
Há uma nova maneira de bypass Cloudflare com um novo serviço de web scraping: navegadores de antidetecção.
Se você pesquisar no Google “how to bypass Cloudflare”, você encontrará centenas de artigos e recursos do Github explicando como fazer o Cloudflare bypass (ou vender uma solução para fazer isso). O motivo é bastante simples: A solução Cloudflare Bot Management é uma das mais fortes e mais usadas proteções antibot usadas na Internet.

O que é Cloudflare Bot Management?
O Cloudflare Bot Management é um conjunto de ferramentas de segurança projetado para proteger sites contra bots mal-intencionados e ataques automatizados. Ele oferece proteção avançada contra uma ampla gama de ameaças de bots, incluindo preenchimento de credenciais, contornos de Web e controle de contas.
O Cloudflare Bot Management inclui o Web Application Firewall (WAF). Isso ajuda a impedir que o tráfego mal-intencionado chegue ao servidor de origem de um site. As medidas de segurança do WAF da Cloudflare usam algoritmos avançados de aprendizado de máquina para analisar padrões de tráfego e identificar possíveis ameaças.
Outro recurso importante do gerenciamento de bots da Cloudflare é a capacidade de resolução de bypass de DNS para bots reconhecidamente bons. Isso permite que bots legítimos acessem um site sem serem bloqueados por medidas de segurança.
Além disso, o Bot Management da Cloudflare oferece uma série de medidas de segurança por meio de seus registros de DNS. Com os endereços de IP do DNS da Cloudflare, os usuários podem desfrutar de uma experiência de navegação mais rápida e segura. O DNS da Cloudflare foi projetado para proteger os usuários contra phishing, malware e outras ameaças on-line.
Em geral, o Cloudflare Bot Management oferece soluções de segurança robustas e abrangentes para proteger os sites contra o tráfego de bots. As medidas de segurança descritas acima são extremamente difíceis de serem contornadas. Os proprietários de sites podem garantir que seus sites estejam protegidos contra todos os tipos de bots e ataques automatizados.
Burlar o Cloudflare é Realmente Tão Difícil?
– Sim.
As medidas de segurança tradicionais dependem de bloqueio de IP ou CAPTCHAs, o que faz um cloudfare bypass online muito difícil. A solução Cloudflare Bot Management usa algoritmos avançados de machine learning para analisar as requisições que chegam ao site. Portanto, ela é capaz de identificar naturalmente os bots interpretando seus padrões de comportamento típicos.
Aqui estão alguns exemplos do que os bots têm grande probabilidade de fazer:
- fazer um grande número de requisições em um curto período de tempo
- usar um tipo específico de agente de usuário ou endereço de IP
- ter impressões digitais inconsistentes/suspeitas.
A solução Cloudflare Bot Management também é difícil de ser contornada porque é constantemente ensinada a detectar novos tipos de bots de web scraping. A empresa usa algoritmos de machine learning. Isso os ajuda a atualizar seus métodos de detecção.
Isso permite que eles identifiquem e bloqueiem rapidamente novos tipos de bots assim que eles aparecem.

Outro ponto problemático do Cloudflare bypass online é o fato de ser uma solução altamente personalizada. Os métodos que funcionam para um site provavelmente serão inúteis para outro.
Postei anteriormente sobre a Cloudflare, fornecendo três soluções para três sites diferentes. Entretanto, apenas duas dessas soluções continuam funcionando. Nas últimas semanas, tive dificuldades para usar o Playwright com o site da Antonioli para contornar o Cloudflare. Depois de algumas páginas, fui bloqueado novamente, especialmente quando a execução estava sendo feita dentro de uma VM no AWS.
Portanto, a verdade é que não há solução mágica contra o gerenciamento de bots do Cloudflare. No entanto, há soluções que funcionam bem.
Como a Cloudflare detecta bots?
A Cloudflare é uma rede de entrega de conteúdo (CDN, da sigla em inglês) de alto nível e uma empresa de segurança na nuvem. Eles fornecem serviços para proteger sites contra ameaças on-line. Essas ameaças incluem ataques de bots. A Cloudflare usa várias técnicas para detectar bots e impedir que eles acessem sites.
Vamos abordar alguns dos métodos que a Cloudflare emprega para identificar bots.
- Strings de Agente de Usuário. São partes de texto incluídas em requisições HTTP enviadas por navegadores ou outros clientes para o servidor da Web. Essas strings geralmente contêm informações sobre o sistema operacional do cliente, o tipo de navegador, a versão e outros detalhes relevantes. Ele faz isso examinando as cadeias de caracteres do agente de usuário. Essas strings indicam se a solicitação vem de um navegador ou de um bot. Os bots geralmente usam strings de agente de usuário genéricas ou desatualizadas, o que pode ajudar a Cloudflare a identificá-los.
- Reputação do Endereço de IP (Confiança). A rede da Cloudflare mantém um banco de dados de endereços de IP conhecidos por atividades mal-intencionadas, como spam, phishing e distribuição de malware. A Cloudflare pode bloquear ou contestar requisições de endereços de IP com reputação ruim (também conhecida como confiança de IP). Isso dificulta a extração de dados por bots mal-intencionados. O CAPTCHA é usado para desafiar o autor da requisição.
- Desafio de JavaScript. A Cloudflare pode usar desafios de JavaScript para verificar se um cliente é humano ou bot. Sempre que uma requisição é enviada a um site protegido pela Cloudflare, o servidor responde enviando um trecho de código JavaScript. Esse código deve então ser executado pelo cliente. O servidor permite o acesso ao site se o cliente executar corretamente o código JavaScript. Isso significa que o usuário é legítimo. O cliente deve executar o código JavaScript corretamente. Se não o fizer, ou se não o executar, o servidor presumirá que se trata de um bot. O acesso ao site será negado.
- Limitação de Frequência. Outra maneira pela qual a Cloudflare detecta bots é usando a limitação de frequência. Essa técnica identifica padrões de comportamento que são típicos de bots. Um exemplo típico é o envio de um grande número de requisições em um curto período. A Cloudflare pode então bloquear ou contestar essas requisições, forçando o autor da requisição a diminuir a velocidade.
- Impressão Digital do Navegador é uma técnica que identifica um dispositivo de forma exclusiva. Ela faz isso analisando diferentes atributos do dispositivo, como o tamanho da tela, o tipo de navegador e os plug-ins instalados. A Cloudflare pode usar essa técnica para criar uma impressão digital de cada dispositivo que se conecta a um site protegido. Se a mesma impressão digital aparecer repetidamente, a Cloudflare pode presumir que se trata de um bot. A Cloudflare também pode usar a impressão digital do navegador para detectar bots que mudam suas sequências de agente de usuário com frequência. Como os outros atributos do dispositivo permanecem os mesmos, a Cloudflare pode usá-los para identificar o autor da requisição como um bot.
- Algoritmos de Machine Learning (ML): A Cloudflare emprega algoritmos de machine learning para analisar padrões no tráfego da Web e identificar bots com precisão. Esses algoritmos podem aprender a reconhecer bots com base em características como o número e a frequência das solicitações, os tipos de recursos solicitados e os endereços de IP dos autores das requisições. Os algoritmos de ML da Cloudflare também podem se adaptar rapidamente a novas ameaças. Pode surgir um novo tipo de ataque de bot. Os algoritmos podem aprender com exemplos de ataques anteriores. Eles podem, então, ajustar seus critérios de detecção de bots.
A Cloudflare combina diversas técnicas para identificar com precisão os bots que tentam acessar sites protegidos. Eles bloqueiam ou desafiam esses bots antes que eles possam causar qualquer dano.
