

Vamos Esclarecer Primeiro: É Legal?
Obter dados do LinkedIn através de scraping – está dentro da lei ou não?
O LinkedIn é uma plataforma de rede social voltada para negócios que se tornou um recurso vital para conectar-se com outros profissionais e desenvolver redes profissionais. Devido à enorme quantidade de dados disponíveis no LinkedIn, algumas pessoas ou empresas têm interesse em obter informações do site para seus próprios usos.
Portanto, naturalmente, como uma empresa, o LinkedIn aplica certas regras para proteger os dados de seus usuários – tanto dados de domínio público quanto dados pessoais ocultos. As suas regras proíbem o uso de métodos automatizados para recolha de dados da sua plataforma, incluindo scraping, crawling, mineração de dados (Data Mining), entre outros.
O LinkedIn utiliza uma série de proteções técnicas, incluindo restrições de taxa de acesso, CAPTCHAs e bloqueio de IP, para limitar o acesso ilegal à sua plataforma e a “raspagem” (scraping) automatizada de dados. Essas medidas têm o objetivo de garantir que apenas usuários autorizados tenham acesso à plataforma e aos seus dados.
Domínio Público
Aqui está o que importa: as políticas corporativas do LinkedIn não tornam o scraping de dados do LinkedIn antiética, ilegal ou perigosa – desde que você esteja “raspando” dados de domínio público. As leis da União Europeia e dos Estados Unidos não proíbem de forma alguma o scraping de dados de domínio público, mesmo que a política da empresa local seja contra isso.
Embora o Supremo Tribunal dos Estados Unidos recentemente tenha invalidado leis que tornavam ilegal pesquisar bases de dados online em busca de informações, ele não abordou a questão do scraping. Isso significa que continua perfeitamente legal aceder ao LinkedIn e obter todas as informações disponíveis sobre alguém. Recomendamos sempre trabalhar dentro dos limites da lei.
Portanto, lembre-se: o que você “raspa” deve ser sempre de acesso livre para todos.

Utilizando o Selenium para Obter Dados do LinkedIn
Existem várias tecnologias que podem ser usadas para realizar o scraping de dados em websites, sendo o Selenium uma ferramenta de automação bastante popular.
A capacidade de interagir com páginas web, modelar o comportamento do utilizador e automatizar operações são apenas algumas das características que tornam o Selenium uma ferramenta eficaz para raspagem de dados na web.
Configurar o Selenium no seu Computador
Para utilizar o Selenium com Python, é necessário ter o Python instalado no seu computador. Pode baixar o Python no site oficial do Python.
Depois de instalar o Python, será necessário instalar o pacote do Selenium executando o comando *pip install selenium* num prompt de comando ou numa janela de terminal.
Importar o Driver
O Selenium requer um driver específico para interagir com as páginas web. Pode baixar o driver correspondente ao seu navegador preferido no site oficial do Selenium.
Após baixar o driver, será necessário especificar no seu código, o local onde o driver se encontra, adicionando algumas linhas de código no início do seu script.
from selenium import webdriver driver = webdriver.Chrome('/path/to/chromedriver')
Com o seu web driver configurado, está pronto para começar a escrever o código de Scraping da web. Quando terminar, certifique-se de fechar o web driver, adicionando uma linha de código no final do seu script para libertar recursos do sistema.
driver.quit()
Exemplo
Aqui está um exemplo de uso do Selenium para Scraping da web, para obter dados de uma tabela numa página web. Aqui está um exemplo em Python de como fazer isso:
from selenium import webdriver driver = webdriver.Chrome() driver.get('https://example.com/table') # Find the table element table = driver.find_element_by_css_selector('table') # Get the column headers headers = [header.text for header in table.find_elements_by_css_selector('theader')] # Get the data rows rows = [] for row in table.find_elements_by_css_selector('trow'): rows.append([cell.text for cell in row.find_elements_by_css_selector('tdata')]) driver.quit() print(headers) print(rows)
Neste exemplo, começamos por encontrar a página web com a tabela que desejamos “raspar”. Em seguida, localizamos o elemento da tabela e obtemos as linhas de dados e os cabeçalhos das colunas usando o Selenium. Os itens “theader” da tabela são todos localizados e o seu texto é extraído para obter os cabeçalhos das colunas.
