Python é uma das linguagens mais conhecidas para webscraping devido à sua simplicidade, versatilidade e abundância de bibliotecas projetadas especificamente para essa finalidade. Com o Python, você pode criar facilmente web scrapers capazes de navegar por sites, extrair dados e armazená-los em diferentes formatos.
É especialmente útil para cientistas de dados, pesquisadores, profissionais de marketing e analistas de negócios, e é uma ferramenta valiosa que você deve adicionar ao seu conjunto de habilidades.
Neste artigo, você verá sobre web scraping o que é. Também mostraremos exatamente como realizar web scraping Python, analisaremos algumas ferramentas e bibliotecas populares e discutiremos algumas dicas e técnicas práticas.
Vamos nos aprofundar!

Visão Geral de O Que é Web Scraping e Como Funciona
Webscrapping refere-se à pesquisa e à extração de dados de sites usando programas de computador.
 O processo de web scraping envolve o envio de uma requisição a um site e a análise do código HTML para extrair os dados relevantes. Em seguida, esses dados são limpos e estruturados em um formato que pode ser facilmente analisado e usado para diversas finalidades.
O processo de web scraping envolve o envio de uma requisição a um site e a análise do código HTML para extrair os dados relevantes. Em seguida, esses dados são limpos e estruturados em um formato que pode ser facilmente analisado e usado para diversas finalidades.
O web scraping tem inúmeros benefícios, como:
- Economia de tempo e esforço na coleta manual de dados
- Obtenção de dados que não são facilmente acessíveis por meios tradicionais
- Obter insights valiosos sobre tendências e padrões em seu segmento.
Isso não lhe parece muito útil?
Tipos de Dados que Podem Ser Extraídos de Sites Usando Data Scraping
Você deve estar se perguntando: data scraping se limita apenas a informações textuais?
A resposta é não.
O data scraping pode extrair imagens, vídeos e dados estruturados, como tabelas e listas.
Os dados de texto podem incluir descrições de produtos, avaliações de clientes e publicações em mídias sociais.
Imagens e vídeos coletados por meio de data scraping podem ser usados para coletar dados visuais, como imagens de produtos ou vídeos de eventos. Informações como preços de produtos, disponibilidade de estoque ou informações de contato de funcionários podem ser extraídas de tabelas e listas.
Além disso, o web scraping pode extrair dados de diversas fontes para criar um banco de dados abrangente.
Esses dados podem então ser analisados com o uso de diversas ferramentas e técnicas, como visualização de dados e algoritmos de machine learning, para identificar padrões, tendências e insights.
Agora, é hora de aprender a fazer web scraping para que você mesmo possa fazer todas essas coisas legais. 😉
Visão Geral das Ferramentas e Bibliotecas Disponíveis para Web Scraping
Primeiro, vamos examinar as ferramentas e bibliotecas disponíveis que podem ajudar a simplificar o processo e tornar o web scraping mais eficiente e eficaz.
Beautiful Soup
 Com o Beautiful Soup, você pode navegar facilmente pelo código do site para encontrar os dados HTML e XML necessários e extraí-los em um formato estruturado para análise posterior.
Com o Beautiful Soup, você pode navegar facilmente pelo código do site para encontrar os dados HTML e XML necessários e extraí-los em um formato estruturado para análise posterior.
Scrapy
É uma estrutura Python que oferece uma solução completa de web scraping. O Scrapy permite que você vasculhe e extraia sites facilmente, incluindo recursos como extração automatizada de dados, processamento e armazenamento em diferentes formatos.
Selenium
O Selenium é uma ferramenta de código aberto que automatiza os navegadores da Web, permitindo simular o comportamento do usuário e extrair dados de sites que seriam difíceis ou impossíveis de acessar usando outras ferramentas.
A flexibilidade e a versatilidade do Selenium fazem dele uma ferramenta eficaz e poderosa para a extração de páginas dinâmicas.
Octoparse
É uma ferramenta visual de web scraping que permite a extração e a automação de dados com facilidade de apontar e clicar em diferentes formatos, incluindo CSV, Excel e JSON.
ParseHub
É uma ferramenta de web scraping que oferece uma solução baseada na Web e em desktop para extrair dados de sites.
Com o ParseHub, você pode criar facilmente projetos de scraping selecionando os dados que deseja extrair usando uma interface de apontar e clicar.
LXML

O LXML é uma ferramenta avançada e eficiente que pode lidar com documentos HTML e XML. Ele pode navegar facilmente em estruturas complexas de sites para extrair elementos específicos, como tabelas, imagens ou links, ou você pode criar filtros personalizados para extrair dados com base em critérios mais complexos.
Na próxima seção, mostraremos como configurar seu ambiente de desenvolvimento para web scraping.
Vamos nos aprofundar na parte divertida!
Como Configurar um Ambiente de Desenvolvimento para Web Scraping com Python
A configuração de um ambiente de desenvolvimento para web scraping com Python envolve a instalação do software e das bibliotecas necessárias e a configuração de seu ambiente de trabalho para extração eficiente de dados.
Veja como você pode fazer isso:
Passo 1. Instalar o Python
A primeira etapa é instalar o Python em seu computador, caso ainda não o tenha. Você pode baixar a versão mais recente do Python no site oficial e seguir as instruções de instalação.
Passo 2. Instalar um editor de texto ou um ambiente de desenvolvimento integrado (IDE)
Você precisará de um editor de texto ou de um IDE para escrever código Python. Algumas opções populares incluem o Visual Studio Code, o PyCharm e o Sublime Text.

Passo 3. Instalar as bibliotecas necessárias
Diversas bibliotecas Python, incluindo Beautiful Soup, Scrapy e Selenium, são comumente usadas para web scraping com Python. Você pode instalar essas bibliotecas usando o pip, o gerenciador de pacotes Python.
Abra o prompt de comando ou o terminal e digite:
pip install [library name]
Para instalar o Beautiful Soup, execute o seguinte comando:
pip3 install beautifulsoup4
Observação: talvez seja necessário prefixar o comando de instalação com sudo se você estiver no Linux ou no macOS.
Passo 4. Instalar um driver de Web
Se você planeja usar o Selenium para web scraping, deve instalar um driver de Web correspondente ao seu navegador preferido (por exemplo, Chrome, Firefox ou Safari).