Técnicas ativas de detecção de bots da Cloudflare
Aqui estão algumas das técnicas ativas de detecção de bots usadas pela Cloudflare para fornecer proteção de alto nível contra bots. Spoiler: elas evoluíram significativamente.
A Cloudflare investiu muito em machine learning e IA nos últimos anos. Isso permitiu a criação de algoritmos mais sofisticados para a detecção de bots.
As medidas antibot da Cloudflare provavelmente se adaptaram à medida que o cenário de ameaças evolui. Novos tipos de ataques de bots estão surgindo, e a Cloudflare está se mantendo à frente dessas ameaças.
Eles fizeram melhorias significativas em seus sistemas de limitação de taxa e rastreamento de eventos.
CAPTCHAs
Eles são uma maneira eficaz de impedir solicitações automatizadas de bots e, ao mesmo tempo, permitir que usuários humanos reais acessem o site.
A Cloudflare usa vários tipos de CAPTCHAs, como CAPTCHAs baseados em imagem e reCAPTCHA. Eles ajudam a verificar se o autor da requisição é um usuário humano real.
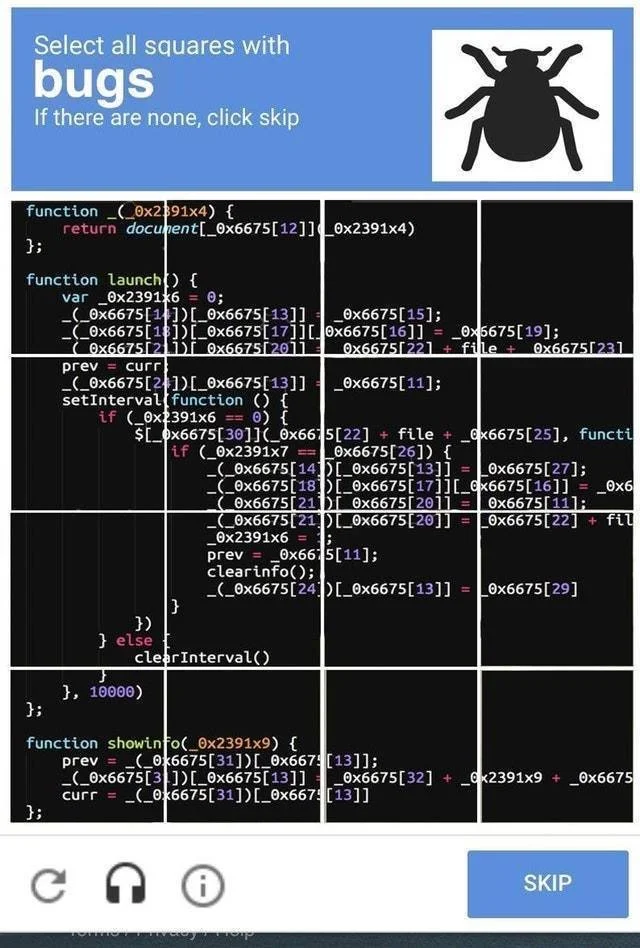
Fonte: Reddit
Esses desafios exigem que os usuários realizem ações que os bots não podem replicar facilmente. Algumas delas são identificar objetos em imagens ou resolver problemas simples de matemática.
Se o autor da requisição passar no desafio, ele poderá acessar o site. Caso contrário, ele será impedido de acessar o site.
Impressão Digital de Tela
Essa técnica captura atributos exclusivos do navegador de um usuário. Os exemplos incluem o tipo de placa de vídeo e o mecanismo de renderização. Esses atributos criam uma “impressão digital” exclusiva que pode ser usada para identificar usuários em diferentes sites.
A Cloudflare emprega a impressão digital de tela para detectar bots que usam cadeias de caracteres de agente de usuário falsas para ocultar sua identidade. Ao analisar a impressão digital de tela de cada requisição, a Cloudflare pode determinar se ela vem de um usuário legítimo ou de um bot.
Rastreamento de Eventos
É usado para monitorar as interações do usuário com um site, como cliques, visualizações de página e envios de formulários. A proteção antibot da Cloudflare usa o rastreamento de eventos para analisar padrões de comportamento do usuário e detectar anomalias que possam indicar atividade de bot.
Por exemplo, se um grande número de solicitações vier do mesmo endereço de IP em um curto período, a Cloudflare poderá presumir que se trata de um bot e bloquear as solicitações. Ao usar o rastreamento de eventos, a Cloudflare pode distinguir com precisão entre solicitações legítimas de usuários e requisições de bots.
Consulta de API de Ambiente
A consulta de API é usada para coletar informações sobre o ambiente do cliente, como o sistema operacional, o tipo de navegador e a resolução da tela. A Cloudflare usa essa técnica para identificar bots que usam strings de agente de usuário falsas ou outros métodos para mascarar sua identidade.
Ao analisar as variáveis de ambiente de cada solicitação, a Cloudflare pode detectar padrões de comportamento que são típicos de bots. A Cloudflare pode identificar e bloquear requisições de bots se houver um grande número de requisições com a mesma resolução de tela.
Reputação de Endereço de IP (Confiança)
A Cloudflare mantém um banco de dados de endereços de IP conhecidos por atividades maliciosas, como spam, phishing e distribuição de malware. A Cloudflare pode bloquear uma solicitação de um endereço de IP com má reputação ou desafiar o autor da requisição com CAPTCHAs.
A Cloudflare pode usar a reputação do endereço de IP para identificar rapidamente fontes mal-intencionadas. Isso protege os sites contra ataques de bots.
Algoritmos de Machine Learning
Eles são usados para analisar padrões no tráfego da Web e identificar bots com precisão. Os algoritmos podem aprender a identificar bots. Eles fazem isso observando características, como:
- O número e a frequência das requisições
- Os tipos de recursos solicitados
- Os endereços de IP.
![]()
Os algoritmos de ML da Cloudflare também podem se adaptar rapidamente a novas ameaças. Quando surge um novo tipo de ataque de bots, os algoritmos podem aprender com exemplos de ataques anteriores e ajustar seus critérios de detecção de bots de acordo.
Embora as técnicas anti bot da Cloudflare sejam eficazes na detecção e prevenção de muitos tipos de ataques de bots, ainda é possível que determinados invasores as contornem. No entanto, a dificuldade de contornar essas técnicas dependerá de diversos fatores, incluindo:
- a sofisticação do ataque,
- as técnicas específicas usadas pela Cloudflare
- e as medidas de segurança implementadas pelo proprietário do site.
Por exemplo, os CAPTCHAs podem ser contornados com o uso de ferramentas automatizadas ou com a terceirização da tarefa para trabalhadores humanos em países com baixos salários. Da mesma forma, a impressão digital da tela pode ser contornada com o uso de máquinas virtuais, navegadores de privacidade headless como o GoLogin ou outros métodos para ocultar a configuração real do hardware do dispositivo.
No entanto, os invasores sofisticados podem achar mais desafiador contornar algumas das técnicas mais avançadas usadas pela Cloudflare. Os algoritmos de aprendizado de máquina e a consulta à API do ambiente são mais difíceis de ignorar. Essas técnicas são projetadas para detectar padrões sutis de comportamento.
É difícil para os bots replicarem esses padrões, o que os torna mais resistentes a ataques.
Consulta de API de Ambiente: singular, mas normal
A consulta à API de Ambiente é uma técnica usada pela Cloudflare para identificar bots, analisando vários atributos do dispositivo do cliente. Isso inclui sistema operacional, tipo de navegador e resolução de tela. Pode ser difícil contornar essa técnica, pois ela se baseia na coleta de informações sobre o próprio dispositivo.