Ao localizar cada elemento “trow” na tabela e obter o texto de cada um de seus elementos filhos “tdata”, obtemos as linhas de dados. O web driver é então encerrado e as linhas de dados e os cabeçalhos das colunas são impressos.

Fazendo o Scraping de Dados do LinkedIn com Python
Para começar, importamos as bibliotecas necessárias, como o pandas e o Selenium. Em seguida, utilizamos a biblioteca Selenium para o scraping de dados do LinkedIn. Os módulos da biblioteca Selenium usados neste código são os seguintes: Webdriver, expected conditions, options, Keys e sleep do módulo time.
É importante observar que o web scraping requer um web driver. Neste exemplo, usaremos o navegador Chrome e o driver do Chrome é baixado da internet.
import pandas as pd import time import random import requests from time import sleep from bs4 import BeautifulSoup from parsel import Selector from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys opts = Options() import csv
driver = webdriver.Chrome(options=opts, executable_path= "chromedriver")
O código começa com uma função chamada def validate_field. Aqui, validamos o campo para verificar se ele existe na página. Se o campo estiver presente, preenchemos os dados no campo.
# function to ensure all key data fields have a value def validate_field(field): # if field is present pass if field: if field: pass # if field is not present print text else: else: field = 'No results' return field
Em seguida, usamos o método driver.get para navegar até o site oficial do LinkedIn, seguido pelo método driver.find_element para localizar os campos de email e senha.
Para extrair a tag e a classe de uma unidade específica, usamos o ID do container, conhecido como “session key”. Isso ajuda-nos a identificar corretamente e extrair os dados desejados, permitindo adicionar as informações necessárias ao parágrafo.
Para recuperar os dados necessários, usamos driver.find_element_by_id e especificamos o ID para ambos os containers. O ID para o primeiro container é “session key” e, para o segundo container, é “session password”.