Você pode baixar o driver de Web apropriado no site oficial do Selenium e adicioná-lo ao PATH do seu sistema.
 (Opcional) Passo 5. Criar um Ambiente Virtual
(Opcional) Passo 5. Criar um Ambiente Virtual
Um ambiente virtual é recomendado para manter seu ambiente Python organizado e evitar conflitos de dependência.
Você pode criar um ambiente virtual usando o módulo “venv” com o Python.
É isso. Você tem toda a configuração para começar a fazer web scraping com Python imediatamente. É hora de começar a programar!
Como Enviar Requisições HTTP a um Site e Tratar Respostas Usando Python
A biblioteca requests é uma biblioteca popular de terceiros que fornece uma interface fácil de usar para enviar requisições HTTP/1.1 no Python.
Aqui estão os passos a seguir:
Passo 1: Instalar a biblioteca de Requisições
Antes de poder usar a biblioteca requests, você precisa instalá-la. Você pode instalá-la usando pip, executando o seguinte comando:
pip install requests
Como alternativa, você também pode usar o seguinte comando para ambientes virtuais:
pipenv install requests
Passo 2: Importar o Módulo Requests
Depois que a biblioteca de solicitações estiver instalada, você poderá importá-la para o seu script Python usando o seguinte comando:
import requests
Passo 3: Enviar uma Requisição HTTP
Para enviar uma requisição HTTP, você pode usar os métodos get(), post(), put() e delete() da biblioteca requests.
Por exemplo, para enviar uma requisição GET a um site, você pode usar o seguinte código:
response = requests.get('https://www.example.com')
Isso enviará uma requisição GET para https://www.example.com e armazenará a resposta na variável response.
Caso você ainda não saiba, veja o que significam as requisições GET, POST, PUT e DELETE:
- GET: Usado para solicitar dados. Eles são armazenados no histórico do navegador e não devem ser usados para coisas confidenciais.
- POST: Usado para enviar dados a um servidor. Não são armazenados no histórico do navegador.
- PUT: Também usado para enviar dados a um servidor. A única diferença é que o envio repetido de uma solicitação POST criará dados múltiplas vezes, o que não acontece com o PUT.
- DELETE: Exclui os dados especificados.
Passo 4: Tratando da Resposta
A resposta do site pode ser acessada por meio do objeto response.
Você pode obter o conteúdo da resposta, o código de status, os cabeçalhos e outros detalhes. Veja a seguir um exemplo de como obter o conteúdo da resposta:
content = response.content
Isso obterá o conteúdo da resposta como uma cadeia de bytes. Se você quiser obter o conteúdo como uma cadeia de caracteres, use o seguinte código:
content = response.text
Para obter o código de status da resposta, você pode usar o seguinte código:
status_code = response.status_code
Isso retornará o código de status como um número inteiro. Veja como você pode obter os cabeçalhos da resposta:
headers = response.headers
Essa é uma breve visão geral do envio de requisições HTTP a um site e do tratamento de respostas usando a biblioteca requests do Python. Isso pode parecer muito complicado, mas quando você pega o jeito, fica fácil.
Introdução ao parsing de HTML usando o Beautiful Soup e à extração de dados de tags HTML
Beautiful Soup é uma biblioteca Python popular usada para extrair quaisquer dados de arquivos HTML e XML. Primeiro, ela cria uma árvore de análise para páginas analisadas e, em seguida, usa essas páginas para extrair dados de tags HTML.
Esta é uma introdução ao parsing de HTML usando o Beautiful Soup e à extração de dados de tags HTML:
Passo 1: Instalando o Beautiful Soup
Antes de podermos usar o Beautiful Soup no Python, precisamos instalá-lo. O Beautiful Soup pode ser instalado usando o comando shell “pip”:
pip install beautifulsoup4
Passo 2: Importando o Beautiful Soup
Depois de instalar o Beautiful Soup, podemos importá-lo para o nosso script Python usando o seguinte código:
from bs4 import BeautifulSoup
Passo 3: Parsing no Conteúdo HTML
A próxima etapa é fazer parsing com o conteúdo HTML usando o Beautiful Soup. Isso pode ser feito criando um objeto BeautifulSoup e passando o conteúdo HTML para ele. Aqui está um exemplo:
html_content = '<html><head><title>Example</title></head><body><p> This is a sample HTML document.</p></body></html>' soup = BeautifulSoup(html_content, 'html.parser')
Aqui, criamos um objeto BeautifulSoup chamado soup passando a string html_content para o construtor BeautifulSoup.
Também especificamos o analisador a ser usado como ‘html.parser‘.
Passo 4: Extraindo Dados de Tags HTML
Quando tivermos o objeto BeautifulSoup, poderemos usá-lo para extrair dados de tags HTML. Por exemplo, para extrair o texto da tag <p> no conteúdo HTML, podemos usar o seguinte código:
p_tag = soup.find('p')
p_text = p_tag.text
print(p_text)
Isso produzirá o texto “This is an example HTML document”, que é o conteúdo da tag <p> no documento HTML.
Passo 5: Usando as Funções do BeautifulSoup
Também podemos extrair atributos de tags HTML. Por exemplo, para extrair o valor do atributo href da tag a, podemos usar o seguinte código:
a_tag = soup.find('a')
href_value = a_tag['href']
print(href_value)
Isso produzirá o valor do atributo href da primeira tag a no documento HTML.
Além disso, também podemos usar a função “get_text()” para recuperar todo o texto do documento HTML.
Você pode usar o código a seguir para obter todo o texto do documento HTML:
soup.get_text()
Você aprendeu a usar o BeautifulSoup com Python para extrair dados com sucesso.
Há muitas outras funções úteis do BeautifulSoup que você pode aprender e usar para adicionar variações ao seu data scraper.
