to the growing amount of information available online.
These are some specific use cases for web scraping:
- Market research: Businesses can use web scraping tools to gather market data and competitive intelligence, such as pricing information, product reviews, and customer sentiment.
- Lead generation: Web scraping with Python can help businesses generate leads by gathering contact information from websites, such as email addresses and phone numbers.
- Content aggregation: Web scraping can be used to collect content from multiple sources, such as news articles, social media posts, post titles and full blog posts, to create a comprehensive resource for a specific topic.
- Data analysis: Web scraping allows researchers and analysts to collect and analyze data for various purposes, such as studying consumer behavior, tracking trends, and conducting sentiment analysis.
Overall, data scraping is a powerful tool that can speed up decision-making, offer insightful data, and reduce time spent on research. It should, however, be used ethically and responsibly, following the terms of service of the websites being scraped and safeguarding the privacy of people.
What Is GoLogin?
GoLogin is a secure browser for managing several online identities. It is used by web developers to protect their spiders from detection on advanced platforms like Facebook, Google, Cloudflare and others. It offers users a private environment for web browsing, the ability to create and manage several browser accounts, and the ability to automate web scraping operations.
Users can establish and maintain several profiles with GoLogin, each with its own set of parameters. They will not overlap. This enables users to sign in to multiple Reddit accounts on the same website at once without being seen.
Even tracking monsters like Meta and Amazon don’t see users are working in GoLogin: they are seen as regular Chrome users. This is a game changer for businesses and people who need to maintain many social media, ad or e-commerce accounts – and, of course, scrapers.
GoLogin enhances scraping in addition to managing identities, enabling users to use pre-built or custom scrapers to harvest data from websites without being banned. Businesses and researchers who need to collect data for market research, competitive analysis, or other purposes may find this both necessary and extremely valuable.
How GoLogin Helps Developers
GoLogin can help developers scrape websites more efficiently and securely in several ways:
- Secure browsing environment: GoLogin provides a secure and private browsing environment for web scraping, protecting user data and preventing detection by websites that may block spiders.
- Multiple browser profiles: GoLogin allows developers to create and manage multiple browser profiles, each with its own set of cookies, browser settings, and online identity. This allows developers to log in to multiple accounts on the same website simultaneously without being detected. It also helps a lot creating apps: you can test your app by sending requests to it from all around the world using browser profiles and proxies.
- Automated web scraping: GoLogin offers automation options that let developers easily automate web scraping tasks with common tools and extract data from websites more efficiently.
- Proxy server integration: GoLogin supports all common proxy types and offers built-in proxiy deals, allowing developers to scrape websites from different IP addresses and locations, which can help avoid detection and prevent websites from blocking scrapers.
Overall, GoLogin can help developers scrape websites more efficiently and securely by providing a secure and private browsing environment, allowing multiple browser profiles and automating web scraping tasks, and supporting integration with proxy servers.
Using Selenium for Web Scraping Reddit on Windows
There are many technologies that may be used to perform scrape jobs, which is a potent method for gathering data from websites. Web scraping can be done with Selenium, a famous automation tool. The capability to interact with web pages, model user behavior, and automate operations are just a few of the characteristics that make it an effective web scraping tool.
Set Up Selenium On Your Computer
To use Selenium with Python , you’ll need to have Python installed on your computer. You can download Python from the official Python website. Once you have Python installed, you’ll need to install the Selenium package by running the command *pip install selenium* in a command prompt or terminal window.
Importing Driver
Selenium requires a web driver to interact with web pages. You can download the web driver for your preferred web browser from the official Selenium website. Once you’ve downloaded the web driver, you’ll need to specify its location in your code by adding a few lines of code at the beginning of your script.