Fazendo isso, identificamos e recuperamos corretamente as informações relevantes de ambos os containers, permitindo executar a ação necessária nos dados de cada container.
# driver.get method() will navigate to a page given by the URL address driver.get('https://www.linkedin.com') #locate email form by_class_name username = driver.find_element(By.ID, "session_key") # send keys(0) to simulate keystrokes username.send_keys ("*****@gmail.com") # sleep for 0.5 seconds sleep(0.5) # locate password form by_class_name password = driver.find_element(By.ID,'session_password') # send keys() to simulate key strokes password.send_keys('*******') sleep(0.5) # locate submit button by xpath sign_in_button = driver.find_element(By.XPATH,'//* [@type="submit"]') # . click() to mimic button click sign_in_button.click() sleep(10)
Após fazer o login com sucesso no LinkedIn, precisamos encontrar os links dos utilizadores específicos de um campo específico. Por exemplo, suponhamos que queremos encontrar programadores Python.
Nesse caso, podemos pesquisar no Google e obteremos alguns resultados do LinkedIn. No entanto, queremos apenas os links dos utilizadores, por isso precisamos extrai-los.
# Task 2: Search for the profile we want to crawl # Task 2.1: Locate the search bar element search_field = driver.find_element(By.XPATH, '//*[@id="global-nav-typeahead"]/input') # Task 2.2: Input the search query to the search bar # search_query = input('What profile do you want to scrape? ') search_field.send_keys('Python Developers') # Task 2.3: Search search_field.send_keys(Keys.RETURN) # locate Peoples button by xpath people = driver.find_element(By.XPATH,'//*[@id="search-reusables__filters-bar"]/ul/li[1]/button') # . click() to mimic button click people.click() sleep(2)
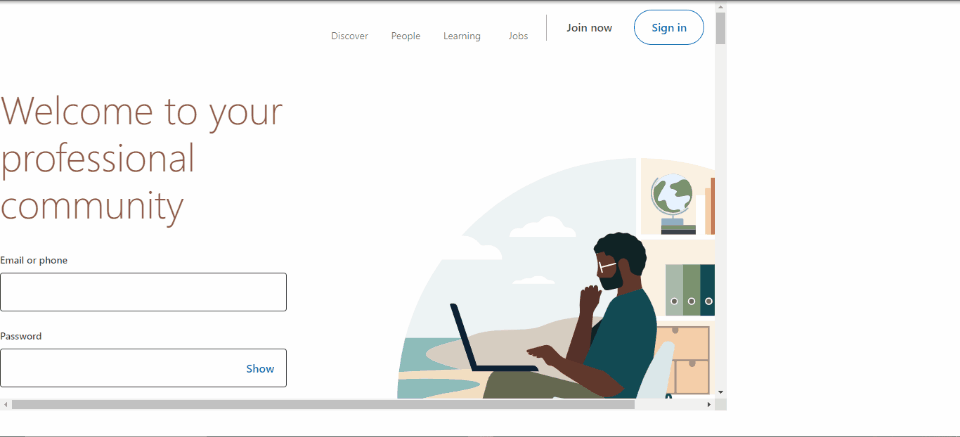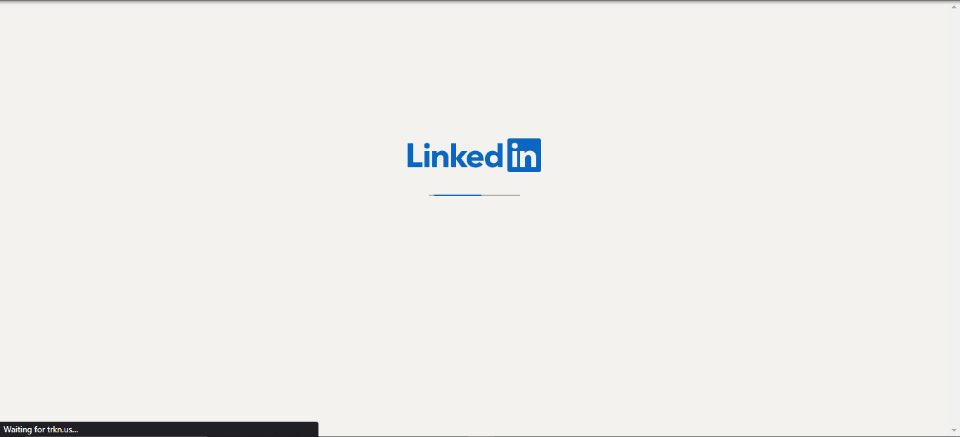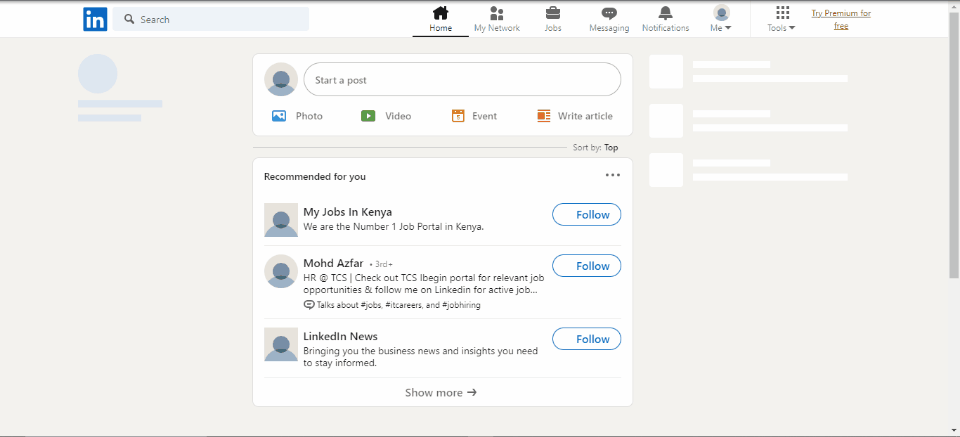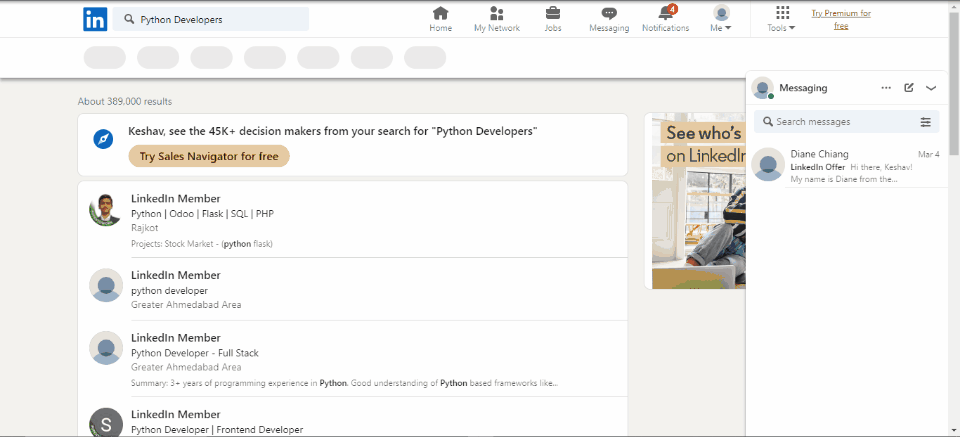
Para isso, usamos um link específico que nos dará apenas os programadores Python de um local específico.