Visão geral do uso de expressões regulares para extrair dados de páginas Web
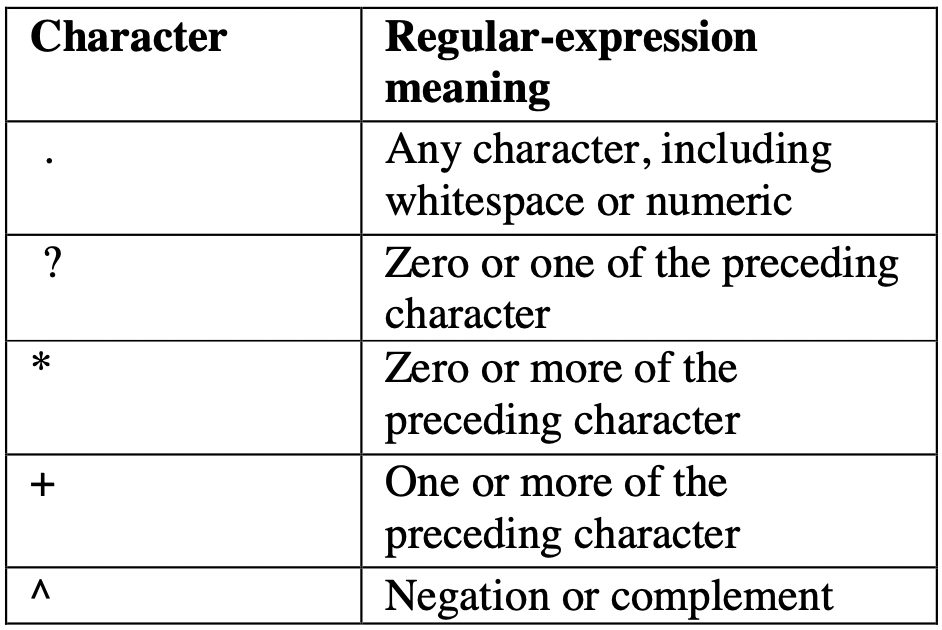
As expressões regulares (regex) são poderosas para correspondência de padrões e manipulação de texto.
Elas podem ser usadas para extrair dados de páginas da Web por meio da busca de padrões ou sequências de caracteres específicos.
Precisamos usar os seguintes tokens de regex para extrair dados.
 Aqui está uma visão geral do uso de expressões regulares para extrair dados de páginas da Web:
Aqui está uma visão geral do uso de expressões regulares para extrair dados de páginas da Web:
Passo 1: Instalar as Bibliotecas Apropriadas
Também precisaremos usar Requests e o BeautifulSoup aqui. Também importaremos uma biblioteca chamada “re”, um módulo Python integrado para trabalhar com expressões regulares.
import requests from bs4 import BeautifulSoup import re
Passo 2: Entendendo as Expressões Regulares
Antes de usar expressões regulares para extrair dados de páginas da Web, precisamos ter um conhecimento básico sobre elas.
Elas são padrões usados para combinar combinações de caracteres em cadeias de caracteres. Elas podem pesquisar, substituir e validar texto com base em um padrão
Passo 3: Encontrando o Padrão
Para extrair dados de páginas da Web usando expressões regulares, precisamos primeiro encontrar o padrão que queremos corresponder.
Isso pode ser feito inspecionando o código-fonte HTML da página da Web e identificando o texto ou a tag HTML específica da qual queremos extrair dados.
page = requests.get('https://example.com/')
soup = BeautifulSoup(page.content, 'html.parser')
content = soup.find_all(class_='product_pod')
content = str(content)
Passo 4: Escrevendo a Expressão Regular
Depois de identificarmos o padrão que queremos corresponder, podemos escrever uma expressão regular para procurá-lo na página da Web.
As expressões regulares são escritas usando uma combinação de caracteres e metacaracteres que especificam o que queremos corresponder. Por exemplo, para corresponder a um número de telefone em nossa página da Web de exemplo, poderíamos escrever a expressão regular:
number = r'\d{3}-\d{3}-\d{4}'
Essa expressão regular corresponde a um padrão que consiste em três dígitos seguidos de um hífen, mais três dígitos, outro hífen e mais quatro dígitos.
Este é apenas um pequeno exemplo de como podemos usar expressões regulares e suas combinações para extrair dados. Você pode experimentar usar mais tokens e expressões regex em seu empreendimento de coleta de dados.
Como Salvar Dados Extraídos em um Arquivo
Agora que você aprendeu a extrair dados de sites e arquivos XML, precisamos ser capazes de salvar os dados extraídos em um formato adequado.
Para salvar os dados extraídos da extração de dados em um arquivo como CSV ou JSON em Python, siga os seguintes passos simples:
Passo 1: Extrair e Organizar os Dados
Use uma biblioteca ou ferramenta para coletar os dados que deseja salvar e organizá-los em um formato que possa ser salvo em um arquivo. Por exemplo, você pode usar um dicionário ou uma lista para organizar os dados.
Passo 2: Escolher um Formato de Arquivo
Decida qual formato de arquivo você deseja usar para salvar os dados. Neste exemplo, usaremos CSV e JSON. Um arquivo CSV (valores separados por vírgula) é um arquivo de texto que permite que os dados sejam salvos em um formato de tabela.
O formato de dados JSON é um formato de arquivo (.json) usado para a troca de dados por meio de diversas formas de tecnologia.
Passo 3: Salvar Dados em um Arquivo CSV
Para salvar dados em um arquivo CSV, você pode usar o módulo CSV no Python. Veja como:
import csv
# data to be saved
data = [
['Jay', 'Dominic', 25],
['Justin', 'Seam', 30],
['Bob', 'Lans', 40]
]
# open a file for writing
with open('data.csv', mode='w', newline='') as file:
# create a csv writer object
writer = csv.writer(file)
# write the data to the file
writer.writerows(data)
Passo 4: Salvar Dados em um Arquivo JSON
Para salvar dados em um arquivo JSON, você pode usar o módulo json no Python. Veja como:
import json
# data to be saved
data = [
{'name': 'John', 'surname': 'Doe', 'age': 25},
{'name': 'Jane', 'surname': 'Smith', 'age': 30},
{'name': 'Bob', 'surname': 'Johnson', 'age': 40}
]
# open a file for writing
with open('data.json', mode='w') as file:
# write the data to the file
json.dump(data, file)
Em ambos os casos, o código cria um arquivo (se ele não existir) e grava os dados extraídos no formato de arquivo escolhido.
Dicas e Boas Práticas para o Desenvolvimento de Aplicações de Web Scraping Robustas e Escaláveis
É hora de simplificar o processo de web scraping.
A criação de uma aplicação robusta e escalável pode lhe poupar tempo, trabalho e dinheiro.