Os possíveis métodos para contornar a consulta à API de Ambiente podem incluir:
- máquinas virtuais
- navegadores de privacidade que gerenciam impressões digitais
- dispositivos com atributos falsos
- usando um serviço de anonimato que altera ou oculta as informações reais do dispositivo.
No entanto, esses métodos nem sempre são eficazes e podem acionar outras medidas anti-bot empregadas pela Cloudflare. Manter-se normal na Web é extremamente difícil. Até mesmo um parâmetro alterado aleatoriamente fará com que você seja imediatamente detectado pelo software antibot. É a normalidade que você está procurando.
Outro método possível para contornar a consulta à API do Ambiente é modificar os cabeçalhos de solicitação HTTP enviados pelo cliente bot. Isso inclui a cadeia de caracteres do agente do usuário e outras informações relevantes do dispositivo. No entanto, bots sofisticados podem ter a capacidade de imitar esses cabeçalhos com precisão.
Eles são difíceis de detectar somente com essa técnica.
Tudo Importa
Em última análise, a eficácia das técnicas anti-bot da Cloudflare dependerá de quão bem elas forem implementadas e configuradas. Os proprietários de sites que usam endereços IP da Cloudflare devem se certificar de que configuraram suas medidas de segurança corretamente. Isso inclui a configuração de regras de limitação de taxa e firewall, a ativação da criptografia SSL e o monitoramento de seus registros em busca de atividades suspeitas.
Ao adotar uma abordagem proativa em relação à segurança, os proprietários de sites podem ajudar a garantir que seus sites permaneçam protegidos contra ataques de bots.
Maneira 1: contornar a CDN da Cloudflare chamando o servidor de origem
A Cloudflare oferece proteção DDos contra ataques de bots. Ele atua como um proxy entre o usuário e o servidor para ocultar o endereço de IP original.
Isso pode dificultar o acesso de scrapers da Web a dados de sites protegidos pelo Cloudflare. No entanto, há maneiras de contornar o Cloudflare chamando diretamente o servidor de origem.
Encontre o endereço de IP de origem
A primeira etapa para contornar o Cloudflare é encontrar o endereço de IP de origem do site que você deseja extrair. Normalmente, isso pode ser feito por meio de uma pesquisa de DNS no nome de domínio do site. Você pode usar o comando “nslookup” em um terminal para realizar a pesquisa de DNS. Por exemplo:
nslookup example.com
Isso retornará o endereço de IP do proxy Cloudflare do site. Encontre o endereço de IP de origem usando uma ferramenta como “ping” ou “traceroute”. Essas ferramentas determinarão o caminho de seu computador até o servidor de origem. Por exemplo:
ping example.com
Isso retornará o endereço de IP do servidor de origem.
Requisitar dados do servidor de origem
Depois de obter o endereço de IP de origem, você pode enviar requisições HTTP diretamente para o servidor de origem para contornar o Cloudflare. Você pode fazer isso usando uma ferramenta como o cURL ou escrevendo um script personalizado em Python ou em outra linguagem de programação.
Para fazer a solicitação, você precisará incluir o endereço de IP de origem no URL da sua solicitação, da seguinte forma:
http://[origin IP]/path/to/resource
Você também precisará incluir os cabeçalhos apropriados em sua solicitação, como o cabeçalho “User-Agent”. Eles ajudam a imitar o comportamento de um navegador da Web normal. Você também pode incluir outros cabeçalhos, como “Referer” e “Accept-Language”, para fazer com que sua solicitação pareça mais legítima.
Maneira 2: substituir a sala de espera do Cloudflare
Um dos recursos de segurança oferecidos pela Cloudflare é a página “sala de espera”, também conhecida como modo “Estou sob ataque”. Quando um usuário visita um site protegido pela Cloudflare, o endereço de IP do usuário é verificado primeiro pelas medidas de segurança da Cloudflare.
Se o endereço de IP for sinalizado como potencialmente prejudicial, o usuário é redirecionado para uma página de sala de espera com um desafio. O desafio normalmente envolve a solução de um CAPTCHA ou a conclusão de um desafio que exige interação humana com a página. Pode ser clicar em um elemento específico ou arrastar e soltar objetos na página.
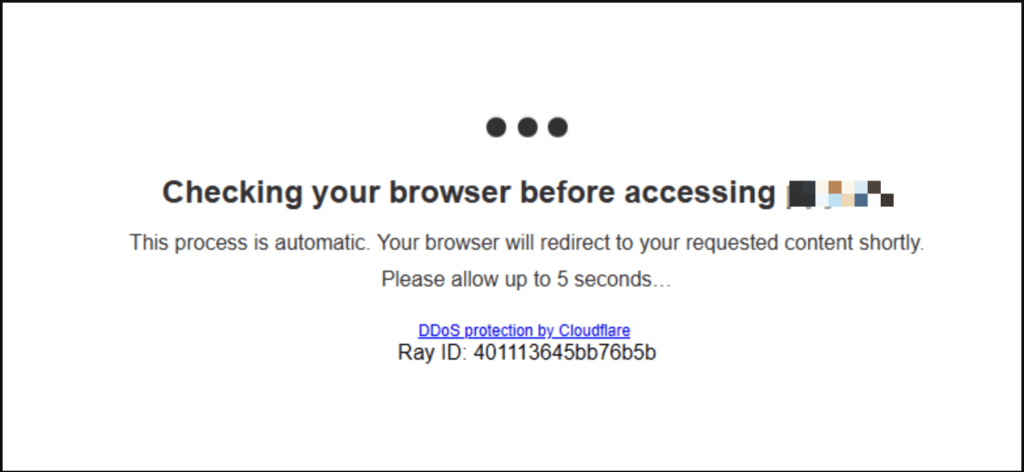 Já vimos essa tela milhares de vezes.
Já vimos essa tela milhares de vezes.
A página da sala de espera foi projetada para proteger os sites contra vários tipos de ataques. Alguns deles são ataques DDoS (Negação de Serviço Distribuído), ataques de força bruta e tentativas de web scraping. Os bots e outras ferramentas automatizadas não conseguem concluir o desafio apresentado pela página da sala de espera. Isso os impede efetivamente de acessar o site.
Para minimizar o impacto sobre os usuários legítimos, a Cloudflare permite que os proprietários de sites personalizem a página da sala de espera. Isso é feito para corresponder à marca de seu site e para ajustar a sensibilidade das medidas de segurança.
Para minimizar o impacto sobre os usuários legítimos, a Cloudflare permite que os proprietários de sites personalizem a página da sala de espera para corresponder à marca de seu site e ajustar a sensibilidade das medidas de segurança.
Quanto tempo leva para contornar a sala de espera da Cloudflare?
Os tempos podem variar de acordo com a complexidade do desafio e o nível de habilidade do usuário. Em alguns casos, a sala de espera pode ser contornada em poucos minutos. Em casos mais difíceis, pode levar várias horas ou até dias.
Os fatores que podem afetar o tempo necessário para contornar a sala de espera incluem:
- o uso de ferramentas automatizadas
- o tipo de desafio usado pela Cloudflare
- o nível das medidas de segurança implementadas pelo site que está sendo acessado.
Alguns sites podem ter medidas de segurança mais robustas, como camadas de verificação adicionais ou desafios complexos de JavaScript. Isso pode tornar o desvio mais difícil e demorado.
Desenvolvedores experientes e profissionais de segurança têm uma vantagem ao tentar contornar a sala de espera. Eles estão familiarizados com as tecnologias usadas pela Cloudflare e com as tecnologias da Web subjacentes.