from selenium import webdriver
driver = webdriver.Chrome('/path/to/chromedriver')
#
#
#
driver.quit()
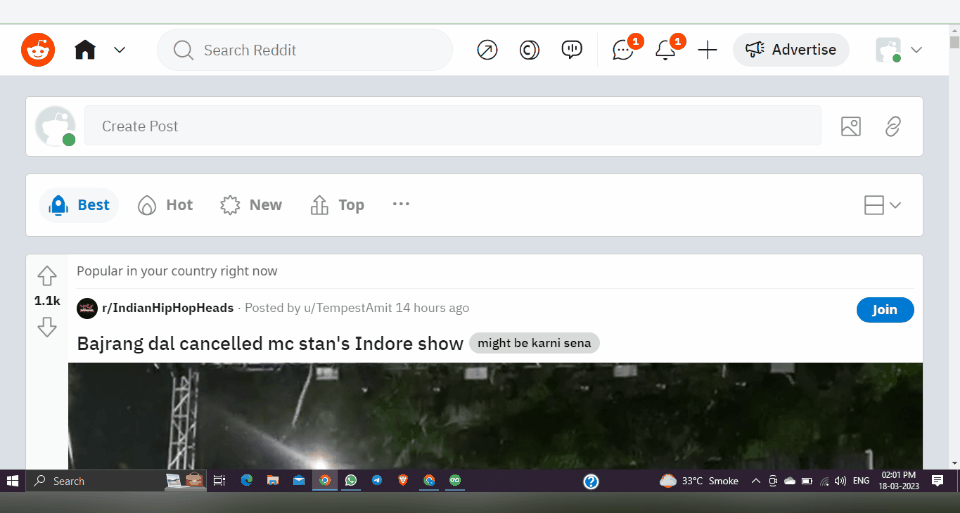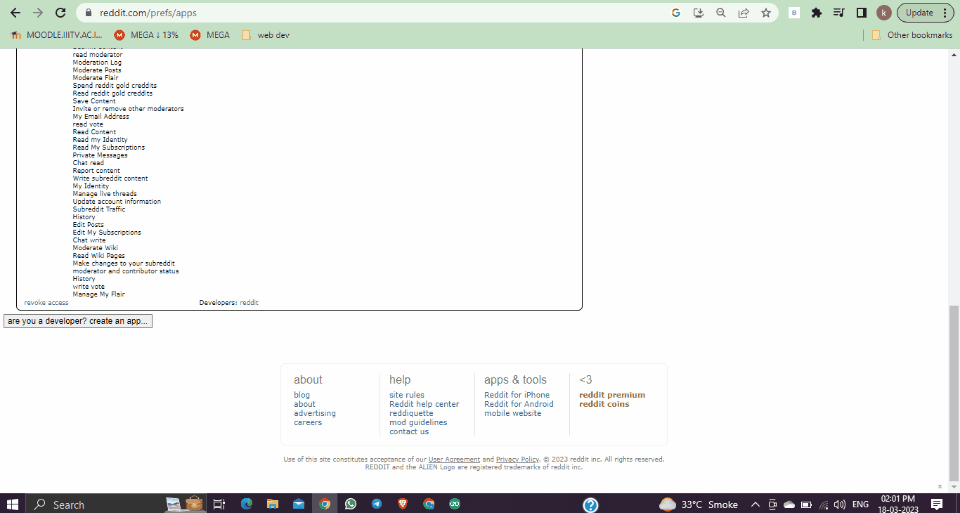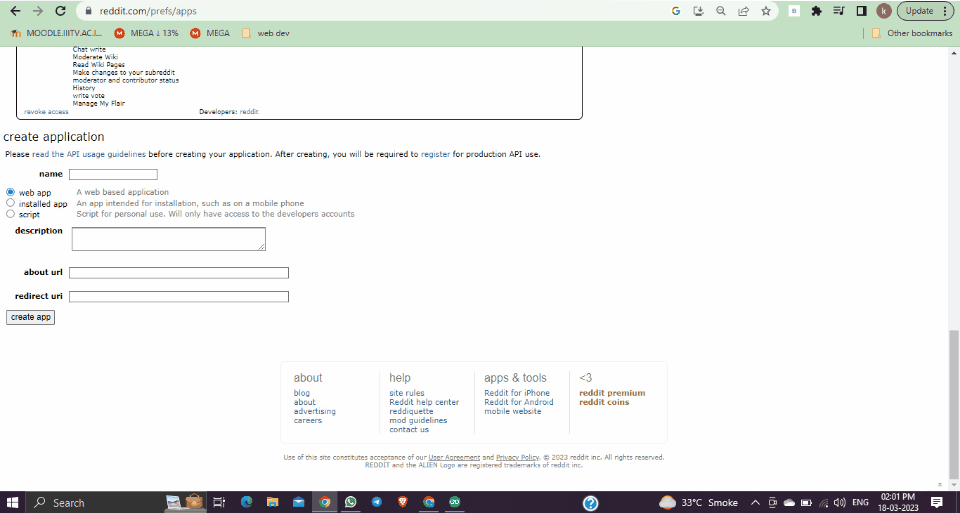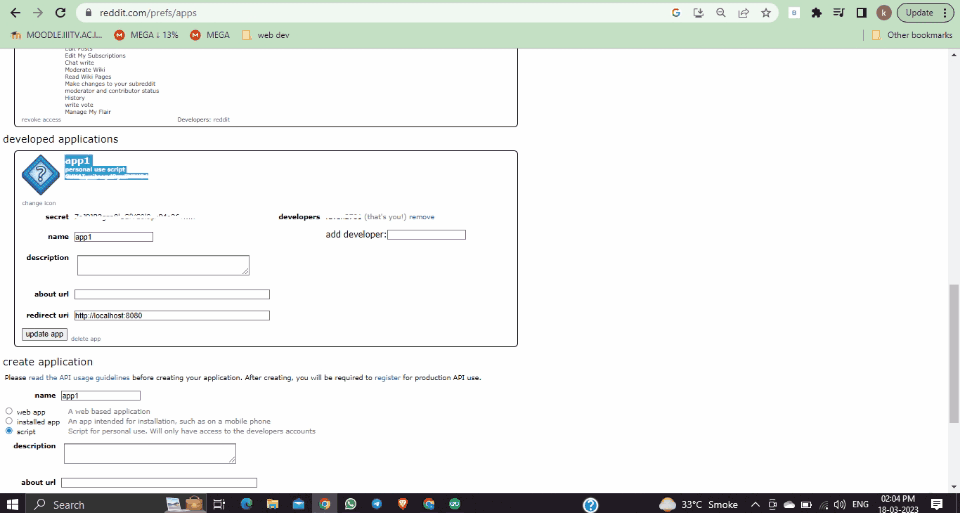
How to set up and use GoLogin for web scraping Reddit?
Step 1: Create an account
Making an account on GoLogin’s website is the first step in using the service. You can accomplish this by going to the GoLogin website and creating an account using your email address. You can log in to the platform and begin configuring your browser profiles after creating an account.
Step 2: Set up a browser profile
GoLogin employs a browser profile as a distinct identity to simulate actual user behaviour. Choose the browser you want to use, such as Google Chrome or Mozilla Firefox, before you can create a profile for it. The profile can then be altered by include user agents, fingerprints, and IP addresses. These features will assist in making the profile appear more authentic, lowering the chance of getting discovered.
Step 3: Configure the proxy settings
You can modify the proxy settings for your browser profile to further lower the chance of detection. By doing this, you can give every website you visit a distinct IP address, which makes it more challenging for them to monitor your online behavior.
Step 4: Start web scraping Reddit
You can begin web scraping after setting up your proxy settings and browser profile. You need to do this by writing a web scraping script in a computer language like Python. The script should access the website and extract the necessary data using the GoLogin-created browser profile.

Web Scraping Reddit – Step By Step (without GoLogin)
Importing Libraries
Pandas is a Python library that provides powerful tools for data usage and analysis. It is widely used in data science and web scraping for data cleaning and analysis. Pandas provides data structures like data frames and series for managing and operating large data sets.
PRAW (Python Reddit API Wrapper) is a Python library used to interact with the Reddit API. It allows developers to easily access Reddit’s data and automation features through Python code. After you install Praw, you can retrieve data from Reddit, submit content, and manage user accounts.
import pandas as pd import praw
When used together, Praw and Pandas allow developers to easily scrape data from Reddit and analyze it using powerful data operation and analysis tools. They are popular tools of choice for many data scientists, artificial intelligence and machine learning engineers.