Aqui estão algumas dicas e práticas recomendadas que você deve ter em mente ao desenvolver aplicações de web scraping:
1. Respeite os Termos de Serviço do Site e as Leis de Direitos Autorais
Antes de começar a extrair dados de um site, leia seus termos de serviço e políticas de direitos autorais. Alguns sites podem proibir o web scraping e outros podem exigir que você credite a fonte dos dados ou obtenha permissão antes de usá-los.
Ignorar os termos de serviço ou o arquivo robots.txt pode resultar em problemas judiciais ou ser bloqueado pelo servidor do site.
2. Entenda a Estrutura e as APIs do Site
Compreender a estrutura e o conteúdo de um site ajuda a identificar os dados a serem extraídos. Ferramentas como o Web Scraper podem ajudar a inspecionar o HTML e encontrar elementos de dados. As APIs de sites oferecem acesso a dados estruturados e legais.
Portanto, certifique-se de usá-las sempre que possível para obter escalabilidade e conformidade com padrões éticos e legais.
3. Trate os Erros de Maneira Graciosa
Ao extrair dados de um site, pode haver momentos em que o site esteja fora do ar, a conexão seja perdida ou os dados não estejam disponíveis.
Por isso, é importante lidar com todos esses erros de forma elegante, adicionando mecanismos de tratamento de erros e de repetição ao seu código. Isso garantirá que sua aplicação seja robusta e possa lidar com situações inesperadas.
Uma maneira de tratar erros é usar blocos try-catch para capturar e tratar exceções. Por exemplo, se uma requisição de scraping falhar, você poderá tentar novamente a requisição após um determinado período de tempo ou passar para a próxima requisição.
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Code to extract data from the soup object
except requests.exceptions.RequestException as e:
# Handle exceptions related to the requests module
print("An error occurred while making the request:", e)
except Exception as e:
# Handle all other exceptions
print("An error occurred:", e)
finally:
# Clean up code (if any) that needs to run regardless of whether an exception was raised or not
No exemplo acima, estamos usando a biblioteca de requisições para solicitar um site e, em seguida, usando o Beautiful Soup para extrair dados do conteúdo HTML da resposta. O bloco try contém o código que pode gerar uma exceção, como um erro de rede ou um erro relacionado à análise de conteúdo HTML.
O registro também é uma ferramenta útil para debugging e solução de problemas de erros.
4. Teste Seu Código Exaustivamente
Ao desenvolver uma aplicação de web scraping, é importante testar seu código minuciosamente para garantir que ele funcione correta e eficientemente. Use frameworks e ferramentas de teste para automatizar seus testes e detectar erros no início do desenvolvimento.
O controle de versão é um sistema que rastreia as alterações no seu código ao longo do tempo. Ele permite que você acompanhe as alterações, colabore com outras pessoas e reverta para versões anteriores, se necessário.
O Git é um sistema popular de controle de versão amplamente utilizado no setor de desenvolvimento de software.
5. Use Ferramentas de Web Scraping Apropriadas
Conforme mencionado nas seções anteriores, existem muitas ferramentas de web scraping no mercado. Cada ferramenta tem seus pontos fortes e fracos, e a escolha da melhor ferramenta para um determinado projeto depende de diversos fatores.
Esses fatores incluem:
- a complexidade do site
- a quantidade de dados a serem extraídos
- o formato de saída desejado
Vamos dar uma visão geral de algumas ferramentas de web scraping e seu uso:
- O Beautiful Soup é uma ótima opção para projetos simples de web scraping que exigem análise básica de HTML.
- O Scrapy é mais adequado para projetos complexos que exigem técnicas avançadas de extração de dados, como paginação ou manipulação de conteúdo dinâmico.
- O Selenium é uma ferramenta poderosa para web scraping de sites dinâmicos que exigem interações do usuário; pode ser mais lento e exigir mais recursos do que outras ferramentas.
6. Evite a Detecção por Sites
O web scraping pode consumir muitos recursos e sobrecarregar o servidor do site, fazendo com que você seja bloqueado.
Para contornar isso, você pode tentar alterar proxies e agentes de usuário. É um jogo de esconde-esconde, que impede que o bot de um site bloqueie você.
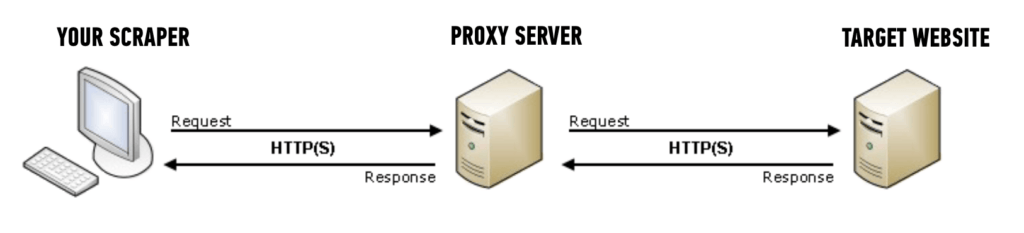 If you’re wondering what proxies are, here’s a simple answer:
If you’re wondering what proxies are, here’s a simple answer:
São intermediários que ocultam seu endereço de IP e fornecem um novo endereço ao servidor do site, tornando mais difícil para o servidor detectar que você está fazendo scraping do site.
Os agentes de usuário são cadeias de caracteres que identificam o navegador da Web e o sistema operacional usados para acessar o site.
Ao alterar o agente de usuário, você pode fazer com que suas requisições de web scraping pareçam vir de diferentes navegadores ou dispositivos, o que pode ajudar a evitar a detecção.
7. Gerencie Sua Base de Código e Lide com Grandes Volumes de Dados
A extração pode gerar grandes quantidades de dados. Armazene os dados com sabedoria para evitar a sobrecarga do sistema, considerando bancos de dados como PostgreSQL, MySQL ou SQLite e armazenamento em nuvem.
Use ferramentas de documentação, como Sphinx e Pydoc, e linters, como Flake8 e PyLint, para garantir a legibilidade e detectar erros.
As técnicas de cache e chunking ajudam a reduzir as requisições do site e a lidar com grandes conjuntos de dados sem problemas de memória. A fragmentação consiste em dividir grandes arquivos ou conjuntos de dados em partes menores e mais gerenciáveis.
8. Introdução à Extração de Sites que Exigem Autenticação
A aquisição de acesso para data scraping refere-se à obtenção de permissão ou autorização para extrair dados de um site ou fonte on-line. É importante obter acesso porque o data scraping sem permissão pode ser ilegal ou violar os termos de uso do site.