Isso os ajuda a fazer isso de forma mais rápida e eficiente do que aqueles com menos experiência.
Engenharia reversa do desafio de JavaScript da Cloudflare
A engenharia reversa do desafio de JavaScript da Cloudflare pode ser uma tarefa assustadora, mas é possível com as ferramentas e técnicas certas.
Neste guia, abordaremos as etapas envolvidas na engenharia reversa do desafio de JavaScript da Cloudflare, com exemplos de código.
Etapa 1: Verificar o registro da rede
A primeira etapa é abrir o registro de rede do navegador e examinar as solicitações e respostas. Procure por solicitações que retornem um código de erro 503 ou que tenham um cookie “cf-chl-bypass”. Essas solicitações geralmente são as que acionam o desafio de JavaScript da Cloudflare.
import requests url = "https://example.com" response = requests.get(url) print(response.content)
O código envia uma requisição HTTP GET para a URL do site de destino usando a biblioteca de solicitações. O conteúdo da resposta é impresso no console com o conteúdo HTML do site e quaisquer scripts carregados.
Etapa 2: Debugar o script do desafio de JavaScript da Cloudflare
Em seguida, abra o depurador do navegador e procure o arquivo JavaScript responsável pelo desafio. Esse arquivo geralmente tem um nome como “cf_chl.js” ou “challenge.js”.
Defina um ponto de interrupção no início do script para interromper a execução e facilitar a análise.
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Add print statements to debug the JS code
def challenge_callback(solved_token):
print("Solved token:", solved_token)
context = {
"success": False,
"callback": challenge_callback
}
exec(js_code, context)
- Esse código envia uma requisição HTTP GET para a URL do site de destino usando a biblioteca requests.
- O conteúdo da resposta é analisado usando a biblioteca BeautifulSoup para encontrar a tag de script que contém o script do desafio da Cloudflare.
- A URL de origem da tag de script é extraído e outra requisição HTTP GET é enviada para recuperar o conteúdo do script.
- O conteúdo do script recuperado é executado usando a função exec. Um contexto personalizado é passado para permitir a definição de funções de retorno de chamada.
- Uma função de retorno de chamada de exemplo é definida e passada para o contexto personalizado. Ela será chamada se o desafio da Cloudflare for resolvido com êxito.
![]()
Etapa 3: Desofuscar o script do desafio de JavaScript da Cloudflare
O script do desafio de JavaScript da Cloudflare geralmente é ofuscado para impedir a engenharia reversa. Use uma ferramenta como JSNice ou Unminify para desofuscar o script e facilitar a leitura.
Como alternativa, você pode usar o beautifier de JavaScript integrado no debugger do navegador.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
def challenge_callback(solved_token):
print("Solved token:", solved_token)
context = {
"success": False,
"callback": challenge_callback
}
exec(deobfuscated_code, context)
- Esse código é o mesmo da Etapa 2 até a recuperação do conteúdo do script de desafio.
- A biblioteca jsbeautifier é usada para desobfuscar o conteúdo do script e torná-lo mais legível.
- Uma função de retorno de chamada de amostra é definida e passada para o contexto personalizado. Ela será chamada se o desafio do Cloudflare for resolvido com sucesso.
Etapa 4: Analisar o script desofuscado
Agora que o script está desofuscado, é hora de analisá-lo. Procure as funções que geram o token de desafio ou verificam a resposta.
Essas funções geralmente têm nomes como “gen_challenge” ou “verify”. Examine o script em busca de padrões ou algoritmos recorrentes. Se encontrados, eles podem ser usados para criar o token de desafio ou a resposta correta.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
script_tag = soup.find("script", {"src": "/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1"})
js_code_url = "https://example.com" + script_tag["src"]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
# Extract relevant code snippets
challenge_function = ""
challenge_callback = ""
for line in deobfuscated_code.split("
"):
if "function " in line and "challenge_" in line:
challenge_function += line + "
"
elif "success:!1," in line:
challenge_callback += line + "
"
# Create a custom environment for executing the JS code
class ChallengeEnvironment:
def __init__(self, callback):
self.callback = callback
self.success = False
def setTimeout(self, func, delay):
func()
def atob(self, str):
return bytes(str, "ascii").decode("base64")
# Execute the challenge function with the custom environment
context = ChallengeEnvironment(challenge_callback)
try:
exec(challenge_function, context.__dict__)
except Exception as e:
print("Error:", e)
if context.success:
print("Challenge solved successfully!")
else:
print("Failed to solve the challenge.")
Esse código é o mesmo da Etapa 3 até a desobfuscação do conteúdo do script de desafio.
- Os trechos de código relevantes são extraídos do script desofuscado, incluindo a função de desafio e a função de retorno de chamada de sucesso.
- Uma classe de ambiente personalizado é definida para imitar o ambiente do navegador e permitir que o script de desafio seja executado corretamente.
- A função de desafio é executada com o ambiente personalizado e todos os erros são capturados e impressos no console.
- Se a função de retorno de chamada de sucesso for chamada com o sinalizador de sucesso definido como True, então o desafio do Cloudflare foi resolvido com sucesso.
Maneira 3: Usar os solucionadores da Cloudflare
A eficácia dos solucionadores de código aberto da Cloudflare pode variar de acordo com o desafio específico apresentado pela Cloudflare. Em geral, alguns solucionadores são mais eficazes do que outros na solução de diferentes tipos de desafios.
Por exemplo, Cfscrape e cloudscraper são duas bibliotecas de Python populares que podem ser eficazes na solução de desafios básicos de JavaScript. Ambas utilizam navegadores headless para imitar a interação de um usuário com a página de desafio de ddos da Cloudflare. Os desafios simples geralmente podem ser resolvidos com facilidade.
O FlareSolverr abre um navegador headless, fornecendo ao usuário os cookies e outros dados necessários para resolver o desafio. Essa abordagem pode ser mais eficaz na solução de desafios mais complexos. Aqui, o usuário interage com a página do desafio de uma maneira mais realista.
 FlareSolverr
FlareSolverr
cloudflare-scrape e cloudflare-iuam-solver são duas outras bibliotecas de Python que utilizam navegadores headless para resolver os desafios da Cloudflare. Embora sejam menos populares do que alguns dos outros solucionadores, elas ainda podem ser eficazes na solução de desafios simples.
Por fim, o CloudflareSolverRe é um solucionador mais recente que funciona analisando a página de desafio da Cloudflare. Ele gera automaticamente uma solução usando expressões regulares. Essa abordagem pode ser altamente eficaz na solução de desafios simples.
Desafios mais complexos, que exigem soluções com mais nuances, podem ser difíceis.
Maneira 4: Aproveitar os navegadores headless
Os navegadores headless imitam o comportamento real do usuário em um navegador normal. Eles permitem que o usuário execute JavaScript, manipule cookies e interaja com o site como um usuário normal faria. Isso torna mais difícil para a Cloudflare detectar e bloquear o tráfego automatizado. Nesse caso, o tráfego parece vir de um usuário legítimo e não de um bot.
Um navegador headless popular para contornar a Cloudflare é o Puppeteer, uma biblioteca do Node.js que fornece uma API de alto nível para controlar o navegador Chrome headless. O Puppeteer pode ser usado para acessar dados da Web protegidos pela Cloudflare. Ele pode resolver o desafio com JavaScript e extrair os cookies necessários para evitar desafios futuros.
Outra opção é o Selenium, um framework amplamente utilizado para automatizar navegadores da Web. O Selenium pode ser usado para controlar versões headless de navegadores populares, como o Chrome e o Firefox, e pode interagir com sites de uma forma que imita de perto o comportamento de um usuário humano.
