Se você gosta de web scraping com Python, está no lugar certo. Hoje, veremos como criar seu primeiro scraper com Python com o Scrapy, com alguns truques e dicas úteis. O site alvo será books.toscrape.com, um site criado especificamente para testar seus scrapers.

O que é Scrapy
Scrapy é um framework de aplicação de Python de código aberto projetado para criar programas de web scraping com Python.
Ele se tornou o padrão para web scraping em Python por sua capacidade de lidar com opções peculiares à web scraping, como a adesão ao arquivo robots.txt e a limitação das solicitações ou alterações em seu User Agent.
Algumas das principais características são:
- suporte para extração de dados com seletores XPATH ou CSS
- um console shell interativo para testar seu scraper em tempo real
- exportadores em formatos comuns, como CSV, JSON e outros
- um console telnet para fins de debugging
Instalação
Em uma das próximas publicações, veremos como criar um ambiente completo para web scraping com todo o software necessário para navegadores headful e headless.
Para os fins deste artigo, podemos usar o guia oficial do Scrapy para sua instalação.
Análise do Alvo
books.toscrape é um site simples criado para fins de web scraping e imita um site clássico de comércio eletrônico que vende livros, é claro.
Os dados que podemos extrair são os típicos que podemos encontrar em qualquer comércio eletrônico. Para esse teste, vamos extrair:
- Título
- URL da imagem do livro
- UPC (Código de Barras)
- Tipo do Produto
- Taxa Sem Imposto
- Taxa Com Imposto
- Disponibilidade
- Número de avaliações
- Descrição
Todas essas informações podem ser encontradas no HTML da página do produto, portanto, uma simples instalação do Scrapy deve ser suficiente.
Vamos começar então.
Criando o projeto Scrapy
Um projeto Scrapy é uma pasta que contém um conjunto de arquivos necessários para executar uma Scrapy spider.
Executando o seguinte comando em sua command line, esses arquivos serão criados.
scrapy startproject bookstoscrape
Uma pasta chamada bookstoscrape será criada com uma série de arquivos nela
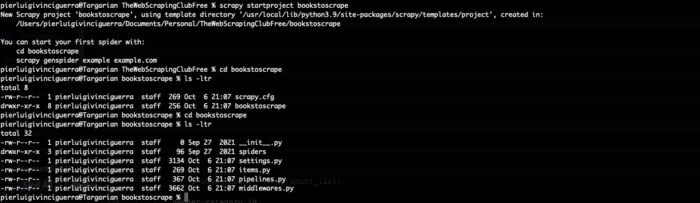
- scrapy.cfg: contendo as configurações gerais do projeto
- bookstoscrape: pasta contendo os seguintes arquivos:
- items.py: declararemos aqui a estrutura da saída que desejamos
- middlewares.py: onde podemos declarar o Downloader ou os Spider middlewares
- pipelines.py: onde podemos manipular os dados após um item ter sido extraído
- settings.py: o arquivo principal para lidar com a maior parte da configuração do scraper, como limitação, user agent e assim por diante
- spider folder: onde o Scrapy colocará nosso scraper
To have a better understanding of the purpose of the different files, you can have a look at neste artigo, where we summarized the Scrapy architecture, or, if you want to dig deeper, to the documentação oficial.
Para esse scraper básico, veremos em detalhes dois desses arquivos: items.py e settings.py
items.py
Nesse arquivo, declararemos os campos dos itens de saída que desejamos como saída e que já vimos na fase de estudo do alvo.
A classe terá a seguinte aparência:
import scrapy class BookstoscrapeItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() imageurl = scrapy.Field() upc = scrapy.Field() producttype = scrapy.Field() pricenotax = scrapy.Field() pricewithtax = scrapy.Field() availability = scrapy.Field() reviewsnum = scrapy.Field() description = scrapy.Field() pass
Basicamente, estamos declarando os metadados da saída do nosso scraper, mas não estamos impondo nenhuma regra sobre como esses campos devem ser preenchidos ou quais valores são aceitos ou não.