É preciso ter uma autenticação válida para usar qualquer dado de uma plataforma on-line e garantir que ele seja usado somente para fins éticos e legais.
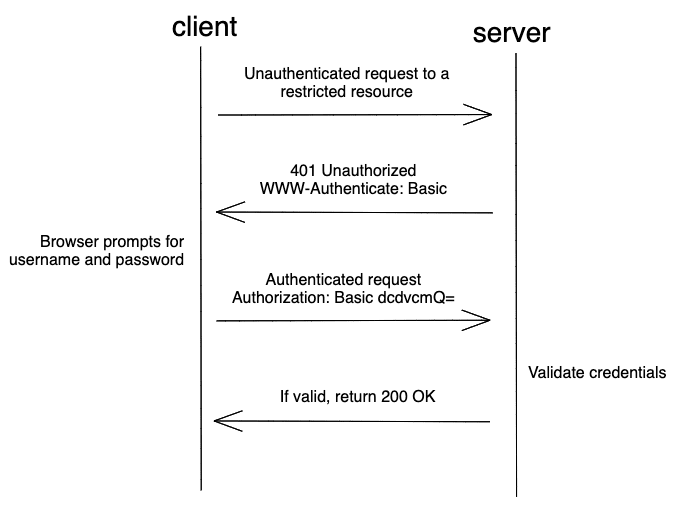
O scraping de sites que exigem autenticação pode ser mais desafiador do que o scraping de sites públicos, pois eles exigem que o usuário seja autenticado e autorizado a acessar determinadas informações.
No entanto, há diferentes maneiras de autenticar e extrair esses sites.
Frameworks de Web Scraping
Um método comum é usar frameworks de web scraping como Scrapy ou Beautiful Soup e bibliotecas como Requests para autenticar e acessar o conteúdo do site.
O processo de autenticação envolve o envio de um nome de usuário e senha para o formulário de login do site, geralmente enviado como uma requisição POST.
Após a autenticação bem-sucedida, os dados coletados podem ser extraídos do HTML do site usando bibliotecas de análise como Beautiful Soup ou lxml.
Ferramentas de Automação da Web
Ferramentas de automação da Web, como Selenium ou Puppeteer, simulam as interações do usuário com o site.
Essas ferramentas podem automatizar todo o processo de autenticação preenchendo o formulário de login e clicando no botão enviar.
Depois de autenticado, o scraper pode usar ferramentas de automação da Web para navegar no site e extrair dados.
Lidar com Cookies e Gerenciamento de Sessão
Muitos sites utilizam cookies para gerenciar sessões e manter a autenticação do usuário. Ao fazer scraping de sites que exigem autenticação, é fundamental lidar com os cookies corretamente para manter o estado da sessão e evitar que o usuário seja desconectado.
Você pode usar bibliotecas como Requests Session ou Scrapy Cookies Middleware para gerenciar cookies automaticamente.
Sempre que um site é visitado, um bot armazena automaticamente cookies sobre o que você fez e como usou o site. O Scrapy Cookies Middleware pode desativar os cookies por um tempo para que a coleta de dados possa ser realizada com êxito.
Alguns sites limitam o número de requisições que você pode fazer em um determinado período de tempo, o que pode resultar em bloqueio de IP ou suspensão da conta.
Para evitar a limitação da velocidade, você pode usar técnicas como delays aleatórios, proxies rotativos e rotação do agente de usuário.
Visão geral do GoLogin como um poderoso navegador antidetecção para web scraping
Aprendemos sobre data scraping, seus usos, como usá-lo e quais ferramentas usar. Mas há mais uma ferramenta com a qual você deve estar familiarizado ao extrair dados da Internet.
O GoLogin é uma ferramenta avançada para múltiplas contas e um navegador anônimo que pode ser usado para web scraping com Python. Ele foi projetado para ajudar os usuários a evitar a detecção durante a coleta de dados de sites, permitindo que eles alternem endereços de IP, impressões digitais do navegador, agentes de usuário, etc.
Aqui estão algumas características do GoLogin que o tornam uma ferramenta poderosa para web scraping:
1. Tecnologia Antidetecção:
O GoLogin usa uma avançada tecnologia antidetecção para dificultar que os sites identifiquem o comportamento de bots de web scrapers.
2. Impressão digital do navegador:
Esse navegador anônimo permite que os usuários criem e alternem as digitais do navegador, que são identificadores exclusivos que os sites usam para rastrear os usuários. Ao alternar as digitais, os usuários podem evitar serem detectados como scrapers.
3. Rotação de IP:
O GoLogin é um software avançado que permite aos usuários alternar endereços de IP, o que ajuda a evitar a detecção por sites que rastreiam endereços de IP.
4. Múltiplos Perfis de Navegador:
O GoLogin funciona como um navegador com várias contas que permite aos usuários criar e gerenciar vários perfis de navegador, cada um com seu próprio conjunto de impressões digitais de navegador, endereços IP e agentes de usuário.
Como Configurar o GoLogin e Usar o Gerenciador de Proxy e o Gerenciador de Digitais
Vamos ver como usar seus recursos e funcionalidades.
Passo 1: Faça o download e instale o GoLogin

Você pode fazer o download do GoLogin no site deles e seguir as instruções de instalação. Clique aqui para baixar.