Para tarefas mais complicadas que exigem impressão digital do navegador, o GoLogin pode ser usado. Originalmente um navegador de privacidade, ele é amplamente usado para scraping no modo headless. O GoLogin gerencia as impressões digitais do navegador com uma solução personalizada.
Múltiplos perfis de navegador podem ser executados em uma máquina, todos com aparência única e normal até mesmo para os sites mais avançados.
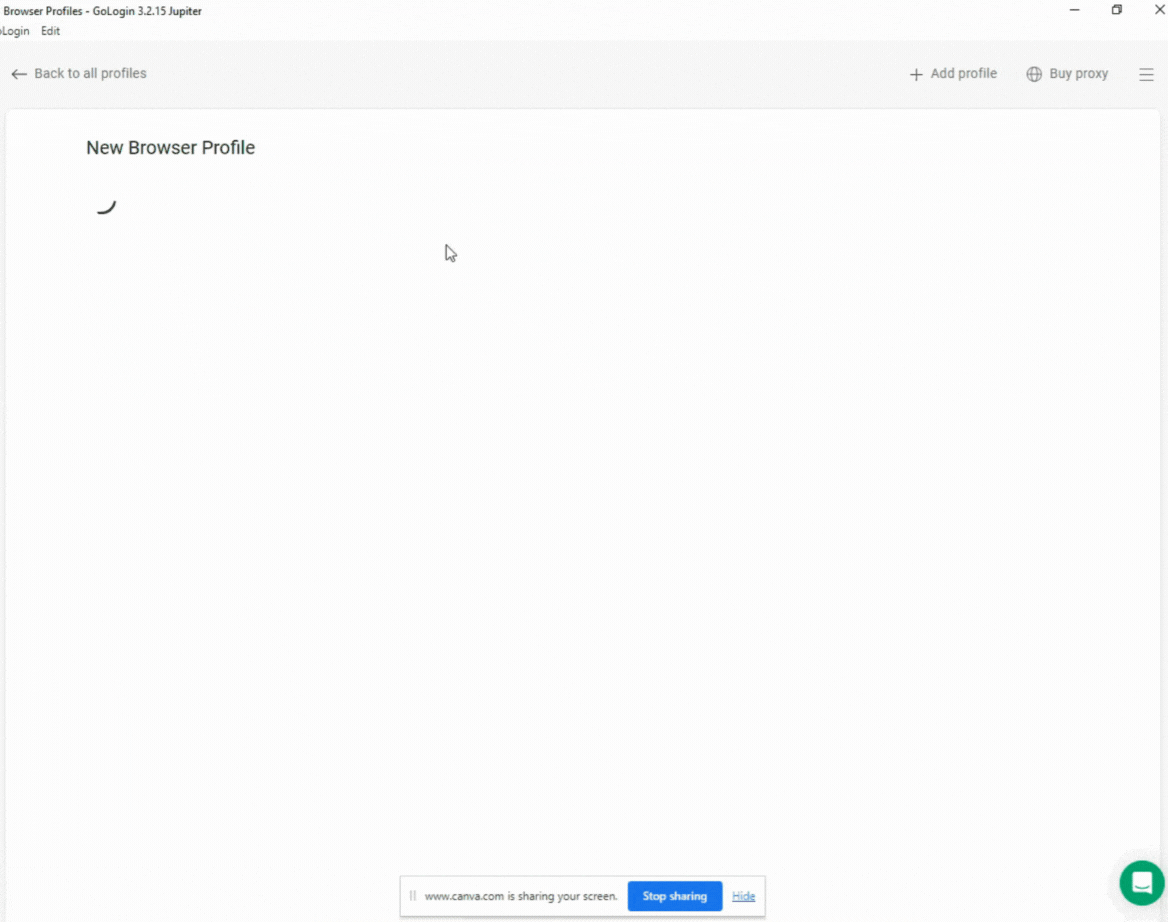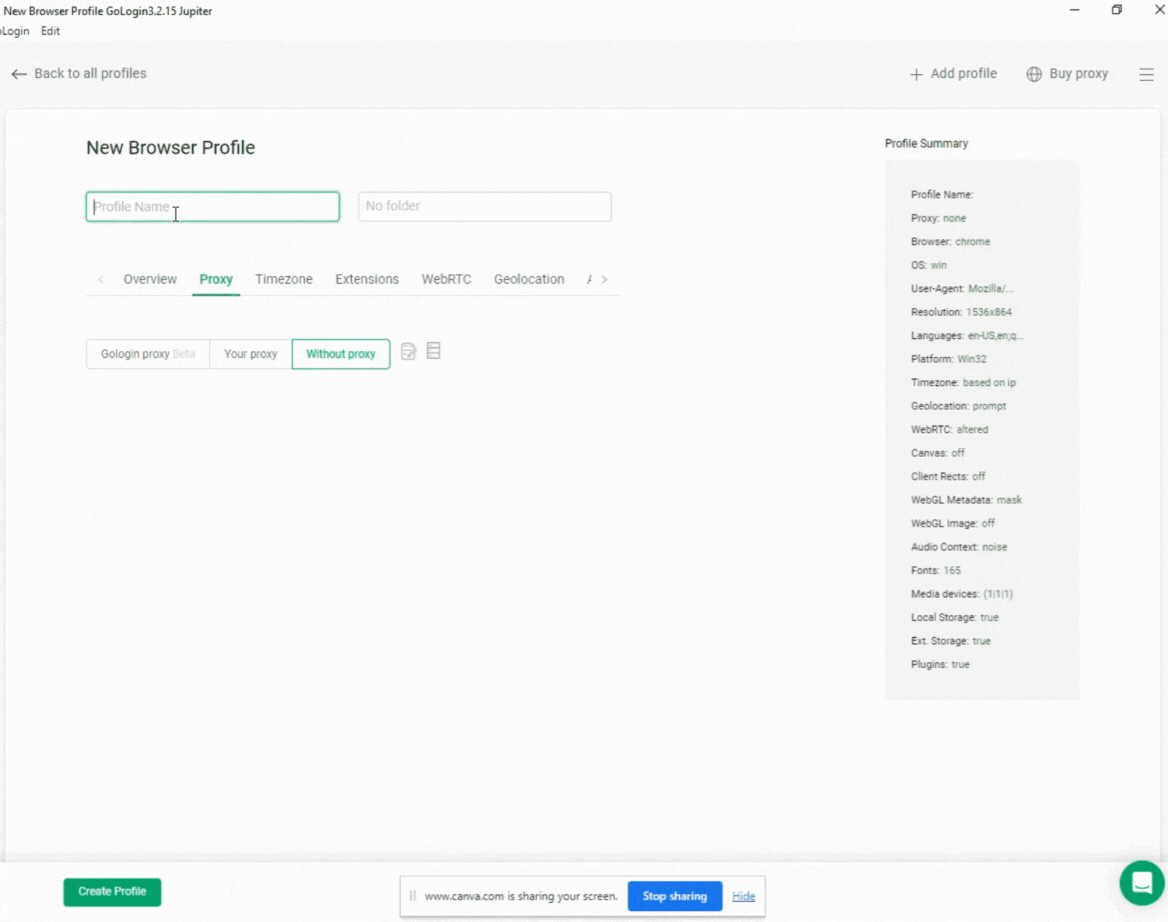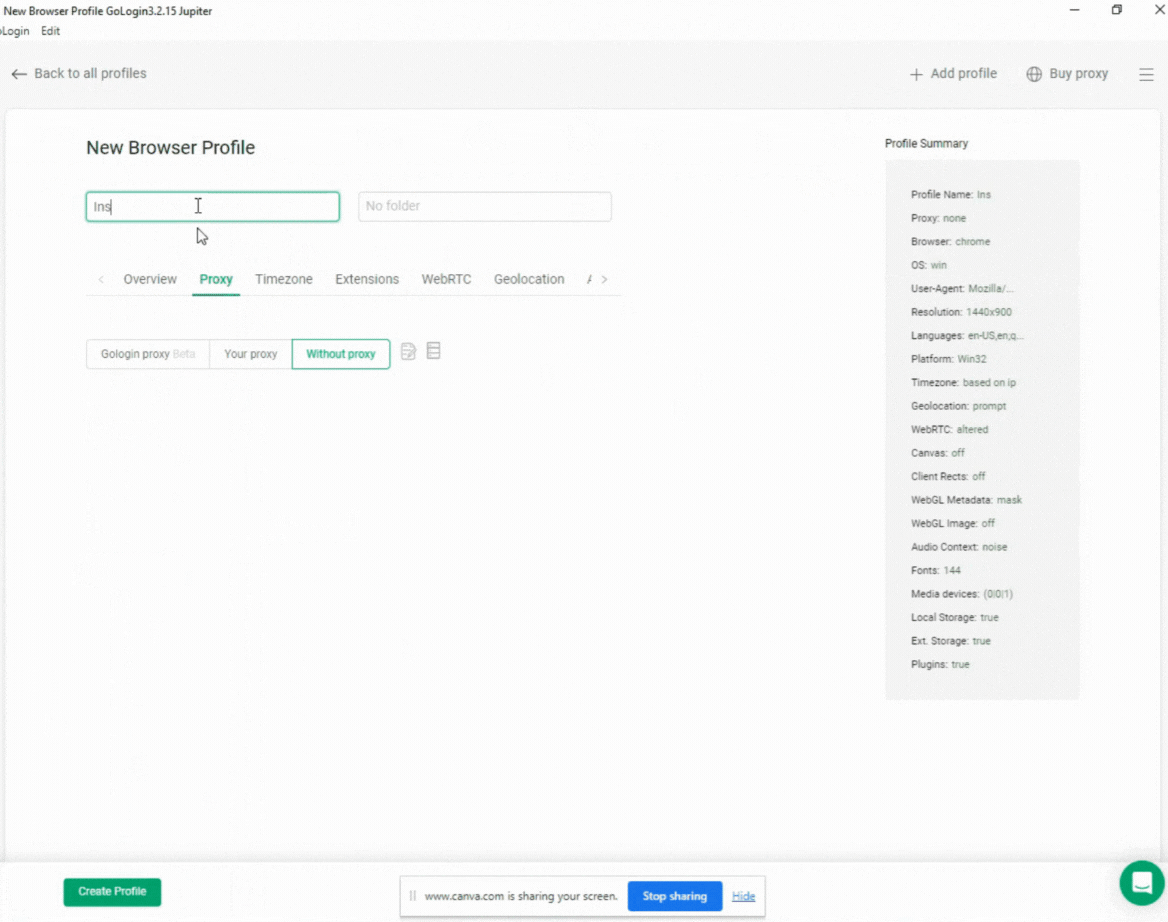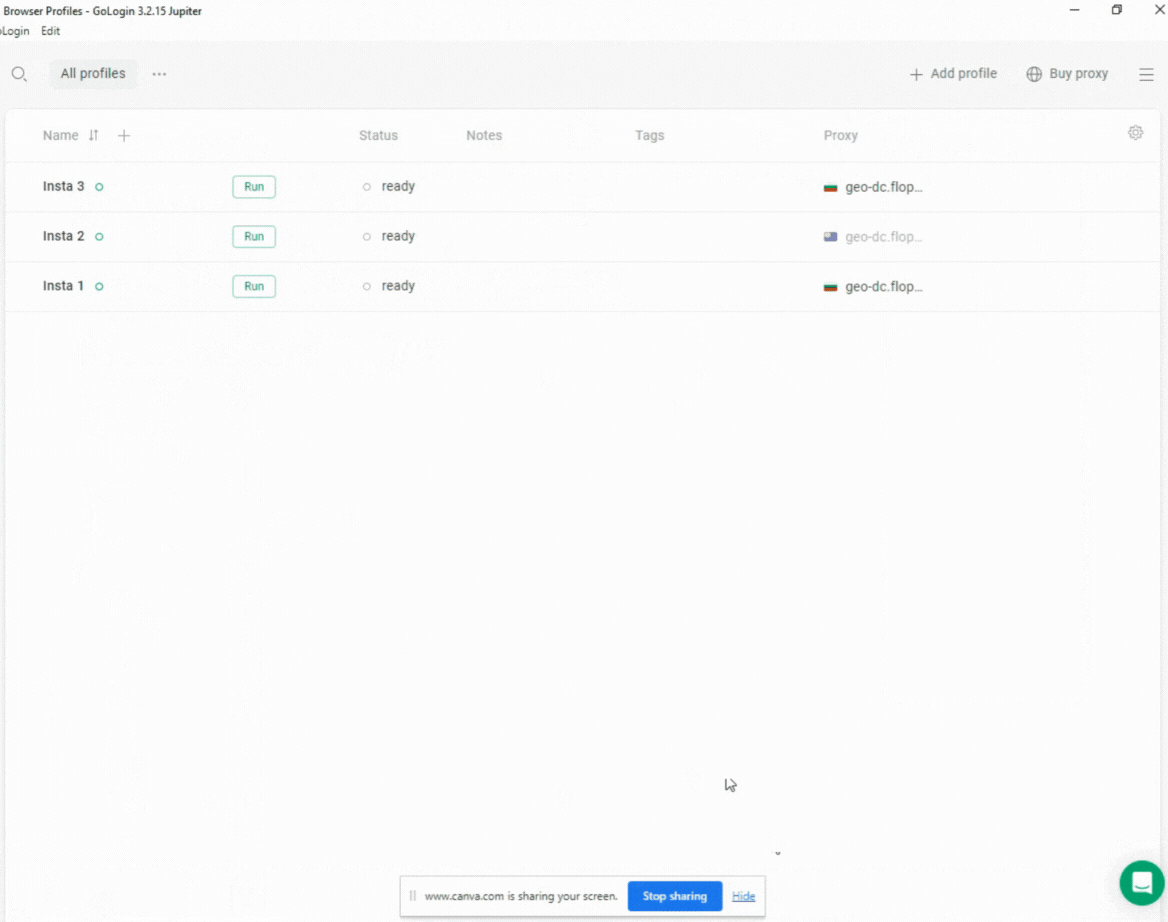 Configurar um perfil do navegador no GoLogin
Configurar um perfil do navegador no GoLogin
Navegadores headless: prós e contras
Uma possível desvantagem do uso de navegadores headless é que eles exigem mais recursos do que soluções mais simples, como os solucionadores da Cloudflare. A execução de um navegador headless pode consumir muita memória e tornar o processo de scraping mais lento. Isso é particularmente observado quando se lida com grandes quantidades de dados.
Outra limitação é que os navegadores headless podem ser mais complexos de configurar e usar do que outras soluções. Eles exigem conhecimento de programação e desenvolvimento da Web e podem ser mais difíceis de usar para usuários não técnicos. No entanto, é provável que você tenha experiência em tecnologia se já estiver enfrentando o desafio de extrair dados de um site altamente protegido.
Os navegadores headless podem ser uma ferramenta extremamente eficaz para contornar a Cloudflare. É importante pesar os prós e os contras do uso de navegadores headless em relação a outras soluções e considerar fatores:
- a quantidade de dados que estão sendo extraídos
- o nível geral de proteção do site
- a proficiência técnica do usuário
- os recursos disponíveis para executar navegadores headless.