Uma vez que navegamos para este link, usamos o driver.get para ir a cada página com um determinado intervalo de tempo e ir buscar os links de cada página.
# Task 3: Scrape the URLs of the profiles profiles = driver.find_elements(By.CLASS_NAME, 'app-aware-link') all_profile_URL = [] for profile in profiles: profile_ID = profile.get_attribute('href') profile_URL = "https://www.linkedin.com" + profile_ID if profile_URL not in all_profile_URL: all_profile_URL.append(profile_URL) print('- Finish Task 3: Scrape the URLs')
O Resultado
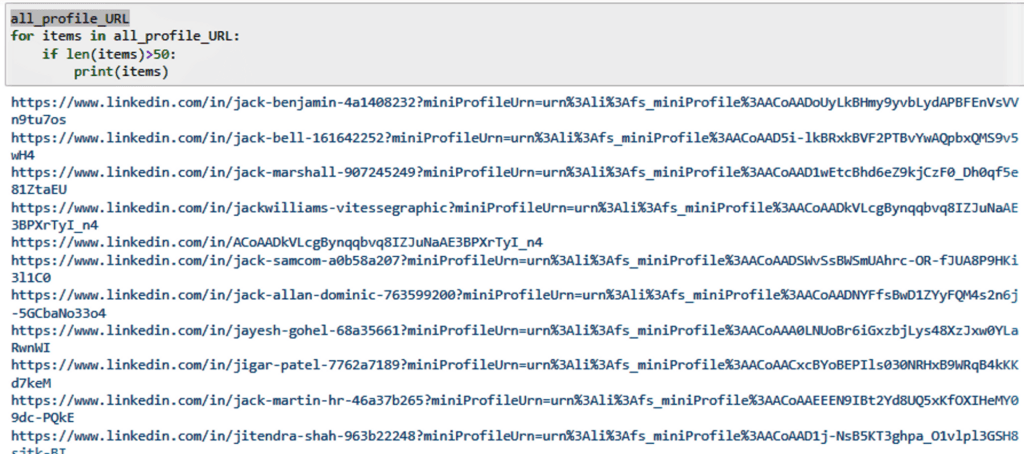
Agora, extraia os dados necessários dos links dos perfis “raspados”
Para extrair os links, usamos o método element.get_attribute(“href”) para obter o atributo href. Uma vez que temos o link, podemos navegar para a página de cada utilizador e obter os dados necessários.
Em conclusão, o web scraping pode ser uma maneira eficaz de recolher dados do LinkedIn. O Selenium e o Python fornecem uma combinação poderosa de ferramentas para web scraping, permitindo que os utilizadores obtenham dados valiosos da plataforma.
Utilizando o GoLogin para um Trabalho Seguro
Uma plataforma de automação online chamada GoLogin oferece aos desenvolvedores de sites uma técnica para evitar deteção, imitando a atividade de um utilizador real. É desafiador para os websites identificar o acesso automatizado devido à capacidade do GoLogin de gerar e gerenciar vários perfis de navegador com identidades distintas, como agentes de utilizador, impressões digitais e endereços IP.
Esta plataforma possui uma interface de utilizador intuitiva, funciona com uma grande variedade de navegadores e dispositivos, e possui tecnologia avançada de impressão digital que pode ajudar os desenvolvedores a evitar bloqueios de IP e dificuldades com CAPTCHA.
Com a tecnologia de impressão digital avançada do GoLogin, os desenvolvedores podem simular a impressão digital de um utilizador real. Essa tecnologia garante que tarefas automatizadas na web não disparem nenhum alarme, tornando praticamente impossível para os websites detetarem o acesso automatizado.
A plataforma também oferece integração de proxy, gestão de sessão e suporte a API, os quais podem acelerar e automatizar o processo de desenvolvimento.