Passo 2: Crie um novo perfil
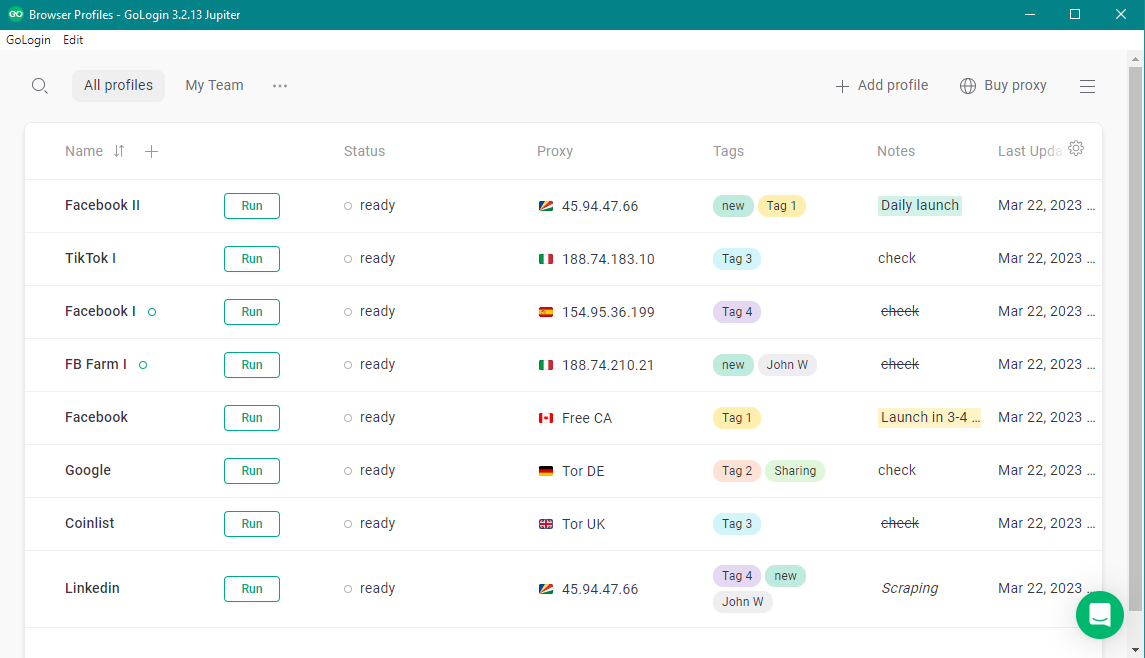
Depois de instalar o GoLogin, abra o programa e crie um novo perfil clicando no botão “Adicionar perfil”. Dê um nome ao perfil e passe para as abas de configurações.
Mantenha as configurações de impressão digital recomendadas pelo GoLogin para obter melhores resultados: mesmo uma opção alterada a seu critério pode afetar o anonimato do navegador.
Passo 3: Configure os proxies
Nas configurações de perfil, clique na aba “Gerenciador de Proxy”. Aqui você pode adicionar e gerenciar proxies.
Clique em “Adicionar” para adicionar um novo proxy. Todos os tipos comuns de proxy são compatíveis.
Você pode adicionar proxies manualmente, importá-los em massa de um arquivo ou usar os proxies incorporados do GoLogin. Esses últimos podem ser comprados e recarregados no canto superior direito (botão Comprar Proxy).
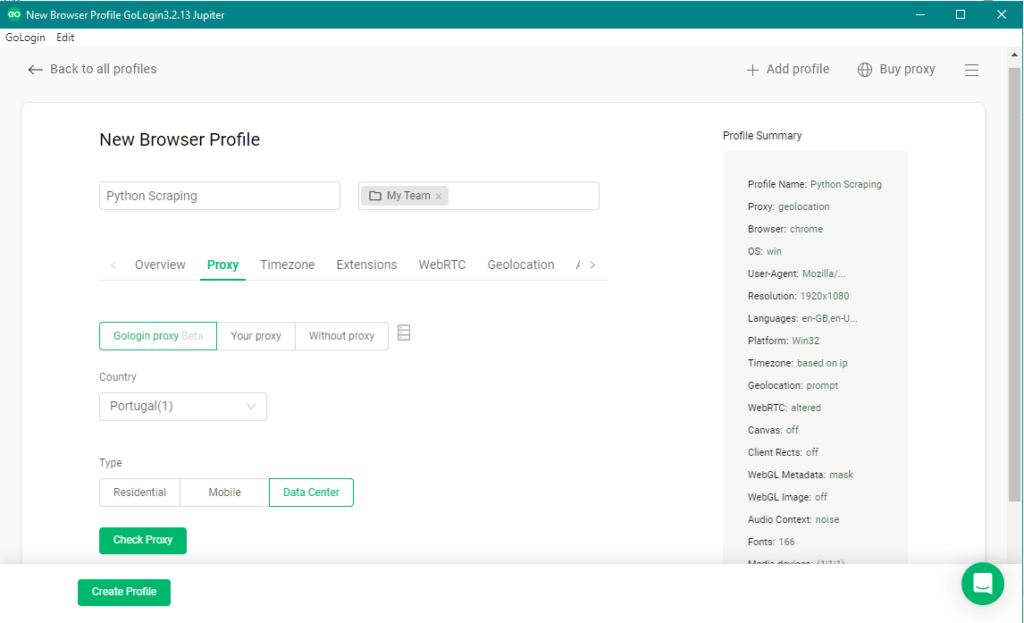
Passo 4: Use o perfil para web scraping com Python
Depois de configurar os gerenciadores de digitais e proxies, você poderá usar o perfil para web scraping. Vá para a aba “Perfis” e selecione um perfil.
Clique no botão “Iniciar” para abrir uma nova janela do navegador com o perfil. Use essa janela do navegador para suas atividades de web scraping.
Ao configurar a digital e os proxies no GoLogin, você pode criar um ambiente altamente personalizado e seguro para web scraping.
Automatização de tarefas de web scraping usando a API do GoLogin
A API do GoLogin permite automatizar as tarefas de web scraping, fornecendo acesso programático aos recursos do GoLogin.
Com a API, você pode automatizar tarefas como a criação e o gerenciamento de perfis, o gerenciamento de proxies e digitais e a abertura de janelas do navegador. Por exemplo, talvez você tenha um site de compras on-line em que deseja extrair as informações do produto diariamente.
Para começar, você precisará obter um token de API, conforme descrito aqui. Em seguida, faça o download do wrapper de Python do GoLogin (ou simplesmente faça o download diretamente do GitHub):
git clone https://github.com/gologinapp/pygologin.git
Seu script Python deve estar no mesmo diretório que o arquivo “gologin.py”. A seguir, detalharemos e explicaremos o código de exemplo.
Passo 1: Autenticar sua chave de API
Conecte-se ao GoLogin usando o token de API que você obteve anteriormente. Depois de autenticado, você pode começar a criar perfis e iniciar sessões de navegador.
import time
from selenium import webdriver #Installing selenium is explained in Step 4. under How To Set Up a Development Environment for Web Scraping With Python
from selenium.webdriver.chrome.options import Options
from gologin import GoLogin
from gologin import get_random_port
# random_port = get_random_port() # uncomment to use random port
gl = GoLogin({
"token": "yU0token", #The API token you generated earlier.