Maneira 5: Utilizar um proxy inteligente para burlar a Cloudflare
As APIs de proxy inteligente são outra maneira eficaz de contornar os mecanismos de proteção da Cloudflare. As APIs de proxy inteligente são projetadas para rotear o tráfego HTTP por meio de um pool de endereços de IP residenciais reais. Isso torna mais difícil para os sites detectarem e bloquearem o tráfego automatizado.
Essas APIs funcionam fornecendo acesso a um grande pool de endereços de IP residenciais reais. A API envia requisições para esses endereços de IP, mascarando efetivamente a origem das requisições. Isso torna mais difícil para a Cloudflare identificar e bloquear o tráfego automatizado.
Exemplos
Uma API de proxy inteligente popular é a API de proxies residenciais da Oxylabs. Essa API fornece acesso a um pool de mais de 100 milhões de proxies residenciais. Isso torna a Oxylabs uma das maiores APIs de proxy inteligente disponíveis. A API foi projetada para ser fácil de usar, com excelente documentação e suporte para linguagens populares como Python e Node.js.
Para usar a API Residential Proxies da Oxylabs, primeiro você precisa se inscrever em uma conta e obter uma chave de API. Depois de obter uma chave de API, você poderá usá-la para fazer requisições HTTP por meio da API. A API encaminhará suas solicitações por meio de um pool de endereços de IP residenciais. Isso torna mais difícil para a Cloudflare detectar e bloquear suas requisições.
Outra API de proxy inteligente popular é a Luminati Proxy API. Essa API fornece acesso a um conjunto de mais de 72 milhões de proxies residenciais. Há também uma série de outros recursos, como segmentação geográfica e impressão digital do navegador. A API foi projetada para ser flexível e facilmente personalizada, com suporte para uma ampla gama de casos de uso.
Em alguns casos, as APIs de proxy inteligente são uma maneira eficaz de contornar os mecanismos de proteção de proxy da Cloudflare. Ao rotear solicitações por meio de um pool de endereços de IP residenciais reais, essas APIs podem ajudá-lo a evitar a detecção.
Maneira 6: Extrair o cache do Google
A extração do cache do Google é outra técnica que pode ser usada para contornar a Cloudflare. O cache do Google é um instantâneo de um site obtido pelo rastreador da Web do Google e armazenado em seu cache.
Ao acessar um site por meio do cache do Google, a requisição é direcionada para os servidores do Google em vez do site real. Isso pode ajudar a contornar a proteção da Cloudflare.
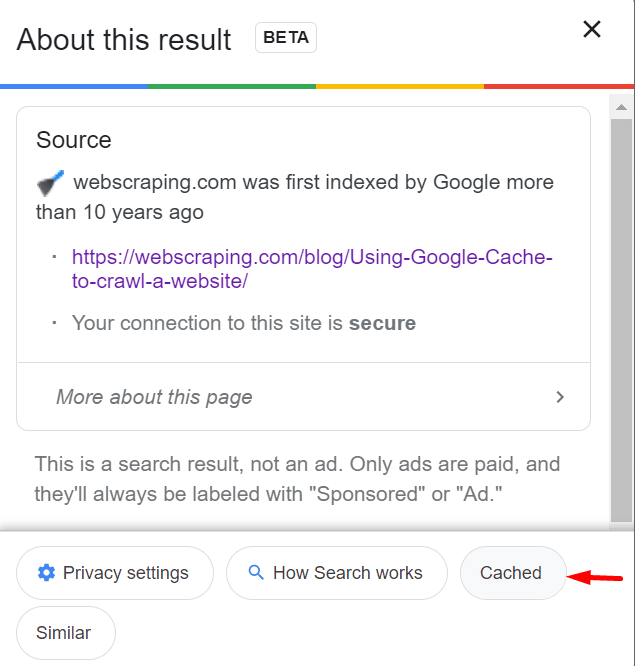 Fonte: ProxyScrape
Fonte: ProxyScrape
Portanto, comece com uma simples pesquisa no Google: veja se o site que você está extraindo tem uma versão em cache. Você precisa usar uma consulta de pesquisa que inclua o prefixo “cache” seguido da URL que deseja acessar.
Isso exibirá a versão em cache do site nos resultados da pesquisa – clique no link “Cached” para acessar. Essa mesma URL (sem a marca “cache:”) pode funcionar para scraping.
No entanto, é importante observar que o cache do Google pode nem sempre ter a versão mais atualizada do site. Alguns elementos, como imagens, podem não ser exibidos corretamente. Além disso, o Google pode bloquear ou limitar o acesso ao seu cache se detectar scraping excessivo ou padrões de tráfego incomuns.
Maneira 7: Contornar o CAPTCHA da Cloudflare
Os serviços de solução de Captcha também podem ser usados para contornar os desafios de JavaScript da Cloudflare. Essa é uma das maneiras mais caras de fazer o trabalho (especialmente para tarefas de maior volume). Entretanto, às vezes é a única maneira que realmente funciona.
Serviços como o 2Captcha usam humanos reais para resolver captchas de forma rápida e eficiente. Muitos deles têm APIs que podem ser integradas a scripts ou programas. Basta registrar-se em uma conta e obter uma chave de API.
Em seguida, você pode usar a API para enviar um desafio de captcha e receber uma resposta que contenha o captcha resolvido.
 2Captcha
2Captcha
Para contornar os desafios de JavaScript da Cloudflare, é necessário capturar o desafio. Depois disso, envie-o para a API do serviço de solução de captcha. O serviço retornará o desafio resolvido, que poderá ser usado para contornar o desafio e acessar o site protegido.
É importante observar que o uso de um serviço de solução de captcha nem sempre é confiável. O serviço pode não ser capaz de resolver determinados tipos de captchas ou pode levar mais tempo para resolvê-los.
Maneira 8: Navegadores de Privacidade para Proteção de Web Scraping
Tentei trabalhar com o Playwright em diferentes navegadores e contextos, bem como em vários provedores de nuvem – sem sucesso algum. Então, decidi experimentar o Playwright em um navegador antidetecção.
O Que São Navegadores de Privacidade?
Os navegadores de privacidade (também chamados de navegadores de múltiplas contas ou antidetecção) geralmente são baseados no Chromium, mas com recursos que aumentam a privacidade do usuário. Normalmente, eles criam novas impressões digitais que parecem autênticas para os sites, protegendo a localização real do usuário. Essa é a principal diferença em relação a uma execução clássica do Playwright ou do Selenium.
Vou colocar isso em palavras mais simples. Usando o Playwright no Chrome, o servidor sabe que você está usando uma versão genuína do Chrome. Ele está sendo executado em uma máquina do Datacenter – por causa da impressão digital do dispositivo. Com um navegador de privacidade, você está usando uma versão do Chromium configurada para o máximo de privacidade.
Ele configura um perfil de conexão sofisticado que envia impressões digitais personalizadas do dispositivo. Assim, até mesmo os mecanismos de site mais avançados veem que você está executando o navegador a partir de um Mac comum. O fato de que você está realmente executando a partir de um servidor não é visto. Assim, seu trabalho fica protegido.
GoLogin
Eu precisava testar se essa solução poderia funcionar. Entre os vários navegadores disponíveis, tive que escolher um com as seguintes especificações:
- Tem uma demonstração gratuita totalmente funcional para testar minha solução
- Pode ser rapidamente integrada ao Playwright, minimizando o impacto em meu ambiente de produção
- Tem um cliente Unix para meu ambiente de produção.