Accessing Reddit API
The code starts a PRAW (Python Reddit API Wrapper) instance with the appropriate credentials to access the Reddit API.
user_agent = "Scraper 1.0 by /u/python_engineer" reddit = praw.Reddit ( client_id="******", client_secret="*****", user_agent=user_agent )
The Reddit API credentials are provided, which include a unique client ID and a client secret. These are used to authorize the application to access the Reddit API. Finally, the praw.Reddit() function is called with the user agent and credentials as arguments, creating a Reddit instance that allows Python code to interact with Reddit.
Scraping a Subreddit
This code retrieves the number of unique titles for the ‘hot’ posts on the subreddit ‘Investing’ using the API provided by Reddit.
headlines = set ( )
for submission in reddit.subreddit('Investing').hot(limit=None):
headlines.add(submission.title)
print(len(headlines))
The first line starts an empty set called headlines.
The second line iterates over all the ‘hot’ posts on the ‘Investing’ subreddit by calling the reddit.subreddit(‘Investing’).hot(limit=None) method. The limit=None parameter retrieves all the specific posts that are ‘hot’ and available on the subreddit.
In each iteration of the loop, the title of the current post is added to the headlines set using the add() method. Set stores only unique values, so if the same title appears more than once, it won’t be added to the set again.
Finally, the total number of unique headlines is printed using the print() statement and calling the len() method on headlines set. This counts the number of unique titles collected in the set.
To scrape different types of information use any of the following code lines:
print (submission.title) print (submission.id) print (submission.author) print (submission.score) print (submission.upvote_ratio) print (submission.url)
Saving the scraped data
Convert the scraped data into a data frame using Pandas.
df=pd.DataFrame(headlines)
Web Scraping Reddit Using Gologin
1. Install the GoLogin package using pip:
pip install gologin
2. Import the GoLogin module and set up a GoLogin profile:
import gologin
# Set up a GoLogin profile
gologin.set_profile(
name="my-profile",
browser_executable_path="/path/to/chrome.exe",
user_agent="my-user-agent",
proxy={
"server": "my-proxy-server",
"port": 1234,
"username": "my-username",
"password": "my-password"
}
)
3. Use the gologin.get_webdriver function to get a webdriver with your GoLogin profile:
from selenium.webdriver import Chrome
driver = gologin.get_webdriver("my-profile", Chrome)
4. Pass the webdriver to praw when creating a Reddit instance:
import praw reddit = praw.Reddit( client_id="****", client_secret="****", user_agent="Scraper 1.0 by /u/python_engineer", webdriver=driver )
5. Now you can use praw to scrape Reddit with your GoLogin profile:
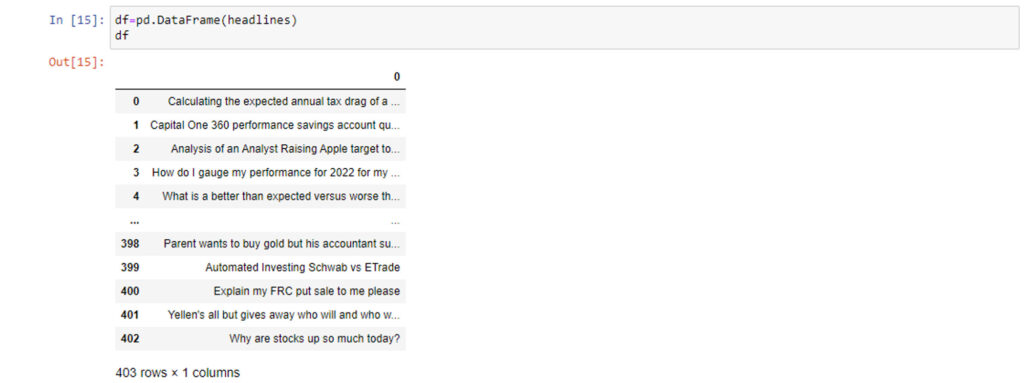 Scraped headlines
Scraped headlines
Tips And Best Practices For Web Scraping Reddit
- Respect website policies. Before scraping data from a website, make sure to review its terms of service and privacy policy. Some websites may prohibit web scraping or require permission before data can be scraped.
- Avoid overloading servers. Web scraping can put a strain on website servers, so it’s important to avoid scraping large amounts of data or making too many requests in a short period of time. Don’t just go to a page and click buttons 430 million times. Pace your work and consider using a delay between requests or scraping data during off-peak hours.