Em geral, como prática recomendada, não costumo adicionar nenhuma lógica ou declaração de tipo no nível do scraper, pois toda a limpeza e validação de dados são realizadas em um estágio posterior, normalmente em um banco de dados.
Se você precisar que a saída seja limpa ou validada, essas regras deverão ser aplicadas no arquivo pipelines.py.
settings.py
Esse é o arquivo principal onde se configura o coletor de dados e apenas algumas das centenas de opções disponíveis são mostradas quando ele é inicializado. Você pode encontrar a lista de todas as configurações padrão para web scraping com Python no repositório do Scrapy no GitHub, mas vamos dar uma olhada nas mais usadas.
Em primeiro lugar, temos o User Agent. Neste exemplo, vamos imitar um navegador Chrome instalado em um computador Mac que está fazendo o scraping do site alvo, de modo que ele ficará parecido com o seguinte:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
Em seguida, temos o indicador para permitir ou não a adesão ao arquivo robots.txt. Vamos mantê-lo definido como True e ver o que acontece.
ROBOTSTXT_OBEY = True
CONCURRENT_REQUESTS = 3 DOWNLOAD_DELAY = 1
Essas duas opções são a maneira comum de lidar com a limitação de seu scraper. CONCURRENT_REQUESTS define o número de threads que fazem requisições ao servidor alvo, enquanto DOWNLOAD_DELAY define o intervalo fixo em segundos entre duas requisições do mesmo thread.
Se você precisar de uma pausa variável entre as requisições, em vez de usar essas opções, podemos ativar o AUTOTHROTTLE.
AUTOTHROTTLE_ENABLED = True # The initial download delay AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server AUTOTHROTTLE_TARGET_CONCURRENCY = 3.0 # Enable showing throttling stats for every response received: AUTOTHROTTLE_DEBUG = False
Nesse caso, o intervalo variará, dependendo da latência do site alvo.
Da documentação do Scrapy:
O algoritmo AutoThrottle ajusta os intervalos de download com base nas seguintes regras:
1. spiders sempre começam com um intervalo de download de AUTOTHROTTLE_START_DELAY;
2. quando uma resposta é recebida, o intervalo de download desejado é calculado como latency / N onde latency é a latência da resposta, e N é AUTOTHROTTLE_TARGET_CONCURRENCY.
3. o intervalo de download para as próximas requisições é definido como a média do intervalo de download anterior e o intervalo de download desejado;
4. latências de respostas diferentes de 200 não são permitidas para diminuir o intervalo;
5. o intervalo do download não pode ser menor que DOWNLOAD_DELAY ou maior que AUTOTHROTTLE_MAX_DELAY
Por último, mas não menos importante, configuraremos os cabeçalhos de solicitação padrão, copiando-os da aba inspecionar do navegador.
DEFAULT_REQUEST_HEADERS = {
':authority': 'books.toscrape.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'dnt': '1',
'sec-ch-ua': '"Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
A menos que especificado de forma diferente dentro do scraper, esses cabeçalhos serão usados para todas as requisições dentro do scraper. Novamente, estou imitando aqui uma solicitação feita por um computador Mac com o navegador Chrome instalado.
Você deve ter notado que não copiei a opção “accept encoding” (aceitar codificação), porque o Scrapy lida com ela automaticamente e adicioná-la aos cabeçalhos pode causar alguns problemas com o formato de saída quando compactado.
Criando o Spider
Após executar o comando a seguir, obteremos um esqueleto inicial de um scraper.
scrapy genspider booksscraper toscrape.com
Estamos criando um scraper chamado booksscraper, que será configurado para fazer o scraping do site toscrape.com e mover-se somente dentro do domínio toscrape.com.
import scrapy class BooksscraperSpider(scrapy.Spider): name = 'booksscraper' allowed_domains = ['toscrape.com'] start_urls = ['http://toscrape.com/'] def parse(self, response): pass
Com essa configuração, o coletor de dados começa com a lista de URLs dentro da variável start_urls e, em seguida, executa a função de parse.