Considerando que, tecnicamente, qualquer navegador baseado em chromium pode ser executado com o Playwright se o executable_path for especificado da seguinte maneira:
browser = playwrights.chromium.launch(executable_path='/opt/path_to_bin')
Escolhi o serviço de web scraping GoLogin por causa de todos os recursos acima. Também considerei o fato de poder criar perfis diferentes (cada um com impressões digitais diferentes), que poderiam ser usados em meus experimentos.
A Configuração
Depois de me registrar, criei meu primeiro perfil que imita uma estação de trabalho do Windows. Em seguida, baixei o cliente do navegador e o código-fonte python do seu repositório. Ele é necessário para interagir com o Playwright usando sua API.
Usando os testes no amiunique.org podemos ver as diferenças entre o Playwright Chrome do meu notebook Mac e aquele com um perfil GoLogin.
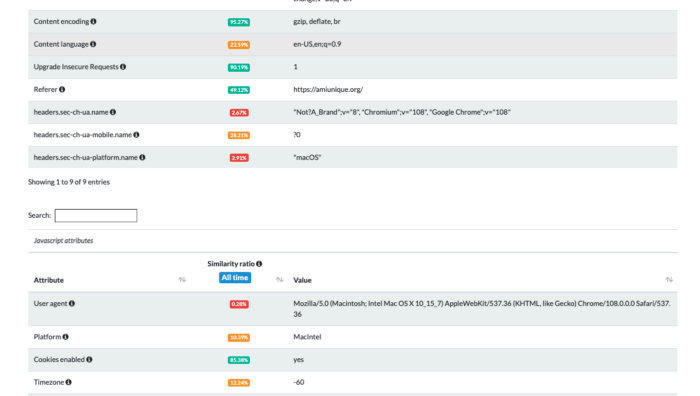
No primeiro caso, podemos ver a plataforma Macintel e os cabeçalhos do macOS, que poderiam ser facilmente alterados de qualquer forma.
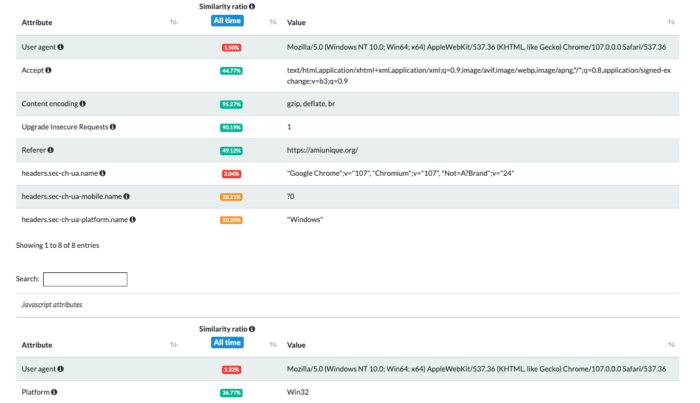
Usando o Gologin, estou imitando a execução de uma máquina Windows.
Dicas finais sobre como contornar a detecção passiva e ativa de bots da Cloudflare
Essas são algumas dicas gerais para casos em que nada funciona. Há ocasiões em que você está simplesmente experimentando novas formas e combinando as existentes.
Como Burlar a Detecção Passiva de Bots da Cloudflare
- Desativar o JavaScript: impede que a Cloudflare colete essas informações e contornar esse mecanismo de detecção. No entanto, isso pode não ser adequado para todos os casos de uso, pois alguns sites dependem muito do JavaScript para sua funcionalidade.
- Usar um Proxy com Renderização de JavaScript: a detecção passiva de bots da Cloudflare também pode identificar bots que não executam JavaScript. Ao usar um serviço de proxy que ofereça suporte à renderização de JavaScript, você pode contornar esse mecanismo de detecção. Um serviço de proxy compatível com a renderização de JavaScript o executará no servidor e retornará a página para o cliente.
- Usar um Framework de Web Scraping: a detecção passiva da Cloudflare também pode identificar bots que não se comportam como um usuário real. Ao usar uma estrutura de web scraping que possa imitar o comportamento de um usuário real, você pode contornar esse mecanismo de detecção.
Como Burlar a Detecção de Bots Ativa da Cloudflare:
- Alterar o Agente de Usuário: ao alterar a cadeia de caracteres do agente do usuário para imitar um navegador, é possível ignorar esse mecanismo de detecção. Você pode usar a extensão User-Agent Switcher para Chrome ou Firefox para alternar rapidamente entre as cadeias de caracteres de agente de usuário.
- Alternar os Endereços de IP: a detecção ativa de bots da Cloudflare também pode identificar bots com base em seus endereços de IP. Ao alternar seus endereços de IP, você pode contornar esse mecanismo de detecção. Você pode usar um serviço de proxy ou uma VPN para alternar seus endereços de IP. A rede Tor é outra opção, mas pode não ser adequada para todos os casos de uso.
- Usar um Navegador Headless: a detecção ativa de bots da Cloudflare também pode identificar bots com base em seu comportamento de navegação. Ao usar um navegador headless, você pode imitar o comportamento de navegação de um usuário real e contornar esse mecanismo de detecção.
Os navegadores headless são navegadores automatizados que podem ser controlados por meio de uma interface de programação. Alguns navegadores headless populares incluem Puppeteer, Selenium, GoLogin e Playwright.
Recapitulação com Perguntas Frequentes
- Que atividade é considerada suspeita pela Cloudflare?
A Cloudflare considera atividades como taxa de requisições excessiva, acesso a recursos que não existem, requisições de endereços de IP na lista de bloqueios. Muitos outros padrões são considerados suspeitos por seus algoritmos como possíveis atividades de bots. - Qual é o método mais comum para contornar a Cloudflare?
Não existe uma resposta única para essa pergunta. Ela depende das proteções específicas da Cloudflare em vigor e dos recursos e objetivos do invasor. Alguns métodos comumente usados incluem solvers, navegadores headless, como o Puppeteer, e o uso de proxies ou APIs de proxy inteligente. - É possível burlar a Cloudflare?
Sim! Use combinações de diferentes métodos: usando solucionadores, navegadores headless, serviços de captcha, APIs de proxy inteligente, scraping do cache do Google, etc. - Como burlar a fila do Cloudflare?
A fila do Cloudflare, também conhecida como “modo de ataque”, protege os websites de tráfego malicioso. Burlar essa fila requer encontrar vulnerabilidades na implementação do site ou usar técnicas como limitação de taxa. No entanto, tentar burlar a fila é antiético e pode ser ilegal. - Como burlar o JavaScript do Cloudflare?
Burlar o desafio de JavaScript do Cloudflare pode ser desafiador, pois ele verifica as interações do usuário. Algumas técnicas envolvem analisar e imitar a execução do código JavaScript, mas esses métodos podem violar os termos de serviço e não devem ser tentados sem autorização adequada.
Burlar o Cloudflare para scraping pode ser bastante difícil. Seu sistema evolui o tempo todo e não há uma solução simples contra ele.
No entanto, sempre há uma chave de ouro até mesmo para a fechadura mais forte que existe. O web scraping é uma ferramenta extremamente poderosa. É importante usá-la de forma ética e com respeito aos sites que você extrai.
Você nunca deve coletar mais dados do que precisa. Com isso em mente, boa coleta de dados! Não desista de seus projetos de scraping, esteja pronto para aprender, busque novos insights – e você alcançará o sucesso!
Faça o download do GoLogin aqui and e explore com nosso plano gratuito!
Parte deste artigo foi gentilmente cedida por Pierluigi Vinciguerra, especialista em web scraping e fundador do Web Scraping Club. Entre neste link para ver a publicação original.
Ler também: Web Scraping Tools and Services: A Comprehensive Review