"profile_id": "yU0Pr0f1leiD",
# "port": random_port
})
#See Step 3 for continued code.
Passo 2: Criar um perfil
Use a API para criar um novo perfil com configurações específicas, como digitais e proxies. Isso fará com que a sessão do navegador pareça mais humana.
Por exemplo, talvez você queira usar uma versão específica do navegador, um sistema operacional ou um idioma para o seu perfil.
from gologin import GoLogin
gl = GoLogin({
"token": "yU0token",
})
profile_id = gl.create({
"name": 'profile_windows',
"os": 'win', #mac for MacOS, and lin for Linux systems.
"navigator": {
"language": 'en-US',
"userAgent": 'random', # Chrome, Mozilla, etc (if you don't want to change, leave it at 'random')
"resolution": '1920x1080',
"platform": 'Win32',
},
'proxyEnabled': True, # Specify 'false' if you are not using a proxy.
'proxy': {
'mode': 'gologin',
'autoProxyRegion': 'us'
# 'host': '',
# 'port': '',
# 'username': '',
# 'password': '',
},
"webRTC": {
"mode": "alerted",
"enabled": True,
},
})
profile = gl.getProfile(profile_id)
Passo 3: Abrir uma janela do navegador
Isso abrirá uma nova sessão do navegador com as configurações que você especificou no perfil.
Em seguida, você pode interagir com a janela do navegador de forma programática para extrair dados de sites ou executar outras tarefas automatizadas.
debugger_address = gl.start()
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", debugger_address)
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
driver.get("THE URL TO BE SCRAPED")
#Your code here
driver.close()
time.sleep(3)
gl.stop()
Passo 4: Extrair o site
Por fim, combine a API do GoLogin com ferramentas padrão, como o BeautifulSoup ou o Selenium, e você terá um poderoso web scraper na ponta dos dedos! Informações como manchetes de notícias e descrições de produtos podem ser extraídas e parsed em documentos HTML ou XML com facilidade.
Perguntas Frequentes
Para que serve o web scraping?
O web scraping é utilizado para extrair informações de websites de forma automatizada. Pode-se coletar dados como preços, avaliações de produtos, notícias, entre outros, para análise, comparação ou integração em outros sistemas.
Como fazer web scraping?
Para fazer web scraping, é necessário usar uma combinação de bibliotecas ou frameworks específicos, como Beautiful Soup, Selenium ou Scrapy. É preciso identificar os elementos do site a serem coletados, criar um script que acesse o site, extraia os dados desejados e, se necessário, armazene-os em um formato adequado.
Qual a melhor linguagem de programação para web scraping?
Embora seja possível realizar web scraping em várias linguagens, Python é amplamente considerada a melhor escolha devido à sua facilidade de uso, disponibilidade de bibliotecas poderosas, como BeautifulSoup e Selenium, e uma comunidade ativa que compartilha recursos e soluções para problemas comuns.
Como usar o scraper?
Para usar um scraper, é necessário identificar as páginas que deseja raspar e os dados que precisa extrair. Em seguida, escolha uma biblioteca de scraping adequada para a linguagem de programação escolhida, desenvolva um script que navegue pelas páginas e extraia as informações desejadas.
Execute o script e armazene os dados conforme necessário.
Quais ferramentas devo usar para fazer web scraping com segurança?
As ferramentas exatas que você usa podem fazer uma grande diferença em seu sucesso. Na maioria dos casos, sua escolha depende muito do que você vai extrair.
Alguns sites têm medidas extremas contra a coleta de dados – eles detectam e bloqueiam o tráfego de bots ou usam captchas para verificar usuários humanos.
É nesse ponto que o navegador GoLogin pode ser uma ferramenta valiosa para os web scrapers. Originalmente um navegador de privacidade, ele é amplamente usado como uma ferramenta confiável de proteção contra scrapers que oferece todos os recursos necessários.
Ele inclui:
- controle completo sobre as digitais do navegador e os agentes de usuário
- proxies incorporados com opções de rotação
- gerenciamento de cookies
- gerenciamento de múltiplos perfis com configurações avançadas
- ótimas opções de API e modo headless.
O GoLogin permite que os usuários criem múltiplos perfis de navegador e alternem entre eles, dificultando a detecção e o bloqueio do scraper pelos sites. Com o GoLogin, seu scraper se parece com um usuário comum e continua a extrair dados de sites sem nenhuma interrupção.
O web scraping Web faz parte da ciência de dados em um sentido global?
A resposta curta é sim. Os cientistas de dados geralmente usam o web scraping para coletar dados de sites e outras fontes on-line para obter insights e informar suas pesquisas ou decisões de negócios.
No entanto, o web scraping é apenas a primeira etapa do processo de ciência de dados. Depois que os dados são coletados, eles precisam ser limpos, estruturados e analisados para extrair insights significativos.
É aí que começa o verdadeiro trabalho da ciência de dados.
Como a IA pode ser usada em web scraping?
A inteligência artificial (IA) pode ser usada no web scraping para melhorar sua eficiência e precisão.
1. Extrair automaticamente dados de sites sem a necessidade de codificação ou configuração manual. Esses algoritmos podem aprender com as sessões de scraping anteriores e se adaptar às mudanças no site, tornando o processo mais eficiente e eficaz.
2. Analisar os dados extraídos usando técnicas de processamento de linguagem natural (NLP) e de reconhecimento de imagens. Isso permite que você extraia insights de dados não estruturados, como textos e imagens, o que pode ser particularmente útil para análise de sentimentos e monitoramento de marcas.
3. Melhorar a qualidade dos dados extraídos detectando e corrigindo erros em tempo real. Por exemplo, ferramentas como o GPT podem identificar e remover entradas duplicadas, normalizar formatos de dados e validar dados em relação a regras predefinidas.
Como salvar dados extraídos como um arquivo CSV usando o Scrapy?
Depois de extrair os dados, você provavelmente desejará salvá-los em um formato fácil de trabalhar, como um arquivo CSV. Veja como você pode fazer isso usando o Scrapy:
1. Primeiro, você precisa definir os dados que deseja salvar na classe “items” do seu spider do Scrapy. Isso definirá os campos do seu arquivo CSV.
2. Em seguida, adicione as configurações “FEED_FORMAT” e “FEED_URI” ao seu arquivo de configurações do Scrapy. O “FEED_FORMAT” especifica o formato de saída (“csv”, neste caso) e o “FEED_URI” especifica o local onde o arquivo deve ser salvo.