Como configurar e usar o GoLogin para fazer scraping da web?
Passo 1: Criar uma conta
Criar uma conta no website do GoLogin é o primeiro passo para utilizar o serviço. Pode fazê-lo acedendo o website do GoLogin e criando uma conta utilizando o seu endereço de email.
Após criar uma conta, você pode fazer login na plataforma e começar a configurar os perfis de navegador.
Passo 2: Configurar um perfil de navegador
O GoLogin utiliza um perfil de navegador como uma identidade distinta para simular o comportamento de um utilizador real. Escolha o navegador que deseja utilizar, como o Google Chrome ou o Mozilla Firefox, antes de criar um perfil para ele.
O perfil pode ser alterado para incluir agentes de utilizador, impressões digitais e endereços IP, o que ajudará a tornar o perfil mais autêntico e reduzir as hipóteses de deteção.
Passo 3: Configurar as definições de proxy
Pode modificar as definições de proxy para o perfil de navegador, reduzindo ainda mais as hipóteses de deteção.
Ao fazer isso, pode atribuir a cada website que visita um endereço IP distinto, o que torna mais desafiador para eles monitorarem o seu comportamento online.
Passo 4: Iniciar o web scraping
Após configurar as definições de proxy e o perfil de navegador, pode começar a realizar o web scraping. Precisará escrever um script de scraping em uma linguagem como Python.
O script deve aceder o website e extrair os dados necessários utilizando o perfil de navegador criado pelo GoLogin.
- Importando as bibliotecas necessárias:
A primeira modificação foi a importação das bibliotecas necessárias, incluindo sys, selenium, chrome_options, time e gologin. Isso foi feito adicionando as seguintes linhas de código no início do arquivo:
from sys import platform from selenium import webdriver from selenium.webdriver.chrome.options import Options from gologin import GoLogin
- Configuração do GoLogin e Selenium WebDriver:
A segunda modificação foi a configuração do GoLogin e Selenium WebDriver. Isso foi feito adicionando as seguintes linhas de código no início do arquivo:
gl = GoLogin({
'token': 'yU0token',
'profile_id': 'yU0Pr0f1leiD',
})
if platform == "linux" or platform == "linux2":
chrome_driver_path = './chromedriver'
elif platform == "darwin":
chrome_driver_path = './mac/chromedriver'
elif platform == "win32":
chrome_driver_path = 'chromedriver.exe'
debugger_address = gl.start()
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", debugger_address)
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
Este código configura o GoLogin com o token e profile_id corretos, bem como o caminho correto do WebDriver para a plataforma. Em seguida, ele inicia o GoLogin e configura o WebDriver com o endereço correto do depurador.
- Atualizando o código para usar o WebDriver:
A última modificação foi atualizar o código para usar o WebDriver para navegação e scraping. Isso foi feito atualizando o código para usar o objeto driver em vez da biblioteca requests para navegação e usar driver.page_source em vez de response.content para o scraping.
Passo 5: Monitorize a sua atividade
Para garantir que os websites não sejam alertados sobre as suas atividades de web scraping, é crucial ficar de olho nelas.
O GoLogin oferece uma variedade de recursos para facilitar o acompanhamento das suas atividades, incluindo gestão de sessões, compatibilidade com API e um painel que exibe o seu endereço IP e perfil de navegador atual.

Para o LinkedIn
Para realizar o scraping de dados do LinkedIn utilizando o serviço do GoLogin, é necessário primeiro criar um perfil na plataforma do GoLogin. Isso pode ser feito criando um novo utilizador, escolhendo uma configuração de navegador específica e adicionando quaisquer plugins ou extensões necessárias.
O utilizador pode visitar o website do LinkedIn e fazer login utilizando as suas credenciais após criar o perfil de utilizador. Em seguida, eles podem simular ações humanas, como o scrolling da página, o clique em links e inserção de dados, utilizando as ferramentas de automação do GoLogin.
Por exemplo, um utilizador pode usar o GoLogin para procurar utilizadores que tenham o cargo de ” software engineer” e que estejam localizados numa cidade específica. Eles podem então utilizar as ferramentas de automação para extrair dados como o nome do utilizador, cargo, empresa e localização.