- Handle errors and exceptions. Web scraping can be prone to errors and exceptions, such as server errors, connection timeouts, and invalid data. Make sure to handle errors and exceptions gracefully, such as retrying failed requests or logging errors for later analysis.
- Use a user-agent string. A user-agent string is a piece of code that identifies the web scraper to the website. Using a user-agent string that is commonly used by web browsers can help avoid detection and prevent websites from blocking scraping activities.
- Use proxies. Proxies can be used to rotate IP addresses and avoid detection by websites that may attempt to block scraping activities. However, make sure to use reputable proxy providers and follow their terms of service.
- Observe ethical and legal standards. Web scraping can raise ethical and legal concerns, such as respecting the privacy of individuals whose data is being collected (for example, scraped comments) and complying with data protection laws. Make sure to scrape data only for legal and ethical purposes, and to obtain consent if necessary.
By following these tips and best practices, web scrapers can avoid getting blocked by websites, handle errors and exceptions, and maintain ethical and legal standards when scraping data.
Conclusion
Reddit web scrapers can be a powerful tool for various purposes such as market research, competitor analysis, and more. It requires proper planning and good tools to avoid getting blocked by websites and maintain ethical and legal standards.
Python is a popular programming language for web scraping due to its rich ecosystem of libraries and tools, such as Beautiful Soup, Scrapy, and Selenium. These libraries provide powerful capabilities for parsing HTML, automating web browsing, and extracting data from websites.
GoLogin is a great tool for managing multiple online identities and web scraping, providing a secure and private browsing environment, allowing multiple browser profiles and automating web scraping tasks, and supporting integration with proxy servers. This makes it a valuable tool for businesses and individuals who need to manage multiple online identities and gather data from the web.
Overall, using Python and GoLogin for web scraping can help organizations and individuals extract valuable insights and information from the web more efficiently and securely, while adhering to ethical and legal standards.
FAQ
Does Reddit allow web scraping?
Yes, Reddit does not explicitly prohibit web scraping, but it is important to follow their Terms of Service and guidelines. Ensure that your scraping activities are respectful, do not violate Reddit’s rules or policies, and avoid overloading their servers.
How do I scrape a subreddit?
To scrape a subreddit, you can use web scraping techniques with Python. Choose a web scraping library like BeautifulSoup or Scrapy.
Identify the URL of the subreddit you want to scrape and send an HTTP request to retrieve the HTML content. Parse the HTML using the library to extract the desired information.
How do I scrape data from Reddit using Python?
To scrape data from Reddit using Python, you can utilize the PRAW library, which is a Python wrapper for the Reddit API.
Set up a Reddit API application, install praw using pip install praw, authenticate your application with the API, and then fetch the desired data using praw. Remember to comply with Reddit’s API usage guidelines and Terms of Service.
Download GoLogin here and enjoy safe scraping with our free plan!
Read more from us on this topic: Scraping Data From LinkedIn: Pro Scraper’s Guide + Code
Reference:
- Norman Adams N. ‘Scraping’Reddit posts for academic research? Addressing some blurred lines of consent in growing internet-based research trend during the time of Covid-19 //International Journal of Social Research Methodology. – 2022. – С. 1-16.
- Zhao B. Web scraping //Encyclopedia of big data. – 2017. – Т. 1.
- Glez-Peña D. et al. Web scraping technologies in an API world //Briefings in bioinformatics. – 2014. – Т. 15. – №. 5. – С. 788-797.
- Wang J., Huang Y., Ghosh A. SafeFox: A safe lightweight virtual browsing environment //2010 43rd Hawaii International Conference on System Sciences. – IEEE, 2010. – С. 1-10.
- Sahu S. Design considerations for integrated proxy servers. – 1999.
- Baumgartner J. et al. The pushshift reddit dataset //Proceedings of the international AAAI conference on web and social media. – 2020. – Т. 14. – С. 830-839.
- Adams N. N. ‘Scraping’Reddit posts for academic research? Addressing some blurred lines of consent in growing internet-based research trend during the time of COVID-19 //International journal of social research methodology. – 2022.