3. Por fim, modifique o método “parse” do seu spider do Scrapy para incluir o código que salva os dados extraídos no arquivo CSV. Você pode usar a instrução “yield” para enviar cada item para o arquivo CSV.
Aqui está um exemplo de trecho de código para ajudar a esclarecer o processo:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
custom_settings = {
'FEED_FORMAT': 'csv',
'FEED_URI': 'data.csv'
}
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
Neste exemplo, estamos extraindo citações de um site e salvando-as em um arquivo CSV chamado “data.csv”. A instrução “yield” envia cada citação extraída para o arquivo CSV, que é criado automaticamente pelo Scrapy quando o spider é executado.
Como faço para extrair dados com Python?
Há várias bibliotecas e estruturas disponíveis em Python que permitem a qualquer entusiasta extrair dados de sites. Aqui está um processo simples para ajudá-lo a começar:
Primeiro, escolha uma ferramenta de web scraping com Python que atenda às suas necessidades. Algumas opções populares incluem BeautifulSoup, Scrapy, Selenium, Requests e PyQuery.
Depois de escolher uma ferramenta, instale-a usando o pip, o gerenciador de pacotes Python. Você pode instalar a maioria das ferramentas com um único comando, como “pip install beautifulsoup4”.
Em seguida, escreva seu código de scraping. Isso dependerá da ferramenta que estiver usando, mas, em geral, você precisará enviar uma requisição HTTP para o site que deseja extrair e analisar a resposta para extrair os dados desejados.
Por fim, salve os dados extraídos usando um formato como CSV ou JSON. Você também pode usar bibliotecas Python, como Pandas ou NumPy, para analisar e visualizar os dados.
Como faço para transformar minhas habilidades de web scraping em Python em renda?
Aqui estão algumas etapas básicas que você pode seguir:
- Identificar clientes potenciais – Procure empresas ou indivíduos que possam precisar de extração de dados. Você pode iniciar sua pesquisa navegando em classificados de empregos, plataformas de freelancer ou entrando em contato com empresas do seu nicho.
- Criar um portfólio que mostre suas habilidades e projetos anteriores. Isso pode incluir exemplos de código, estudos de caso e visualizações de dados que você extraiu.
- Aprender linguagens de programação e ferramentas adicionais – Aumente seu valor aprendendo linguagens de programação adicionais, como R ou JavaScript, além de outras bibliotecas populares de web scraping, como BeautifulSoup ou Scrapy.
- Oferecer serviços de valor agregado – serviços de limpeza, análise ou visualização de dados, além de web scraping.
- Definir preços competitivos – pesquise os preços de mercado e defina um preço razoável para seus serviços. Não se limite a diminuir o preço de seus concorrentes: preços extremamente baixos podem jogar contra você.
- E por último, mas não menos importante – utilize plataformas de freelance. Participe de plataformas de freelance como Upwork, Fiverr ou Freelancer para encontrar clientes e aprimorar suas habilidades.
Como posso proteger meu scraper de medidas contra bots?
Ao extrair dados de sites, é importante considerar as medidas contra bots que os sites podem ter em vigor para impedir o acesso automatizado. Aqui estão algumas maneiras de proteger seu scraper contra medidas contra bots:
- Use proxies rotativos – Alterne os endereços de IP e use diferentes agentes de usuário para evitar ser detectado por mecanismos contra bots.
- Use navegadores headless – navegadores headless, como o Puppeteer, podem simular um comportamento semelhante ao humano e ajudar a contornar os mecanismos de detecção de bots.
- Observe os limites de frequência – Evite atingir o site com muitas requisições em um curto período de tempo.
- Use uma ferramenta confiável de proteção contra scrapers – ferramentas como o GoLogin oferecem proteção avançada de digitais do navegador, o que ajuda a superar as medidas contra bots e a evitar a detecção durante o scraping.
O GoLogin, originalmente um navegador de privacidade, é uma ferramenta confiável de proteção para scrapers que oferece todos esses recursos e seus benefícios. Ele inclui:
- controle total sobre as digitais do navegador
- proxies integrados com opções de rotação
- gerenciamento de cookies
- gerenciamento de múltiplos perfis com configurações avançadas
- opções de API e modo headless.
Com o GoLogin, você pode garantir que seu scraper se pareça com um usuário comum e continue a extrair dados de sites sem nenhuma interrupção.
Conclusão
E isso conclui nosso guia passo a passo sobre web scraping com Python! Agora que você aprendeu a extrair dados de sites usando Python, a Internet é o seu campo de jogo.
Desde analisar os preços dos concorrentes até acompanhar as menções da sua marca nas mídias sociais, as possibilidades de usar o web scraping em seus projetos comerciais ou pessoais são infinitas.
Lembre-se sempre de respeitar os proprietários de sites e seus termos de serviço ao extrair dados. Boa coleta de dados e que os deuses dos dados sorriam para você!
Aqui está um pequeno gráfico de classificação para que você possa fazer uma escolha:
| Ferramenta | Velocidade de Trabalho | Flexibilidade | Melhor para |
|---|---|---|---|
| Beautiful Soup | Moderado | Alta | Parsing de HTML e XML |
| Scrapy | Rápido | Alta | Projetos de grande escala |
| Selenium | Devagar | Alta | Extração de conteúdo dinâmico |
| Octoparse | Rápido | Baixa-Moderada | Usuários não técnicos |
| Parsehub | Rápido | Alta | Web scraping simples |
| LXML | Rápido | Baixa-Moderada | Parsing de HTML e XML |
Em geral, o Scrapy é a ferramenta mais avançada e flexível para projetos de web scraping em grande escala. O Selenium é ideal para a extração de sites com conteúdo dinâmico. O Beautiful Soup e o LXML são ótimos para fazer parsing de HTML e XML. O Octoparse é uma ferramenta fácil de usar para iniciantes com uma interface amigável, enquanto o Parsehub é mais adequado para tarefas simples de web scraping.
Observação: As classificações são subjetivas e baseadas em minha experiência pessoal com as ferramentas.
Sinta-se à vontade para experimentar o GoLogin, uma poderosa e profissional ferramenta de privacidade projetada para tornar sua experiência de web scraping mais fácil e eficiente.