O resultado final terá a seguinte aparência:

Utilizar vários perfis para aceder ao LinkedIn pode ajudar os utilizadores a escapar à deteção e reduzir o risco de serem banidos, o que é um dos benefícios potenciais de utilizar o GoLogin para o scraping do LinkedIn.
No entanto, é importante lembrar que isso pode violar os termos de serviço da plataforma e realizar scraping de dados do LinkedIn sem autorização pode resultar em problemas legais.
Portanto, é crucial agir com cautela e garantir que quaisquer ações de scraping sejam realizadas de forma moral e legalmente responsável.
Dicas para o Scraping de Dados do LinkedIn de forma Segura
O scraping de dados do LinkedIn pode fornecer informações valiosas para empresas e pesquisadores, mas é importante fazê-lo de forma ética e sem violar os termos de serviço do LinkedIn.
Para evitar ser banido, os desenvolvedores web devem seguir algumas dicas profissionais.
- Limite a frequência das solicitações aos servidores do LinkedIn e defina intervalos de tempo apropriados entre cada solicitação.
- Tráfego excessivo nos servidores do LinkedIn pode acionar seus sistemas de segurança e resultar em banimento. Além disso, os desenvolvedores não devem usar bots ou ferramentas automatizadas para o scraping de dados do LinkedIn, pois isso viola os termos de serviço da plataforma.
- Simule o comportamento humano ao fazer o scraping de dados do LinkedIn. Isso pode ser alcançado usando um navegador da web comumente usado por humanos e fazendo solicitações num ritmo realista.
- Evite aceder perfis privados ou dados que não estão disponíveis ao público.
- Respeite a privacidade dos utilizadores do LinkedIn e não utilize os seus dados para fins antiéticos. Seguindo essas melhores práticas, os desenvolvedores web podem fazer scraping de dados do LinkedIn com sucesso sem serem banidos e de maneira ética.
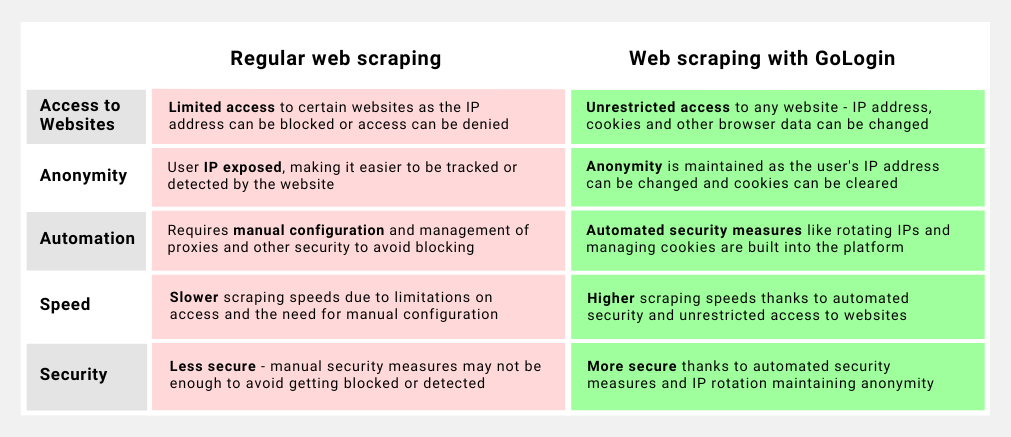 Dica profissional extra: usar uma ferramenta como o GoLogin pode ajudar os desenvolvedores web a fazer scraping de dados do LinkedIn sem serem banidos.
Dica profissional extra: usar uma ferramenta como o GoLogin pode ajudar os desenvolvedores web a fazer scraping de dados do LinkedIn sem serem banidos.
O GoLogin oferece uma maneira de criar e gerenciar vários perfis de navegador, o que pode ser útil para evitar a deteção pelo LinkedIn. Ao alternar entre diferentes perfis de navegador, torna-se mais difícil para o LinkedIn detetar padrões de atividade de scraping, o que ajuda a prevenir riscos.
Além disso, o GoLogin permite a rotação de IP, o que pode proteger ainda mais o seu trabalho ao fazer o scraping de dados do LinkedIn. Em geral, o uso do GoLogin pode ser uma ferramenta valiosa para os desenvolvedores web que desejam fazer scraping de dados do LinkedIn com segurança e sem riscos.
Faça o download do GoLogin aqui e aproveite o scraping de segura com o nosso plano gratuito!