A outra maneira de iniciar um Scrapy spider é a seguinte:
import scrapy from scrapy.http import Request class BooksscraperSpider(scrapy.Spider): name = 'booksscraper' allowed_domains = ['toscrape.com'] def start_requests(self): start_urls = ['http://books.toscrape.com/'] for url in start_urls: yield Request(url, callback=self.parse) def parse(self, response): pass
Em vez de iniciar a partir da lista start_urls, o scraper inicia a partir da função start_request e temos mais opções para diferenciar as chamadas para cada URL nas URLs iniciais, como, por exemplo, poderíamos atribuir um cookie jar diferente a cada URL.
Requisição dos Itens
Agora estamos na página inicial do site e temos duas tarefas diferentes:
- iterar em todos os livros da página, extraindo para cada livro a URL da página
- iterar em cada página até a página 50, o número máximo.
Para ambos os casos, usarei seletores XPath, pois os considero mais legíveis e mais completos, mesmo que, pelo que li on-line, eles tenham menos desempenho do que os seletores CSS.
Não entraremos em detalhes sobre o funcionamento dos seletores XPath ou CSS neste tutorial, mas certamente faremos isso em um dos próximos artigos.
Vamos começar extraindo os dados dos livros na primeira página do site.
Excluindo o URL da imagem e a descrição, todos os outros dados estão em uma tabela sem um ID específico, portanto, precisaremos usar o text label de cada linha da tabela para extrair o valor correspondente.
O resultado é o que você pode ver na imagem abaixo (estou anexando a imagem do código por motivos de formatação e legibilidade agora).
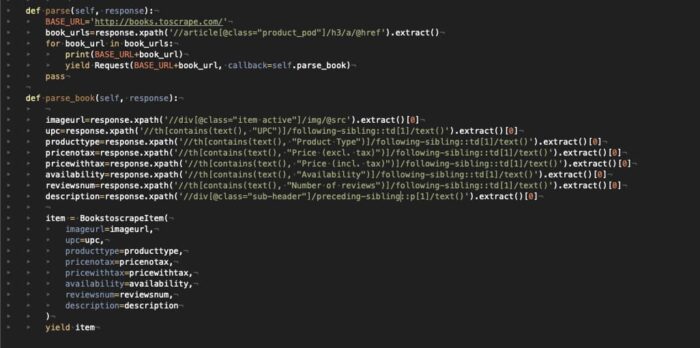
Para cada livro extraído, criaremos um BooktoscrapeItem, em que cada campo é preenchido pelo resultado de nossos seletores XPATH e a função parse_book retorna esse item como resultado.
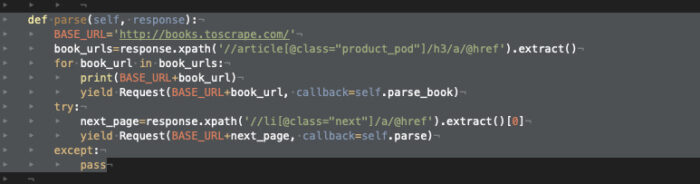
A segunda etapa do coletor de dados, que itera nas páginas do catálogo, é tratada simplesmente encontrando a tag do link “next page” e, em seguida, chamando novamente a função de parse nessa nova página.
Agora podemos finalmente chamar nosso scraper com o comando
scrapy crawl booksscraper -o test.json -t json
e obteremos um arquivo test.json dentro do diretório do projeto, contendo um JSON com os itens extraídos. Usei o JSON como formato de saída, mas existem diferentes opções. Dê uma olhada na documentação para ver o que é melhor para você.
P.S.: você verá que, ao executar o scraper, haverá diversos erros 404, pois as URLs das páginas seguintes e dos livros não são consistentes, mas isso não importa para o propósito deste pequeno tutorial.
Espero que você tenha achado útil este pequeno tutorial sobre web scraping com Python. Leia mais neste link – Código do repositório do GitHub e, em caso de dúvidas, entre em contato com a comunidade em nosso servidor no Discord ou entre em contato comigo pelo e-mail [email protected]
Este artigo foi gentilmente cedido por Pierluigi Vinciguerra, especialista em web scraping e fundador do Web Scraping Club. Acesse este link para ver a publicação original.
Faça o download do GoLogin aqui e explore o universo do scraping com nosso plano gratuito!


